 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSim2Act: Robust Simulation-to-Decision Learning via Adversarial Calibration and Group-Relative Perturbation
Mar 10, 2026Simulation-to-decision learning enables safe policy training in digital environments without risking real-world deployment, and has become essential in mission-critical domains such as supply chains and industrial systems. However, simulators learned from noisy or biased real-world data often exhibit prediction errors in decision-critical regions, leading to unstable action ranking and unreliable policies. Existing approaches either focus on improving average simulation fidelity or adopt conservative regularization, which may cause policy collapse by discarding high-risk high-reward actions. We propose Sim2Act, a robust simulation-to-decision framework that addresses both simulator and policy robustness. First, we introduce an adversarial calibration mechanism that re-weights simulation errors in decision-critical state-action pairs to align surrogate fidelity with downstream decision impact. Second, we develop a group-relative perturbation strategy that stabilizes policy learning under simulator uncertainty without enforcing overly pessimistic constraints. Extensive experiments on multiple supply chain benchmarks demonstrate improved simulation robustness and more stable decision performance under structured and unstructured perturbations.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Knowledge Graph Question Answering for Materials Science (KGQA4MAT): Developing Natural Language Interface for Metal-Organic Frameworks Knowledge Graph (MOF-KG)
Sep 20, 2023We present a comprehensive benchmark dataset for Knowledge Graph Question Answering in Materials Science (KGQA4MAT), with a focus on metal-organic frameworks (MOFs). A knowledge graph for metal-organic frameworks (MOF-KG) has been constructed by integrating structured databases and knowledge extracted from the literature. To enhance MOF-KG accessibility for domain experts, we aim to develop a natural language interface for querying the knowledge graph. We have developed a benchmark comprised of 161 complex questions involving comparison, aggregation, and complicated graph structures. Each question is rephrased in three additional variations, resulting in 644 questions and 161 KG queries. To evaluate the benchmark, we have developed a systematic approach for utilizing ChatGPT to translate natural language questions into formal KG queries. We also apply the approach to the well-known QALD-9 dataset, demonstrating ChatGPT's potential in addressing KGQA issues for different platforms and query languages. The benchmark and the proposed approach aim to stimulate further research and development of user-friendly and efficient interfaces for querying domain-specific materials science knowledge graphs, thereby accelerating the discovery of novel materials.
Building Open Knowledge Graph for Metal-Organic Frameworks (MOF-KG): Challenges and Case Studies
Jul 10, 2022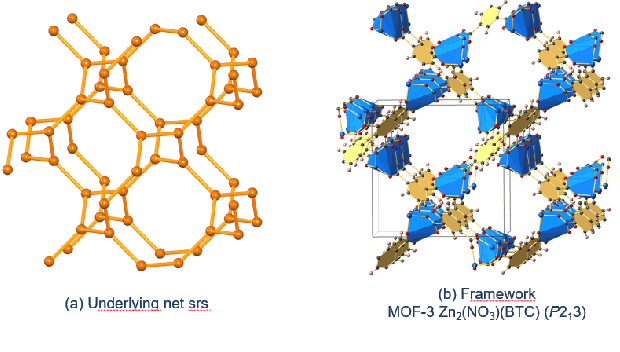
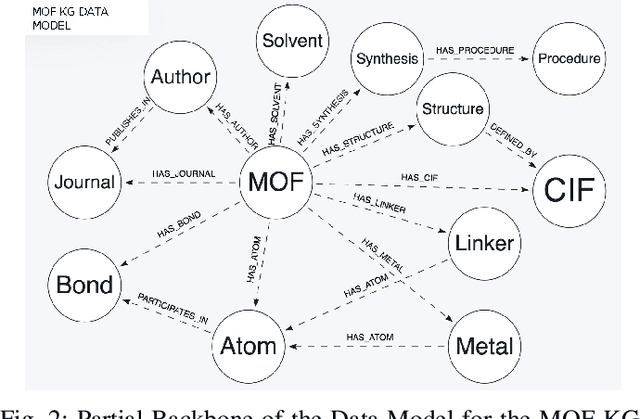
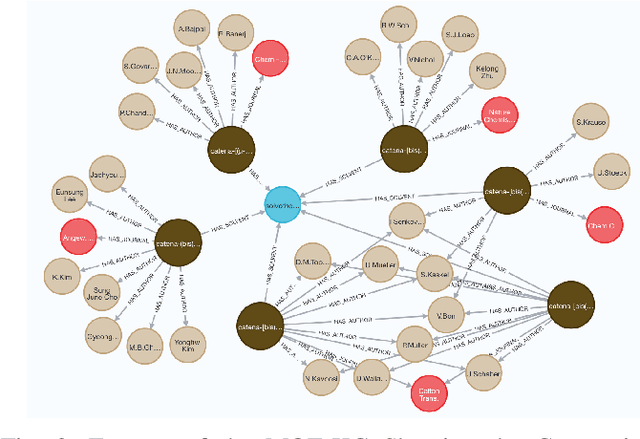
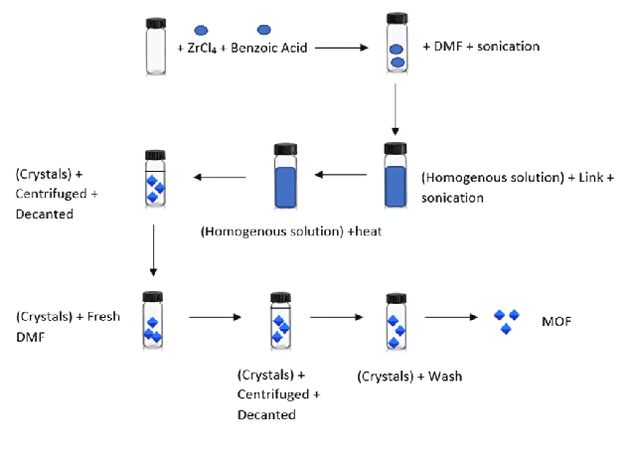
Metal-Organic Frameworks (MOFs) are a class of modular, porous crystalline materials that have great potential to revolutionize applications such as gas storage, molecular separations, chemical sensing, catalysis, and drug delivery. The Cambridge Structural Database (CSD) reports 10,636 synthesized MOF crystals which in addition contains ca. 114,373 MOF-like structures. The sheer number of synthesized (plus potentially synthesizable) MOF structures requires researchers pursue computational techniques to screen and isolate MOF candidates. In this demo paper, we describe our effort on leveraging knowledge graph methods to facilitate MOF prediction, discovery, and synthesis. We present challenges and case studies about (1) construction of a MOF knowledge graph (MOF-KG) from structured and unstructured sources and (2) leveraging the MOF-KG for discovery of new or missing knowledge.
Text to Insight: Accelerating Organic Materials Knowledge Extraction via Deep Learning
Sep 27, 2021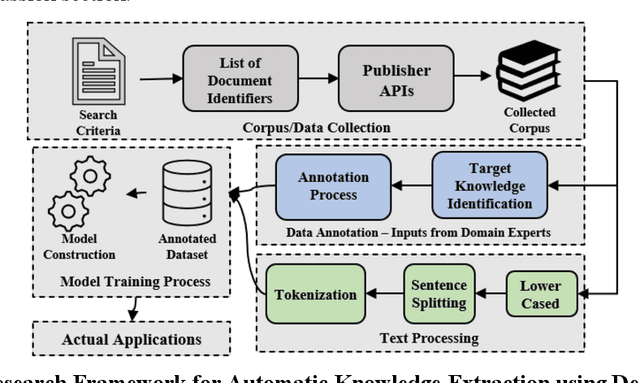

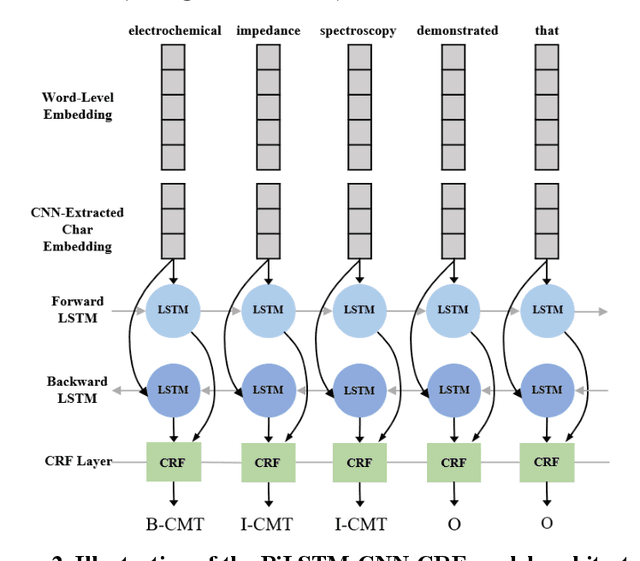
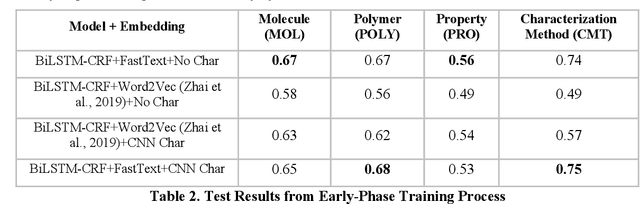
Scientific literature is one of the most significant resources for sharing knowledge. Researchers turn to scientific literature as a first step in designing an experiment. Given the extensive and growing volume of literature, the common approach of reading and manually extracting knowledge is too time consuming, creating a bottleneck in the research cycle. This challenge spans nearly every scientific domain. For the materials science, experimental data distributed across millions of publications are extremely helpful for predicting materials properties and the design of novel materials. However, only recently researchers have explored computational approaches for knowledge extraction primarily for inorganic materials. This study aims to explore knowledge extraction for organic materials. We built a research dataset composed of 855 annotated and 708,376 unannotated sentences drawn from 92,667 abstracts. We used named-entity-recognition (NER) with BiLSTM-CNN-CRF deep learning model to automatically extract key knowledge from literature. Early-phase results show a high potential for automated knowledge extraction. The paper presents our findings and a framework for supervised knowledge extraction that can be adapted to other scientific domains.
Neural Stochastic Block Model & Scalable Community-Based Graph Learning
May 16, 2020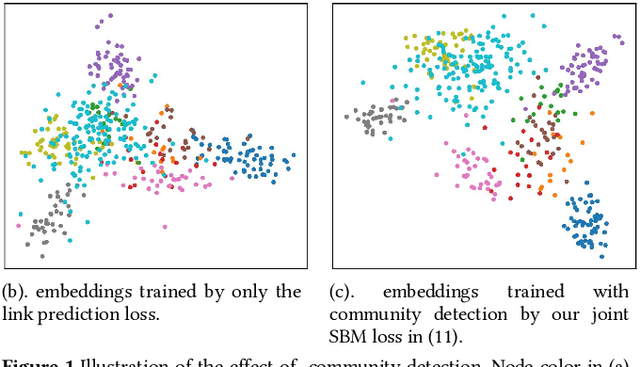
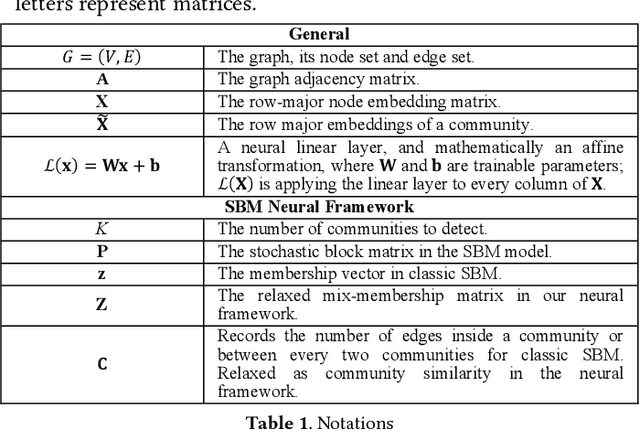
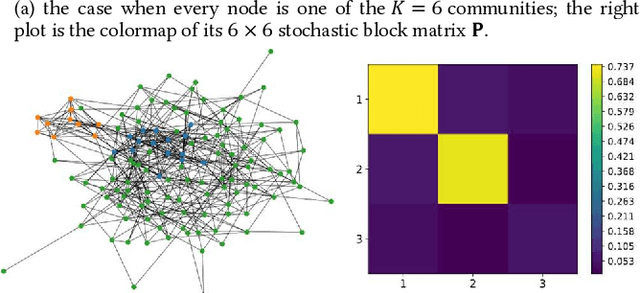
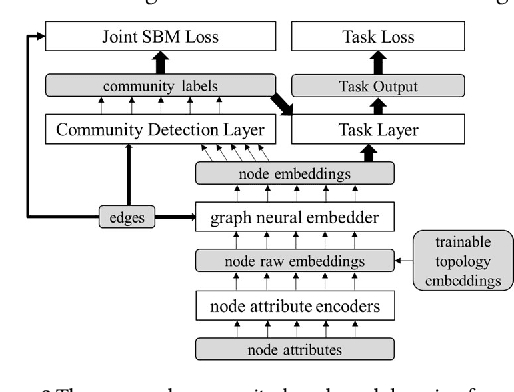
This paper proposes a novel scalable community-based neural framework for graph learning. The framework learns the graph topology through the task of community detection and link prediction by optimizing with our proposed joint SBM loss function, which results from a non-trivial adaptation of the likelihood function of the classic Stochastic Block Model (SBM). Compared with SBM, our framework is flexible, naturally allows soft labels and digestion of complex node attributes. The main goal is efficient valuation of complex graph data, therefore our design carefully aims at accommodating large data, and ensures there is a single forward pass for efficient evaluation. For large graph, it remains an open problem of how to efficiently leverage its underlying structure for various graph learning tasks. Previously it can be heavy work. With our community-based framework, this becomes less difficult and allows the task models to basically plug-in-and-play and perform joint training. We currently look into two particular applications, the graph alignment and the anomalous correlation detection, and discuss how to make use of our framework to tackle both problems. Extensive experiments are conducted to demonstrate the effectiveness of our approach. We also contributed tweaks of classic techniques which we find helpful for performance and scalability. For example, 1) the GAT+, an improved design of GAT (Graph Attention Network), the scaled-cosine similarity, and a unified implementation of the convolution/attention based and the random-walk based neural graph models.
Large-Scale Joint Topic, Sentiment & User Preference Analysis for Online Reviews
Jan 14, 2019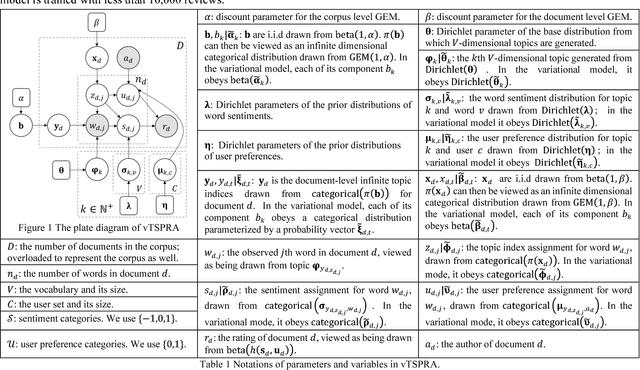
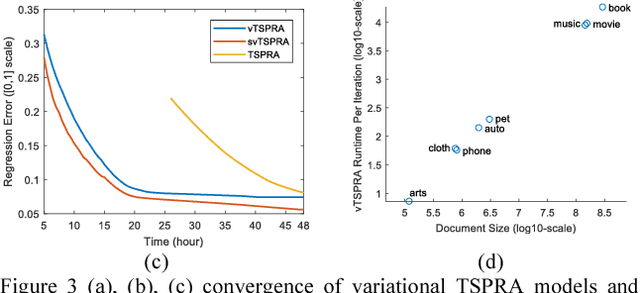
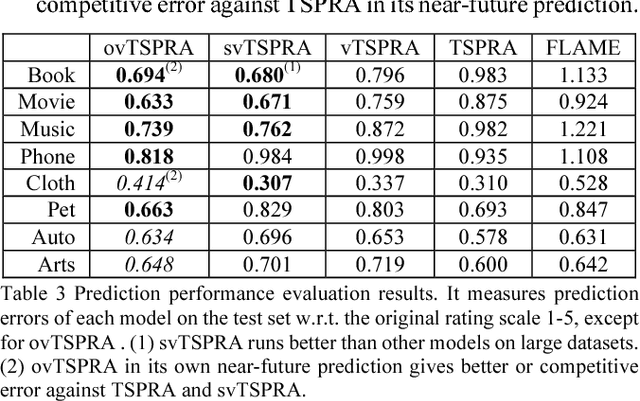
This paper presents a non-trivial reconstruction of a previous joint topic-sentiment-preference review model TSPRA with stick-breaking representation under the framework of variational inference (VI) and stochastic variational inference (SVI). TSPRA is a Gibbs Sampling based model that solves topics, word sentiments and user preferences altogether and has been shown to achieve good performance, but for large data set it can only learn from a relatively small sample. We develop the variational models vTSPRA and svTSPRA to improve the time use, and our new approach is capable of processing millions of reviews. We rebuild the generative process, improve the rating regression, solve and present the coordinate-ascent updates of variational parameters, and show the time complexity of each iteration is theoretically linear to the corpus size, and the experiments on Amazon data sets show it converges faster than TSPRA and attains better results given the same amount of time. In addition, we tune svTSPRA into an online algorithm ovTSPRA that can monitor oscillations of sentiment and preference overtime. Some interesting fluctuations are captured and possible explanations are provided. The results give strong visual evidence that user preference is better treated as an independent factor from sentiment.
Correlated Anomaly Detection from Large Streaming Data
Jan 14, 2019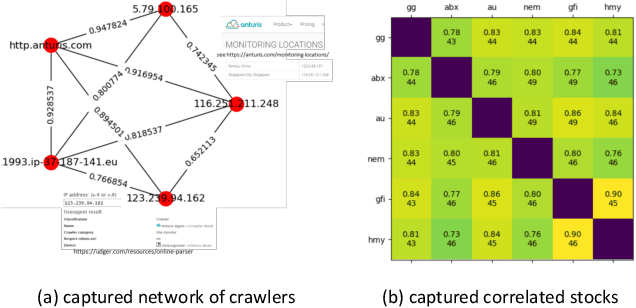
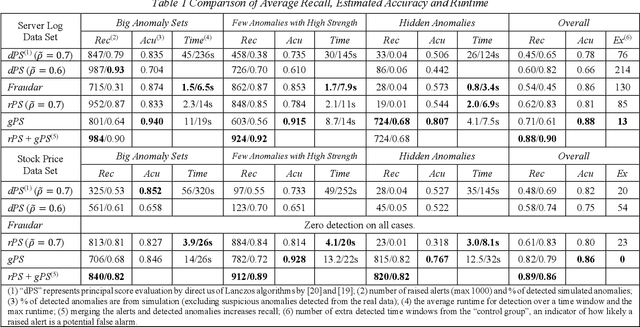
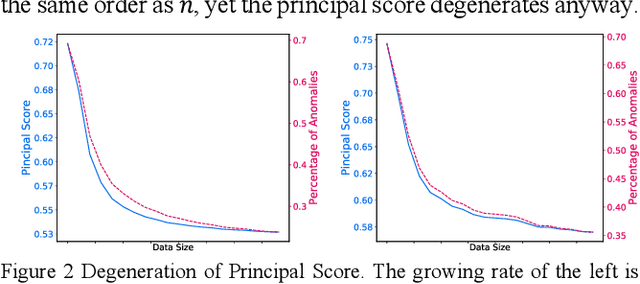
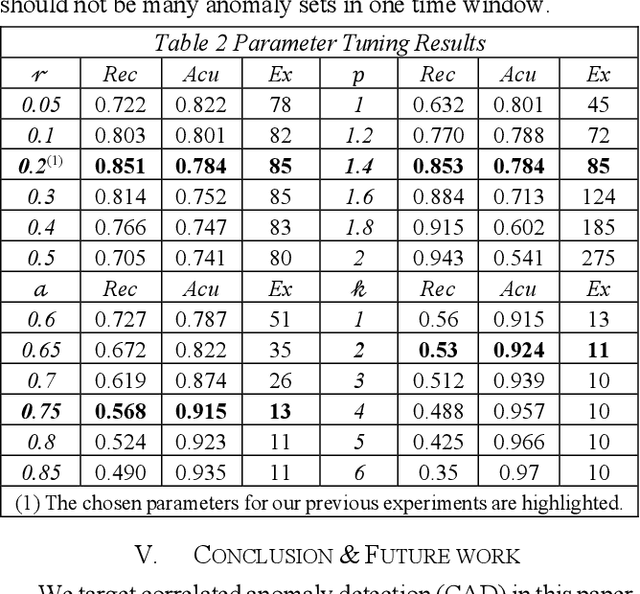
Correlated anomaly detection (CAD) from streaming data is a type of group anomaly detection and an essential task in useful real-time data mining applications like botnet detection, financial event detection, industrial process monitor, etc. The primary approach for this type of detection in previous researches is based on principal score (PS) of divided batches or sliding windows by computing top eigenvalues of the correlation matrix, e.g. the Lanczos algorithm. However, this paper brings up the phenomenon of principal score degeneration for large data set, and then mathematically and practically prove current PS-based methods are likely to fail for CAD on large-scale streaming data even if the number of correlated anomalies grows with the data size at a reasonable rate; in reality, anomalies tend to be the minority of the data, and this issue can be more serious. We propose a framework with two novel randomized algorithms rPS and gPS for better detection of correlated anomalies from large streaming data of various correlation strength. The experiment shows high and balanced recall and estimated accuracy of our framework for anomaly detection from a large server log data set and a U.S. stock daily price data set in comparison to direct principal score evaluation and some other recent group anomaly detection algorithms. Moreover, our techniques significantly improve the computation efficiency and scalability for principal score calculation.
Fast Botnet Detection From Streaming Logs Using Online Lanczos Method
Dec 19, 2018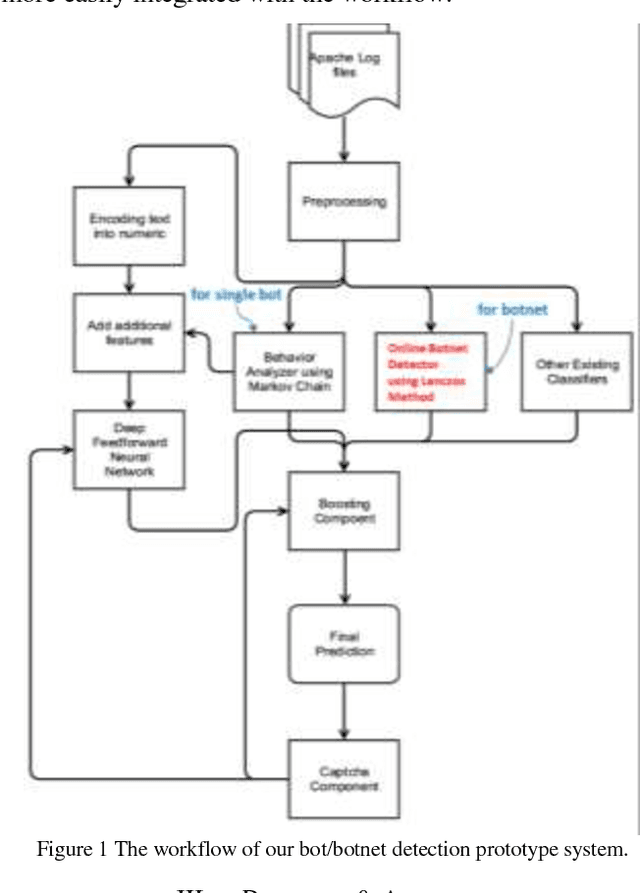
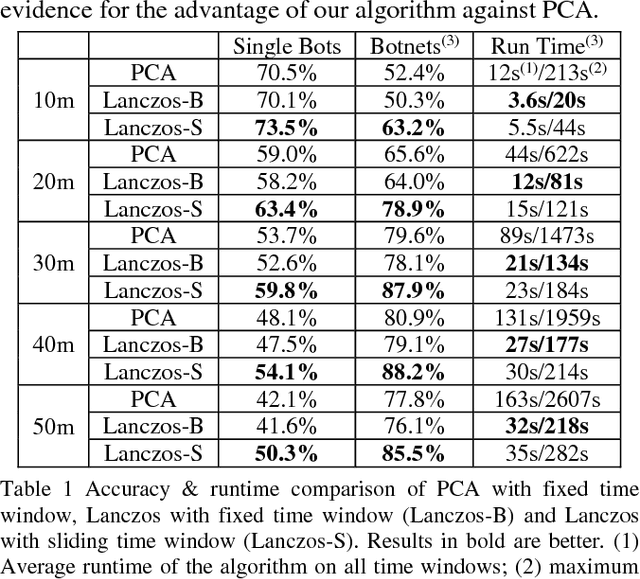


Botnet, a group of coordinated bots, is becoming the main platform of malicious Internet activities like DDOS, click fraud, web scraping, spam/rumor distribution, etc. This paper focuses on design and experiment of a new approach for botnet detection from streaming web server logs, motivated by its wide applicability, real-time protection capability, ease of use and better security of sensitive data. Our algorithm is inspired by a Principal Component Analysis (PCA) to capture correlation in data, and we are first to recognize and adapt Lanczos method to improve the time complexity of PCA-based botnet detection from cubic to sub-cubic, which enables us to more accurately and sensitively detect botnets with sliding time windows rather than fixed time windows. We contribute a generalized online correlation matrix update formula, and a new termination condition for Lanczos iteration for our purpose based on error bound and non-decreasing eigenvalues of symmetric matrices. On our dataset of an ecommerce website logs, experiments show the time cost of Lanczos method with different time windows are consistently only 20% to 25% of PCA.
Unifying Topic, Sentiment & Preference in an HDP-Based Rating Regression Model for Online Reviews
Dec 19, 2018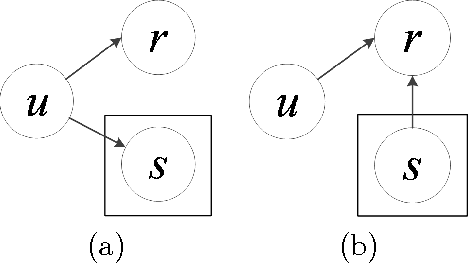
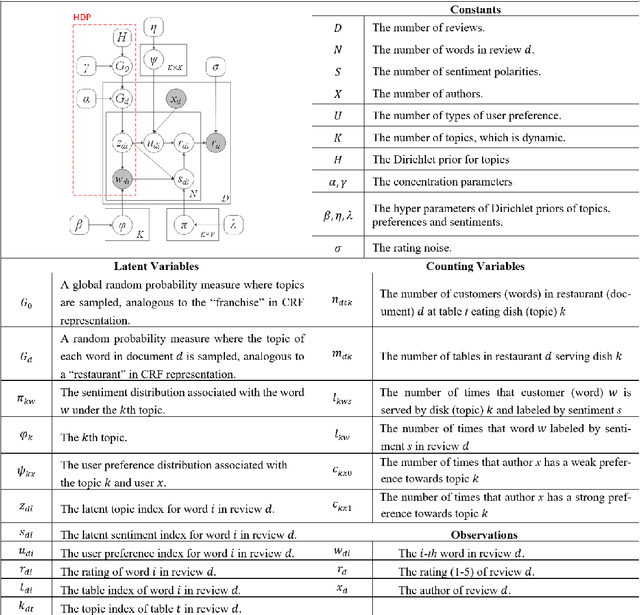
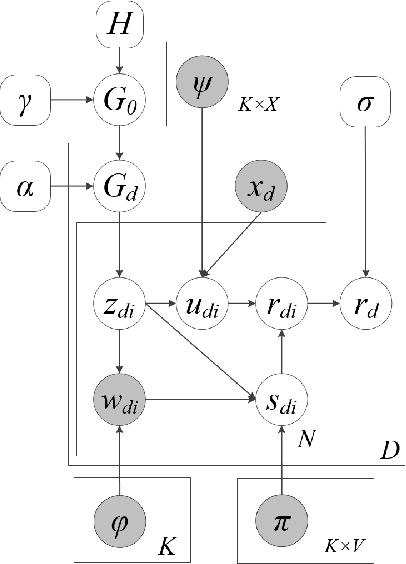
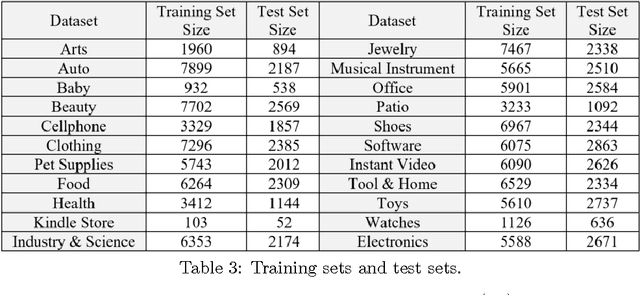
This paper proposes a new HDP based online review rating regression model named Topic-Sentiment-Preference Regression Analysis (TSPRA). TSPRA combines topics (i.e. product aspects), word sentiment and user preference as regression factors, and is able to perform topic clustering, review rating prediction, sentiment analysis and what we invent as "critical aspect" analysis altogether in one framework. TSPRA extends sentiment approaches by integrating the key concept "user preference" in collaborative filtering (CF) models into consideration, while it is distinct from current CF models by decoupling "user preference" and "sentiment" as independent factors. Our experiments conducted on 22 Amazon datasets show overwhelming better performance in rating predication against a state-of-art model FLAME (2015) in terms of error, Pearson's Correlation and number of inverted pairs. For sentiment analysis, we compare the derived word sentiments against a public sentiment resource SenticNet3 and our sentiment estimations clearly make more sense in the context of online reviews. Last, as a result of the de-correlation of "user preference" from "sentiment", TSPRA is able to evaluate a new concept "critical aspects", defined as the product aspects seriously concerned by users but negatively commented in reviews. Improvement to such "critical aspects" could be most effective to enhance user experience.