 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity of AI Agents
Jun 20, 2024



The study and development of AI agents have been boosted by large language models. AI agents can function as intelligent assistants and complete tasks on behalf of their users with access to tools and the ability to execute commands in their environments, Through studying and experiencing the workflow of typical AI agents, we have raised several concerns regarding their security. These potential vulnerabilities are not addressed by the frameworks used to build the agents, nor by research aimed at improving the agents. In this paper, we identify and describe these vulnerabilities in detail from a system security perspective, emphasizing their causes and severe effects. Furthermore, we introduce defense mechanisms corresponding to each vulnerability with meticulous design and experiments to evaluate their viability. Altogether, this paper contextualizes the security issues in the current development of AI agents and delineates methods to make AI agents safer and more reliable.
Exploring Fuzzing as Data Augmentation for Neural Test Generation
Jun 12, 2024Testing is an essential part of modern software engineering to build reliable programs. As testing the software is important but expensive, automatic test case generation methods have become popular in software development. Unlike traditional search-based coverage-guided test generation like fuzzing, neural test generation backed by large language models can write tests that are semantically meaningful and can be understood by other maintainers. However, compared to regular code corpus, unit tests in the datasets are limited in amount and diversity. In this paper, we present a novel data augmentation technique **FuzzAug**, that combines the advantages of fuzzing and large language models. FuzzAug not only keeps valid program semantics in the augmented data, but also provides more diverse inputs to the function under test, helping the model to associate correct inputs embedded with the function's dynamic behaviors with the function under test. We evaluate FuzzAug's benefits by using it on a neural test generation dataset to train state-of-the-art code generation models. By augmenting the training set, our model generates test cases with $11\%$ accuracy increases. Models trained with FuzzAug generate unit test functions with double the branch coverage compared to those without it. FuzzAug can be used across various datasets to train advanced code generation models, enhancing their utility in automated software testing. Our work shows the benefits of using dynamic analysis results to enhance neural test generation. Code and data will be publicly available.
LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing
Jun 11, 2024

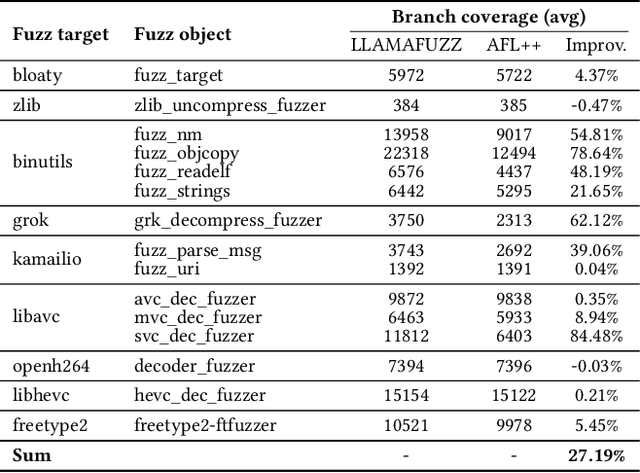
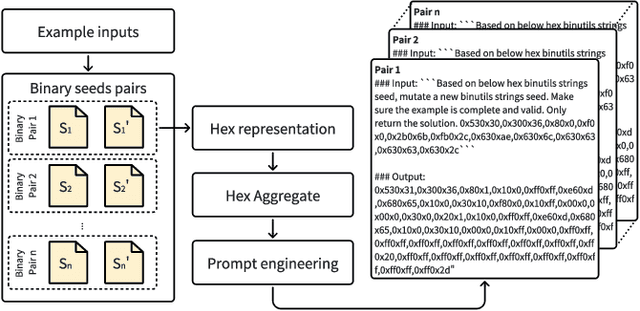
Greybox fuzzing has achieved success in revealing bugs and vulnerabilities in programs. However, randomized mutation strategies have limited the fuzzer's performance on structured data. Specialized fuzzers can handle complex structured data, but require additional efforts in grammar and suffer from low throughput. In this paper, we explore the potential of utilizing the Large Language Model to enhance greybox fuzzing for structured data. We utilize the pre-trained knowledge of LLM about data conversion and format to generate new valid inputs. We further fine-tuned it with paired mutation seeds to learn structured format and mutation strategies effectively. Our LLM-based fuzzer, LLAMAFUZZ, integrates the power of LLM to understand and mutate structured data to fuzzing. We conduct experiments on the standard bug-based benchmark Magma and a wide variety of real-world programs. LLAMAFUZZ outperforms our top competitor by 41 bugs on average. We also identified 47 unique bugs across all trials. Moreover, LLAMAFUZZ demonstrated consistent performance on both bug trigger and bug reached. Compared to AFL++, LLAMAFUZZ achieved 27.19% more branches in real-world program sets on average. We also demonstrate a case study to explain how LLMs enhance the fuzzing process in terms of code coverage.
UniTSyn: A Large-Scale Dataset Capable of Enhancing the Prowess of Large Language Models for Program Testing
Feb 04, 2024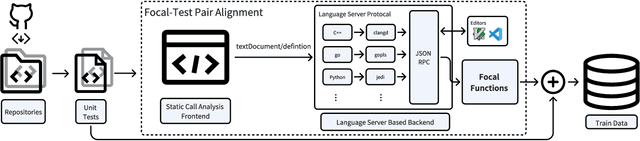
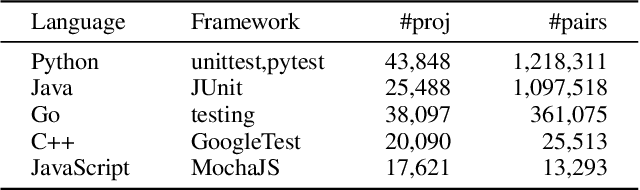
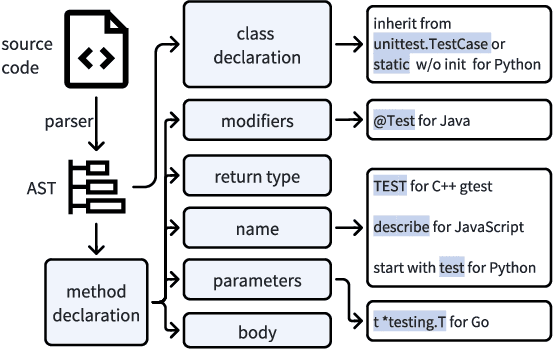
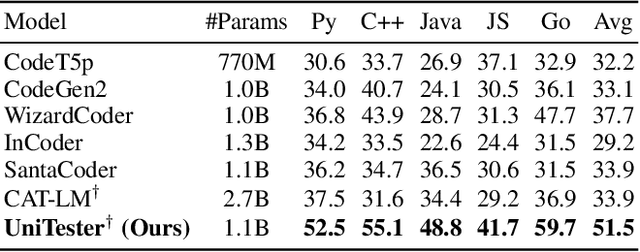
The remarkable capability of large language models (LLMs) in generating high-quality code has drawn increasing attention in the software testing community. However, existing code LLMs often demonstrate unsatisfactory capabilities in generating accurate and complete tests since they were trained on code snippets collected without differentiating between code for testing purposes and other code. In this paper, we present a large-scale dataset UniTSyn, which is capable of enhancing the prowess of LLMs for Unit Test Synthesis. Associating tests with the tested functions is crucial for LLMs to infer the expected behavior and the logic paths to be verified. By leveraging Language Server Protocol, UniTSyn achieves the challenging goal of collecting focal-test pairs without per-project execution setups or per-language heuristics that tend to be fragile and difficult to scale. It contains 2.7 million focal-test pairs across five mainstream programming languages, making it possible to be utilized for enhancing the test generation ability of LLMs. The details of UniTSyn can be found in Table 1. Our experiments demonstrate that, by building an autoregressive model based on UniTSyn, we can achieve significant benefits in learning and understanding unit test representations, resulting in improved generation accuracy and code coverage across all evaluated programming languages. Code and data will be publicly available.
Code Representation Pre-training with Complements from Program Executions
Sep 04, 2023Large language models (LLMs) for natural language processing have been grafted onto programming language modeling for advancing code intelligence. Although it can be represented in the text format, code is syntactically more rigorous in order to be properly compiled or interpreted to perform a desired set of behaviors given any inputs. In this case, existing works benefit from syntactic representations to learn from code less ambiguously in the forms of abstract syntax tree, control-flow graph, etc. However, programs with the same purpose can be implemented in various ways showing different syntactic representations while the ones with similar implementations can have distinct behaviors. Though trivially demonstrated during executions, such semantics about functionality are challenging to be learned directly from code, especially in an unsupervised manner. Hence, in this paper, we propose FuzzPretrain to explore the dynamic information of programs revealed by their test cases and embed it into the feature representations of code as complements. The test cases are obtained with the assistance of a customized fuzzer and are only required during pre-training. FuzzPretrain yielded more than 6%/9% mAP improvements on code search over its counterparts trained with only source code or AST, respectively. Our extensive experimental results show the benefits of learning discriminative code representations with program executions.
Understanding Programs by Exploiting (Fuzzing) Test Cases
May 23, 2023Semantic understanding of programs has attracted great attention in the community. Inspired by recent successes of large language models (LLMs) in natural language understanding, tremendous progress has been made by treating programming language as another sort of natural language and training LLMs on corpora of program code. However, programs are essentially different from texts after all, in a sense that they are normally heavily structured and syntax-strict. In particular, programs and their basic units (i.e., functions and subroutines) are designed to demonstrate a variety of behaviors and/or provide possible outputs, given different inputs. The relationship between inputs and possible outputs/behaviors represents the functions/subroutines and profiles the program as a whole. Therefore, we propose to incorporate such a relationship into learning, for achieving a deeper semantic understanding of programs. To obtain inputs that are representative enough to trigger the execution of most part of the code, we resort to fuzz testing and propose fuzz tuning to boost the performance of program understanding and code representation learning, given a pre-trained LLM. The effectiveness of the proposed method is verified on two program understanding tasks including code clone detection and code classification, and it outperforms current state-of-the-arts by large margins. Code is available at https://github.com/rabbitjy/FuzzTuning.