 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Layer-Contrastive Decoding Reduces Hallucination in Large Language Model Generation
May 29, 2025Recent decoding methods improve the factuality of large language models~(LLMs) by refining how the next token is selected during generation. These methods typically operate at the token level, leveraging internal representations to suppress superficial patterns. Nevertheless, LLMs remain prone to hallucinations, especially over longer contexts. In this paper, we propose Active Layer-Contrastive Decoding (ActLCD), a novel decoding strategy that actively decides when to apply contrasting layers during generation. By casting decoding as a sequential decision-making problem, ActLCD employs a reinforcement learning policy guided by a reward-aware classifier to optimize factuality beyond the token level. Our experiments demonstrate that ActLCD surpasses state-of-the-art methods across five benchmarks, showcasing its effectiveness in mitigating hallucinations in diverse generation scenarios.
SteerDiff: Steering towards Safe Text-to-Image Diffusion Models
Oct 03, 2024Text-to-image (T2I) diffusion models have drawn attention for their ability to generate high-quality images with precise text alignment. However, these models can also be misused to produce inappropriate content. Existing safety measures, which typically rely on text classifiers or ControlNet-like approaches, are often insufficient. Traditional text classifiers rely on large-scale labeled datasets and can be easily bypassed by rephrasing. As diffusion models continue to scale, fine-tuning these safeguards becomes increasingly challenging and lacks flexibility. Recent red-teaming attack researches further underscore the need for a new paradigm to prevent the generation of inappropriate content. In this paper, we introduce SteerDiff, a lightweight adaptor module designed to act as an intermediary between user input and the diffusion model, ensuring that generated images adhere to ethical and safety standards with little to no impact on usability. SteerDiff identifies and manipulates inappropriate concepts within the text embedding space to guide the model away from harmful outputs. We conduct extensive experiments across various concept unlearning tasks to evaluate the effectiveness of our approach. Furthermore, we benchmark SteerDiff against multiple red-teaming strategies to assess its robustness. Finally, we explore the potential of SteerDiff for concept forgetting tasks, demonstrating its versatility in text-conditioned image generation.
LLAMAFUZZ: Large Language Model Enhanced Greybox Fuzzing
Jun 11, 2024

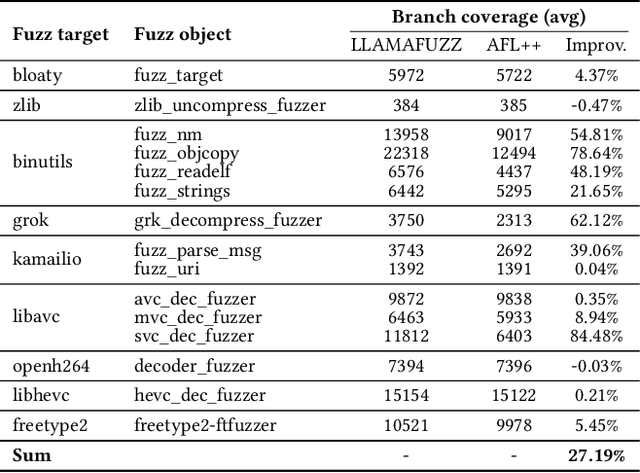
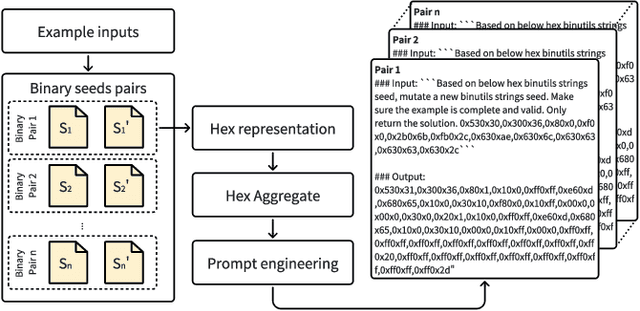
Greybox fuzzing has achieved success in revealing bugs and vulnerabilities in programs. However, randomized mutation strategies have limited the fuzzer's performance on structured data. Specialized fuzzers can handle complex structured data, but require additional efforts in grammar and suffer from low throughput. In this paper, we explore the potential of utilizing the Large Language Model to enhance greybox fuzzing for structured data. We utilize the pre-trained knowledge of LLM about data conversion and format to generate new valid inputs. We further fine-tuned it with paired mutation seeds to learn structured format and mutation strategies effectively. Our LLM-based fuzzer, LLAMAFUZZ, integrates the power of LLM to understand and mutate structured data to fuzzing. We conduct experiments on the standard bug-based benchmark Magma and a wide variety of real-world programs. LLAMAFUZZ outperforms our top competitor by 41 bugs on average. We also identified 47 unique bugs across all trials. Moreover, LLAMAFUZZ demonstrated consistent performance on both bug trigger and bug reached. Compared to AFL++, LLAMAFUZZ achieved 27.19% more branches in real-world program sets on average. We also demonstrate a case study to explain how LLMs enhance the fuzzing process in terms of code coverage.