 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomeAdam: Adam and AdamW Algorithms Sometimes Go Home to Obtain Better Provable Generalization
Mar 03, 2026Adam and AdamW are a class of default optimizers for training deep learning models in machine learning. These adaptive algorithms converge faster but generalize worse compared to SGD. In fact, their proved generalization error $O(\frac{1}{\sqrt{N}})$ also is larger than $O(\frac{1}{N})$ of SGD, where $N$ denotes training sample size. Recently, although some variants of Adam have been proposed to improve its generalization, their improved generalizations are still unexplored in theory. To fill this gap, in the paper, we restudy generalization of Adam and AdamW via algorithmic stability, and first prove that Adam and AdamW without square-root (i.e., Adam(W)-srf) have a generalization error $O(\frac{\hatρ^{-2T}}{N})$, where $T$ denotes iteration number and $\hatρ>0$ denotes the smallest element of second-order momentum plus a small positive number. To improve generalization, we propose a class of efficient clever Adam (i.e., HomeAdam(W)) algorithms via sometimes returning momentum-based SGD. Moreover, we prove that our HomeAdam(W) have a smaller generalization error $O(\frac{1}{N})$ than $O(\frac{\hatρ^{-2T}}{N})$ of Adam(W)-srf, since $\hatρ$ is generally very small. In particular, it is also smaller than the existing $O(\frac{1}{\sqrt{N}})$ of Adam(W). Meanwhile, we prove our HomeAdam(W) have a faster convergence rate of $O(\frac{1}{T^{1/4}})$ than $O(\frac{\breveρ^{-1}}{T^{1/4}})$ of the Adam(W)-srf, where $\breveρ\leq\hatρ$ also is very small. Extensive numerical experiments demonstrate efficiency of our HomeAdam(W) algorithms.
LiMuon: Light and Fast Muon Optimizer for Large Models
Sep 19, 2025



Large models recently are widely applied in artificial intelligence, so efficient training of large models has received widespread attention. More recently, a useful Muon optimizer is specifically designed for matrix-structured parameters of large models. Although some works have begun to studying Muon optimizer, the existing Muon and its variants still suffer from high sample complexity or high memory for large models. To fill this gap, we propose a light and fast Muon (LiMuon) optimizer for training large models, which builds on the momentum-based variance reduced technique and randomized Singular Value Decomposition (SVD). Our LiMuon optimizer has a lower memory than the current Muon and its variants. Moreover, we prove that our LiMuon has a lower sample complexity of $O(\epsilon^{-3})$ for finding an $\epsilon$-stationary solution of non-convex stochastic optimization under the smooth condition. Recently, the existing convergence analysis of Muon optimizer mainly relies on the strict Lipschitz smooth assumption, while some artificial intelligence tasks such as training large language models (LLMs) do not satisfy this condition. We also proved that our LiMuon optimizer has a sample complexity of $O(\epsilon^{-3})$ under the generalized smooth condition. Numerical experimental results on training DistilGPT2 and ViT models verify efficiency of our LiMuon optimizer.
Faster Adaptive Decentralized Learning Algorithms
Aug 19, 2024

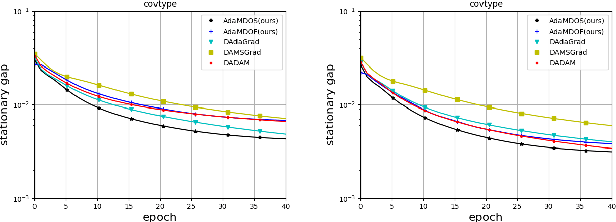

Decentralized learning recently has received increasing attention in machine learning due to its advantages in implementation simplicity and system robustness, data privacy. Meanwhile, the adaptive gradient methods show superior performances in many machine learning tasks such as training neural networks. Although some works focus on studying decentralized optimization algorithms with adaptive learning rates, these adaptive decentralized algorithms still suffer from high sample complexity. To fill these gaps, we propose a class of faster adaptive decentralized algorithms (i.e., AdaMDOS and AdaMDOF) for distributed nonconvex stochastic and finite-sum optimization, respectively. Moreover, we provide a solid convergence analysis framework for our methods. In particular, we prove that our AdaMDOS obtains a near-optimal sample complexity of $\tilde{O}(\epsilon^{-3})$ for finding an $\epsilon$-stationary solution of nonconvex stochastic optimization. Meanwhile, our AdaMDOF obtains a near-optimal sample complexity of $O(\sqrt{n}\epsilon^{-2})$ for finding an $\epsilon$-stationary solution of nonconvex finite-sum optimization, where $n$ denotes the sample size. To the best of our knowledge, our AdaMDOF algorithm is the first adaptive decentralized algorithm for nonconvex finite-sum optimization. Some experimental results demonstrate efficiency of our algorithms.
Optimal Hessian/Jacobian-Free Nonconvex-PL Bilevel Optimization
Jul 25, 2024



Bilevel optimization is widely applied in many machine learning tasks such as hyper-parameter learning, meta learning and reinforcement learning. Although many algorithms recently have been developed to solve the bilevel optimization problems, they generally rely on the (strongly) convex lower-level problems. More recently, some methods have been proposed to solve the nonconvex-PL bilevel optimization problems, where their upper-level problems are possibly nonconvex, and their lower-level problems are also possibly nonconvex while satisfying Polyak-{\L}ojasiewicz (PL) condition. However, these methods still have a high convergence complexity or a high computation complexity such as requiring compute expensive Hessian/Jacobian matrices and its inverses. In the paper, thus, we propose an efficient Hessian/Jacobian-free method (i.e., HJFBiO) with the optimal convergence complexity to solve the nonconvex-PL bilevel problems. Theoretically, under some mild conditions, we prove that our HJFBiO method obtains an optimal convergence rate of $O(\frac{1}{T})$, where $T$ denotes the number of iterations, and has an optimal gradient complexity of $O(\epsilon^{-1})$ in finding an $\epsilon$-stationary solution. We conduct some numerical experiments on the bilevel PL game and hyper-representation learning task to demonstrate efficiency of our proposed method.
Adaptive Mirror Descent Bilevel Optimization
Nov 18, 2023
In the paper, we propose a class of efficient adaptive bilevel methods based on mirror descent for nonconvex bilevel optimization, where its upper-level problem is nonconvex possibly with nonsmooth regularization, and its lower-level problem is also nonconvex while satisfies Polyak-{\L}ojasiewicz (PL) condition. To solve these deterministic bilevel problems, we present an efficient adaptive projection-aid gradient (i.e., AdaPAG) method based on mirror descent, and prove that it obtains the best known gradient complexity of $O(\epsilon^{-1})$ for finding an $\epsilon$-stationary solution of nonconvex bilevel problems. To solve these stochastic bilevel problems, we propose an efficient adaptive stochastic projection-aid gradient (i.e., AdaVSPAG) methods based on mirror descent and variance-reduced techniques, and prove that it obtains the best known gradient complexity of $O(\epsilon^{-3/2})$ for finding an $\epsilon$-stationary solution. Since the PL condition relaxes the strongly convex, our algorithms can be used to nonconvex strongly-convex bilevel optimization. Theoretically, we provide a useful convergence analysis framework for our methods under some mild conditions, and prove that our methods have a fast convergence rate of $O(\frac{1}{T})$, where $T$ denotes the number of iterations.
Near-Optimal Decentralized Momentum Method for Nonconvex-PL Minimax Problems
Apr 21, 2023
Minimax optimization plays an important role in many machine learning tasks such as generative adversarial networks (GANs) and adversarial training. Although recently a wide variety of optimization methods have been proposed to solve the minimax problems, most of them ignore the distributed setting where the data is distributed on multiple workers. Meanwhile, the existing decentralized minimax optimization methods rely on the strictly assumptions such as (strongly) concavity and variational inequality conditions. In the paper, thus, we propose an efficient decentralized momentum-based gradient descent ascent (DM-GDA) method for the distributed nonconvex-PL minimax optimization, which is nonconvex in primal variable and is nonconcave in dual variable and satisfies the Polyak-Lojasiewicz (PL) condition. In particular, our DM-GDA method simultaneously uses the momentum-based techniques to update variables and estimate the stochastic gradients. Moreover, we provide a solid convergence analysis for our DM-GDA method, and prove that it obtains a near-optimal gradient complexity of $O(\epsilon^{-3})$ for finding an $\epsilon$-stationary solution of the nonconvex-PL stochastic minimax problems, which reaches the lower bound of nonconvex stochastic optimization. To the best of our knowledge, we first study the decentralized algorithm for Nonconvex-PL stochastic minimax optimization over a network.
Enhanced Adaptive Gradient Algorithms for Nonconvex-PL Minimax Optimization
Mar 13, 2023
In the paper, we study a class of nonconvex nonconcave minimax optimization problems (i.e., $\min_x\max_y f(x,y)$), where $f(x,y)$ is possible nonconvex in $x$, and it is nonconcave and satisfies the Polyak-Lojasiewicz (PL) condition in $y$. Moreover, we propose a class of enhanced momentum-based gradient descent ascent methods (i.e., MSGDA and AdaMSGDA) to solve these stochastic Nonconvex-PL minimax problems. In particular, our AdaMSGDA algorithm can use various adaptive learning rates in updating the variables $x$ and $y$ without relying on any global and coordinate-wise adaptive learning rates. Theoretically, we present an effective convergence analysis framework for our methods. Specifically, we prove that our MSGDA and AdaMSGDA methods have the best known sample (gradient) complexity of $O(\epsilon^{-3})$ only requiring one sample at each loop in finding an $\epsilon$-stationary solution (i.e., $\mathbb{E}\|\nabla F(x)\|\leq \epsilon$, where $F(x)=\max_y f(x,y)$). This manuscript commemorates the mathematician Boris Polyak (1935-2023).
On Momentum-Based Gradient Methods for Bilevel Optimization with Nonconvex Lower-Level
Mar 07, 2023



Bilevel optimization is a popular two-level hierarchical optimization, which has been widely applied to many machine learning tasks such as hyperparameter learning, meta learning and continual learning. Although many bilevel optimization methods recently have been developed, the bilevel methods are not well studied when the lower-level problem is nonconvex. To fill this gap, in the paper, we study a class of nonconvex bilevel optimization problems, which both upper-level and lower-level problems are nonconvex, and the lower-level problem satisfies Polyak-Lojasiewicz (PL) condition. We propose an efficient momentum-based gradient bilevel method (MGBiO) to solve these deterministic problems. Meanwhile, we propose a class of efficient momentum-based stochastic gradient bilevel methods (MSGBiO and VR-MSGBiO) to solve these stochastic problems. Moreover, we provide a useful convergence analysis framework for our methods. Specifically, under some mild conditions, we prove that our MGBiO method has a sample (or gradient) complexity of $O(\epsilon^{-2})$ for finding an $\epsilon$-stationary solution of the deterministic bilevel problems (i.e., $\|\nabla F(x)\|\leq \epsilon$), which improves the existing best results by a factor of $O(\epsilon^{-1})$. Meanwhile, we prove that our MSGBiO and VR-MSGBiO methods have sample complexities of $\tilde{O}(\epsilon^{-4})$ and $\tilde{O}(\epsilon^{-3})$, respectively, in finding an $\epsilon$-stationary solution of the stochastic bilevel problems (i.e., $\mathbb{E}\|\nabla F(x)\|\leq \epsilon$), which improves the existing best results by a factor of $O(\epsilon^{-3})$. This manuscript commemorates the mathematician Boris Polyak (1935 -2023).
Communication-Efficient Federated Bilevel Optimization with Local and Global Lower Level Problems
Feb 13, 2023



Bilevel Optimization has witnessed notable progress recently with new emerging efficient algorithms, yet it is underexplored in the Federated Learning setting. It is unclear how the challenges of Federated Learning affect the convergence of bilevel algorithms. In this work, we study Federated Bilevel Optimization problems. We first propose the FedBiO algorithm that solves the hyper-gradient estimation problem efficiently, then we propose FedBiOAcc to accelerate FedBiO. FedBiO has communication complexity $O(\epsilon^{-1.5})$ with linear speed up, while FedBiOAcc achieves communication complexity $O(\epsilon^{-1})$, sample complexity $O(\epsilon^{-1.5})$ and also the linear speed up. We also study Federated Bilevel Optimization problems with local lower level problems, and prove that FedBiO and FedBiOAcc converges at the same rate with some modification.
FedDA: Faster Framework of Local Adaptive Gradient Methods via Restarted Dual Averaging
Feb 13, 2023



Federated learning (FL) is an emerging learning paradigm to tackle massively distributed data. In Federated Learning, a set of clients jointly perform a machine learning task under the coordination of a server. The FedAvg algorithm is one of the most widely used methods to solve Federated Learning problems. In FedAvg, the learning rate is a constant rather than changing adaptively. The adaptive gradient methods show superior performance over the constant learning rate schedule; however, there is still no general framework to incorporate adaptive gradient methods into the federated setting. In this paper, we propose \textbf{FedDA}, a novel framework for local adaptive gradient methods. The framework adopts a restarted dual averaging technique and is flexible with various gradient estimation methods and adaptive learning rate formulations. In particular, we analyze \textbf{FedDA-MVR}, an instantiation of our framework, and show that it achieves gradient complexity $\tilde{O}(\epsilon^{-1.5})$ and communication complexity $\tilde{O}(\epsilon^{-1})$ for finding a stationary point $\epsilon$. This matches the best known rate for first-order FL algorithms and \textbf{FedDA-MVR} is the first adaptive FL algorithm that achieves this rate. We also perform extensive numerical experiments to verify the efficacy of our method.