 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVAM-Pose: Conditional Variational Autoencoder for Multi-Object Monocular Pose Estimation
Oct 11, 2024



Estimating rigid objects' poses is one of the fundamental problems in computer vision, with a range of applications across automation and augmented reality. Most existing approaches adopt one network per object class strategy, depend heavily on objects' 3D models, depth data, and employ a time-consuming iterative refinement, which could be impractical for some applications. This paper presents a novel approach, CVAM-Pose, for multi-object monocular pose estimation that addresses these limitations. The CVAM-Pose method employs a label-embedded conditional variational autoencoder network, to implicitly abstract regularised representations of multiple objects in a single low-dimensional latent space. This autoencoding process uses only images captured by a projective camera and is robust to objects' occlusion and scene clutter. The classes of objects are one-hot encoded and embedded throughout the network. The proposed label-embedded pose regression strategy interprets the learnt latent space representations utilising continuous pose representations. Ablation tests and systematic evaluations demonstrate the scalability and efficiency of the CVAM-Pose method for multi-object scenarios. The proposed CVAM-Pose outperforms competing latent space approaches. For example, it is respectively 25% and 20% better than AAE and Multi-Path methods, when evaluated using the $\mathrm{AR_{VSD}}$ metric on the Linemod-Occluded dataset. It also achieves results somewhat comparable to methods reliant on 3D models reported in BOP challenges. Code available: https://github.com/JZhao12/CVAM-Pose
Faster Adaptive Decentralized Learning Algorithms
Aug 19, 2024

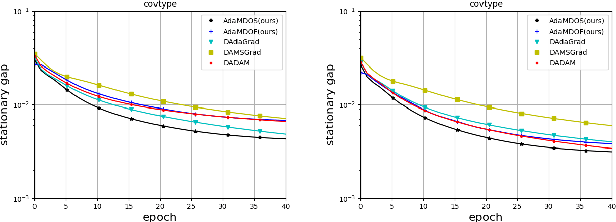

Decentralized learning recently has received increasing attention in machine learning due to its advantages in implementation simplicity and system robustness, data privacy. Meanwhile, the adaptive gradient methods show superior performances in many machine learning tasks such as training neural networks. Although some works focus on studying decentralized optimization algorithms with adaptive learning rates, these adaptive decentralized algorithms still suffer from high sample complexity. To fill these gaps, we propose a class of faster adaptive decentralized algorithms (i.e., AdaMDOS and AdaMDOF) for distributed nonconvex stochastic and finite-sum optimization, respectively. Moreover, we provide a solid convergence analysis framework for our methods. In particular, we prove that our AdaMDOS obtains a near-optimal sample complexity of $\tilde{O}(\epsilon^{-3})$ for finding an $\epsilon$-stationary solution of nonconvex stochastic optimization. Meanwhile, our AdaMDOF obtains a near-optimal sample complexity of $O(\sqrt{n}\epsilon^{-2})$ for finding an $\epsilon$-stationary solution of nonconvex finite-sum optimization, where $n$ denotes the sample size. To the best of our knowledge, our AdaMDOF algorithm is the first adaptive decentralized algorithm for nonconvex finite-sum optimization. Some experimental results demonstrate efficiency of our algorithms.
Code Representation Pre-training with Complements from Program Executions
Sep 04, 2023Large language models (LLMs) for natural language processing have been grafted onto programming language modeling for advancing code intelligence. Although it can be represented in the text format, code is syntactically more rigorous in order to be properly compiled or interpreted to perform a desired set of behaviors given any inputs. In this case, existing works benefit from syntactic representations to learn from code less ambiguously in the forms of abstract syntax tree, control-flow graph, etc. However, programs with the same purpose can be implemented in various ways showing different syntactic representations while the ones with similar implementations can have distinct behaviors. Though trivially demonstrated during executions, such semantics about functionality are challenging to be learned directly from code, especially in an unsupervised manner. Hence, in this paper, we propose FuzzPretrain to explore the dynamic information of programs revealed by their test cases and embed it into the feature representations of code as complements. The test cases are obtained with the assistance of a customized fuzzer and are only required during pre-training. FuzzPretrain yielded more than 6%/9% mAP improvements on code search over its counterparts trained with only source code or AST, respectively. Our extensive experimental results show the benefits of learning discriminative code representations with program executions.
Understanding Programs by Exploiting (Fuzzing) Test Cases
May 23, 2023Semantic understanding of programs has attracted great attention in the community. Inspired by recent successes of large language models (LLMs) in natural language understanding, tremendous progress has been made by treating programming language as another sort of natural language and training LLMs on corpora of program code. However, programs are essentially different from texts after all, in a sense that they are normally heavily structured and syntax-strict. In particular, programs and their basic units (i.e., functions and subroutines) are designed to demonstrate a variety of behaviors and/or provide possible outputs, given different inputs. The relationship between inputs and possible outputs/behaviors represents the functions/subroutines and profiles the program as a whole. Therefore, we propose to incorporate such a relationship into learning, for achieving a deeper semantic understanding of programs. To obtain inputs that are representative enough to trigger the execution of most part of the code, we resort to fuzz testing and propose fuzz tuning to boost the performance of program understanding and code representation learning, given a pre-trained LLM. The effectiveness of the proposed method is verified on two program understanding tasks including code clone detection and code classification, and it outperforms current state-of-the-arts by large margins. Code is available at https://github.com/rabbitjy/FuzzTuning.
Graph Reinforcement Learning for Predictive Power Allocation to Mobile Users
Mar 08, 2022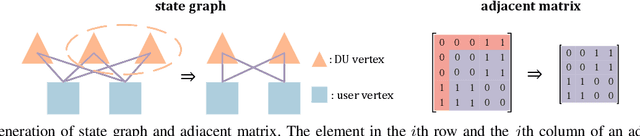
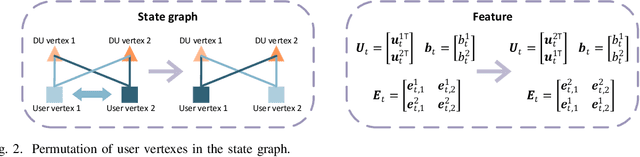


Allocating resources with future channels can save resource to ensure quality-of-service of video streaming. In this paper, we optimize predictive power allocation to minimize the energy consumed at distributed units (DUs) by using deep deterministic policy gradient (DDPG) to find optimal policy and predict average channel gains. To improve training efficiency, we resort to graph DDPG for exploiting two kinds of relational priors: (a) permutation equivariant (PE) and permutation invariant (PI) properties of policy function and action-value function, (b) topology relation among users and DUs. To design graph DDPG framework more systematically in harnessing the priors, we first demonstrate how to transform matrix-based DDPG into graph-based DDPG. Then, we respectively design the actor and critic networks to satisfy the permutation properties when graph neural networks are used in embedding and end to-end manners. To avoid destroying the PE/PI properties of the actor and critic networks, we conceive a batch normalization method. Finally, we show the impact of leveraging each prior. Simulation results show that the learned predictive policy performs close to the optimal solution with perfect future information, and the graph DDPG algorithms converge much faster than existing DDPG algorithms.
Accelerating Deep Reinforcement Learning With the Aid of a Partial Model: Power-Efficient Predictive Video Streaming
Mar 21, 2020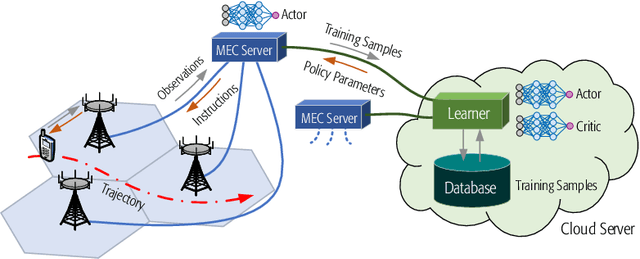
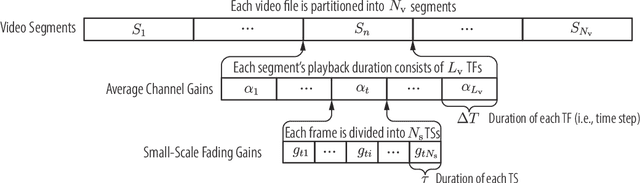
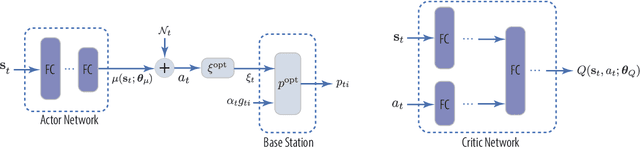
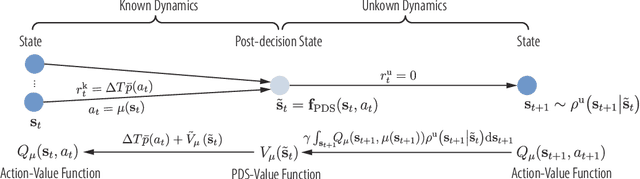
Predictive power allocation is conceived for power-efficient video streaming over mobile networks using deep reinforcement learning. The goal is to minimize the accumulated energy consumption over a complete video streaming session for a mobile user under the quality of service constraint that avoids video playback interruptions. To handle the continuous state and action spaces, we resort to deep deterministic policy gradient (DDPG) algorithm for solving the formulated problem. In contrast to previous predictive resource policies that first predict future information with historical data and then optimize the policy based on the predicted information, the proposed policy operates in an on-line and end-to-end manner. By judiciously designing the action and state that only depend on slowly-varying average channel gains, the signaling overhead between the edge server and the base stations can be reduced, and the dynamics of the system can be learned effortlessly. To improve the robustness of streaming and accelerate learning, we further exploit the partially known dynamics of the system by integrating the concepts of safer layer, post-decision state, and virtual experience into the basic DDPG algorithm. Our simulation results show that the proposed policies converge to the optimal policy derived based on perfect prediction of the future large-scale channel gains and outperforms the first-predict-then-optimize policy in the presence of prediction errors. By harnessing the partially known model of the system dynamics, the convergence speed can be dramatically improved.
LSICC: A Large Scale Informal Chinese Corpus
Nov 26, 2018

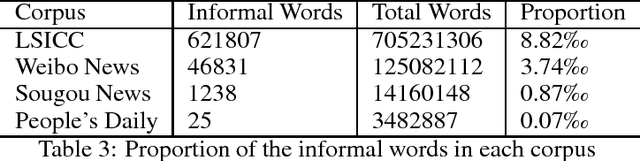
Deep learning based natural language processing model is proven powerful, but need large-scale dataset. Due to the significant gap between the real-world tasks and existing Chinese corpus, in this paper, we introduce a large-scale corpus of informal Chinese. This corpus contains around 37 million book reviews and 50 thousand netizen's comments to the news. We explore the informal words frequencies of the corpus and show the difference between our corpus and the existing ones. The corpus can be further used to train deep learning based natural language processing tasks such as Chinese word segmentation, sentiment analysis.