 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Enhanced Reinforcement Learning-Based Resource Management via Digital Twin: Opportunities, Applications, and Challenges
Jun 12, 2024



This article presents a digital twin (DT)-enhanced reinforcement learning (RL) framework aimed at optimizing performance and reliability in network resource management, since the traditional RL methods face several unified challenges when applied to physical networks, including limited exploration efficiency, slow convergence, poor long-term performance, and safety concerns during the exploration phase. To deal with the above challenges, a comprehensive DT-based framework is proposed to enhance the convergence speed and performance for unified RL-based resource management. The proposed framework provides safe action exploration, more accurate estimates of long-term returns, faster training convergence, higher convergence performance, and real-time adaptation to varying network conditions. Then, two case studies on ultra-reliable and low-latency communication (URLLC) services and multiple unmanned aerial vehicles (UAV) network are presented, demonstrating improvements of the proposed framework in performance, convergence speed, and training cost reduction both on traditional RL and neural network based Deep RL (DRL). Finally, the article identifies and explores some of the research challenges and open issues in this rapidly evolving field.
Scalable Resource Management for Dynamic MEC: An Unsupervised Link-Output Graph Neural Network Approach
Jun 20, 2023



Deep learning has been successfully adopted in mobile edge computing (MEC) to optimize task offloading and resource allocation. However, the dynamics of edge networks raise two challenges in neural network (NN)-based optimization methods: low scalability and high training costs. Although conventional node-output graph neural networks (GNN) can extract features of edge nodes when the network scales, they fail to handle a new scalability issue whereas the dimension of the decision space may change as the network scales. To address the issue, in this paper, a novel link-output GNN (LOGNN)-based resource management approach is proposed to flexibly optimize the resource allocation in MEC for an arbitrary number of edge nodes with extremely low algorithm inference delay. Moreover, a label-free unsupervised method is applied to train the LOGNN efficiently, where the gradient of edge tasks processing delay with respect to the LOGNN parameters is derived explicitly. In addition, a theoretical analysis of the scalability of the node-output GNN and link-output GNN is performed. Simulation results show that the proposed LOGNN can efficiently optimize the MEC resource allocation problem in a scalable way, with an arbitrary number of servers and users. In addition, the proposed unsupervised training method has better convergence performance and speed than supervised learning and reinforcement learning-based training methods. The code is available at \url{https://github.com/UNIC-Lab/LOGNN}.
From Wide to Deep: Dimension Lifting Network for Parameter-efficient Knowledge Graph Embedding
Mar 22, 2023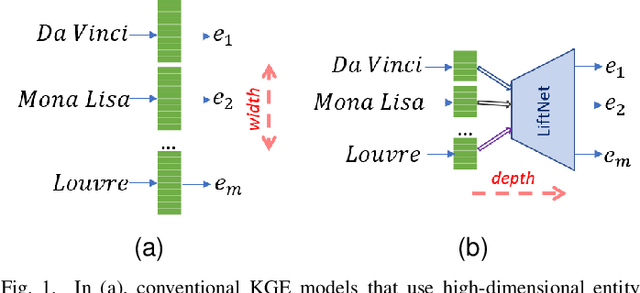
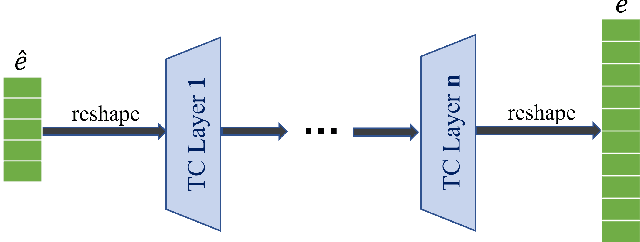
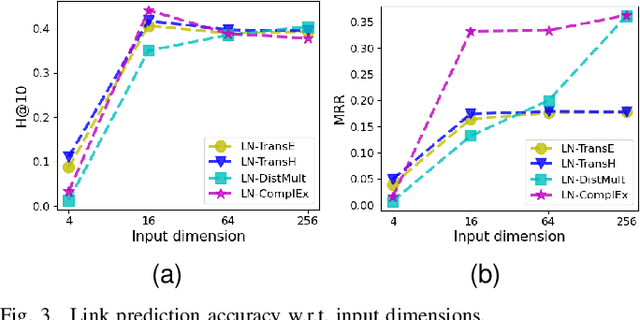
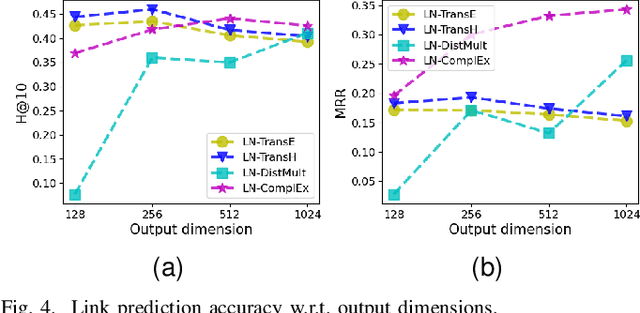
Knowledge graph embedding (KGE) that maps entities and relations into vector representations is essential for downstream tasks. Conventional KGE methods require relatively high-dimensional entity representations to preserve the structural information of knowledge graph, but lead to oversized model parameters. Recent methods reduce model parameters by adopting low-dimensional entity representations, while developing techniques (e.g., knowledge distillation) to compensate for the reduced dimension. However, such operations produce degraded model accuracy and limited reduction of model parameters. Specifically, we view the concatenation of all entity representations as an embedding layer, and then conventional KGE methods that adopt high-dimensional entity representations equal to enlarging the width of the embedding layer to gain expressiveness. To achieve parameter efficiency without sacrificing accuracy, we instead increase the depth and propose a deeper embedding network for entity representations, i.e., a narrow embedding layer and a multi-layer dimension lifting network (LiftNet). Experiments on three public datasets show that the proposed method (implemented based on TransE and DistMult) with 4-dimensional entity representations achieves more accurate link prediction results than counterpart parameter-efficient KGE methods and strong KGE baselines, including TransE and DistMult with 512-dimensional entity representations.