 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Structure-Agnostic Co-Tuning Framework for LLMs and SLMs in Cloud-Edge Systems
Nov 12, 2025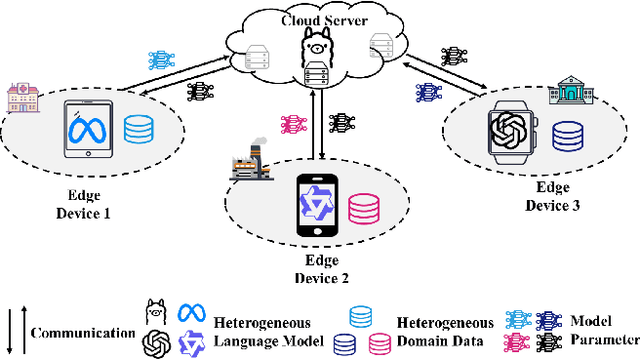
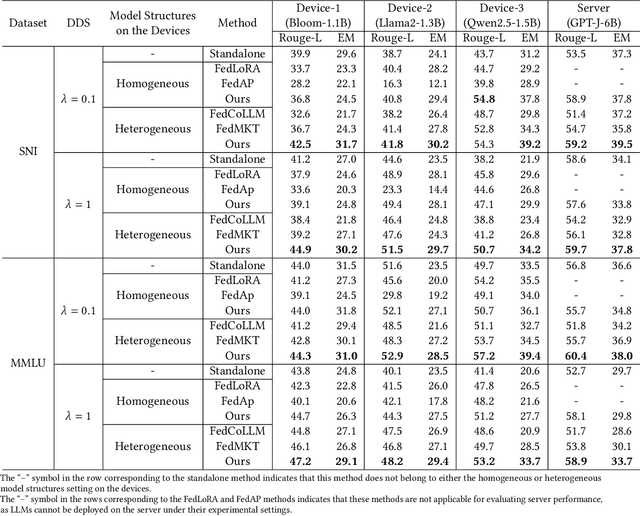
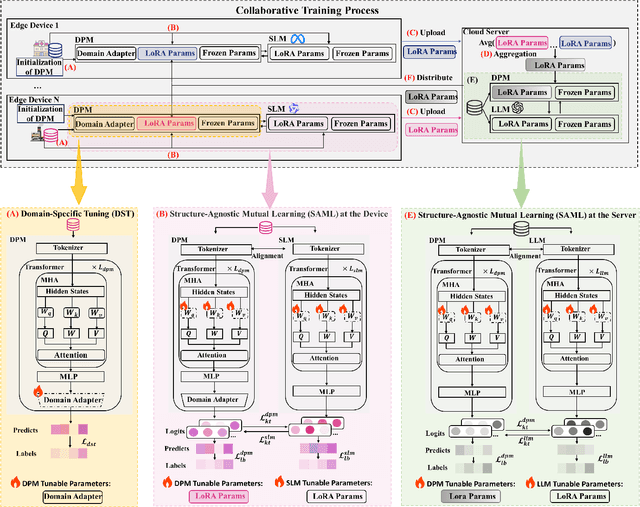
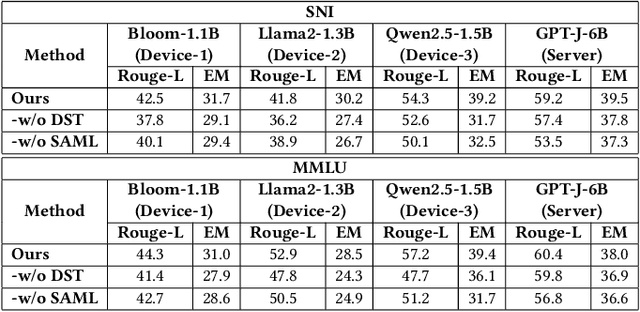
The surge in intelligent applications driven by large language models (LLMs) has made it increasingly difficult for bandwidth-limited cloud servers to process extensive LLM workloads in real time without compromising user data privacy. To solve these problems, recent research has focused on constructing cloud-edge consortia that integrate server-based LLM with small language models (SLMs) on mobile edge devices. Furthermore, designing collaborative training mechanisms within such consortia to enhance inference performance has emerged as a promising research direction. However, the cross-domain deployment of SLMs, coupled with structural heterogeneity in SLMs architectures, poses significant challenges to enhancing model performance. To this end, we propose Co-PLMs, a novel co-tuning framework for collaborative training of large and small language models, which integrates the process of structure-agnostic mutual learning to realize knowledge exchange between the heterogeneous language models. This framework employs distilled proxy models (DPMs) as bridges to enable collaborative training between the heterogeneous server-based LLM and on-device SLMs, while preserving the domain-specific insights of each device. The experimental results show that Co-PLMs outperform state-of-the-art methods, achieving average increases of 5.38% in Rouge-L and 4.88% in EM.
A Semi-Supervised Federated Learning Framework with Hierarchical Clustering Aggregation for Heterogeneous Satellite Networks
Jul 30, 2025



Low Earth Orbit (LEO) satellites are emerging as key components of 6G networks, with many already deployed to support large-scale Earth observation and sensing related tasks. Federated Learning (FL) presents a promising paradigm for enabling distributed intelligence in these resource-constrained and dynamic environments. However, achieving reliable convergence, while minimizing both processing time and energy consumption, remains a substantial challenge, particularly in heterogeneous and partially unlabeled satellite networks. To address this challenge, we propose a novel semi-supervised federated learning framework tailored for LEO satellite networks with hierarchical clustering aggregation. To further reduce communication overhead, we integrate sparsification and adaptive weight quantization techniques. In addition, we divide the FL clustering into two stages: satellite cluster aggregation stage and Ground Stations (GSs) aggregation stage. The supervised learning at GSs guides selected Parameter Server (PS) satellites, which in turn support fully unlabeled satellites during the federated training process. Extensive experiments conducted on a satellite network testbed demonstrate that our proposal can significantly reduce processing time (up to 3x) and energy consumption (up to 4x) compared to other comparative methods while maintaining model accuracy.
HyperMAN: Hypergraph-enhanced Meta-learning Adaptive Network for Next POI Recommendation
Mar 27, 2025Next Point-of-Interest (POI) recommendation aims to predict users' next locations by leveraging historical check-in sequences. Although existing methods have shown promising results, they often struggle to capture complex high-order relationships and effectively adapt to diverse user behaviors, particularly when addressing the cold-start issue. To address these challenges, we propose Hypergraph-enhanced Meta-learning Adaptive Network (HyperMAN), a novel framework that integrates heterogeneous hypergraph modeling with a difficulty-aware meta-learning mechanism for next POI recommendation. Specifically, three types of heterogeneous hyperedges are designed to capture high-order relationships: user visit behaviors at specific times (Temporal behavioral hyperedge), spatial correlations among POIs (spatial functional hyperedge), and user long-term preferences (user preference hyperedge). Furthermore, a diversity-aware meta-learning mechanism is introduced to dynamically adjust learning strategies, considering users behavioral diversity. Extensive experiments on real-world datasets demonstrate that HyperMAN achieves superior performance, effectively addressing cold start challenges and significantly enhancing recommendation accuracy.
GRL-Prompt: Towards Knowledge Graph based Prompt Optimization via Reinforcement Learning
Nov 19, 2024



Large language models (LLMs) have demonstrated impressive success in a wide range of natural language processing (NLP) tasks due to their extensive general knowledge of the world. Recent works discovered that the performance of LLMs is heavily dependent on the input prompt. However, prompt engineering is usually done manually in a trial-and-error fashion, which can be labor-intensive and challenging in order to find the optimal prompts. To address these problems and unleash the utmost potential of LLMs, we propose a novel LLMs-agnostic framework for prompt optimization, namely GRL-Prompt, which aims to automatically construct optimal prompts via reinforcement learning (RL) in an end-to-end manner. To provide structured action/state representation for optimizing prompts, we construct a knowledge graph (KG) that better encodes the correlation between the user query and candidate in-context examples. Furthermore, a policy network is formulated to generate the optimal action by selecting a set of in-context examples in a rewardable order to construct the prompt. Additionally, the embedding-based reward shaping is utilized to stabilize the RL training process. The experimental results show that GRL-Prompt outperforms recent state-of-the-art methods, achieving an average increase of 0.10 in ROUGE-1, 0.07 in ROUGE-2, 0.07 in ROUGE-L, and 0.05 in BLEU.
Leveraging Auxiliary Task Relevance for Enhanced Industrial Fault Diagnosis through Curriculum Meta-learning
Oct 27, 2024The accurate diagnosis of machine breakdowns is crucial for maintaining operational safety in smart manufacturing. Despite the promise shown by deep learning in automating fault identification, the scarcity of labeled training data, particularly for equipment failure instances, poses a significant challenge. This limitation hampers the development of robust classification models. Existing methods like model-agnostic meta-learning (MAML) do not adequately address variable working conditions, affecting knowledge transfer. To address these challenges, a Related Task Aware Curriculum Meta-learning (RT-ACM) enhanced fault diagnosis framework is proposed in this paper, inspired by human cognitive learning processes. RT-ACM improves training by considering the relevance of auxiliary working conditions, adhering to the principle of ``paying more attention to more relevant knowledge", and focusing on ``easier first, harder later" curriculum sampling. This approach aids the meta-learner in achieving a superior convergence state. Extensive experiments on two real-world datasets demonstrate the superiority of RT-ACM framework.
Towards Secure and Efficient Data Scheduling for Vehicular Social Networks
Jun 28, 2024



Efficient data transmission scheduling within vehicular environments poses a significant challenge due to the high mobility of such networks. Contemporary research predominantly centers on crafting cooperative scheduling algorithms tailored for vehicular networks. Notwithstanding, the intricacies of orchestrating scheduling in vehicular social networks both effectively and efficiently remain formidable. This paper introduces an innovative learning-based algorithm for scheduling data transmission that prioritizes efficiency and security within vehicular social networks. The algorithm first uses a specifically constructed neural network to enhance data processing capabilities. After this, it incorporates a Q-learning paradigm during the data transmission phase to optimize the information exchange, the privacy of which is safeguarded by differential privacy through the communication process. Comparative experiments demonstrate the superior performance of the proposed Q-learning enhanced scheduling algorithm relative to existing state-of-the-art scheduling algorithms in the context of vehicular social networks.
Learning from Heterogeneity: A Dynamic Learning Framework for Hypergraphs
Jul 07, 2023
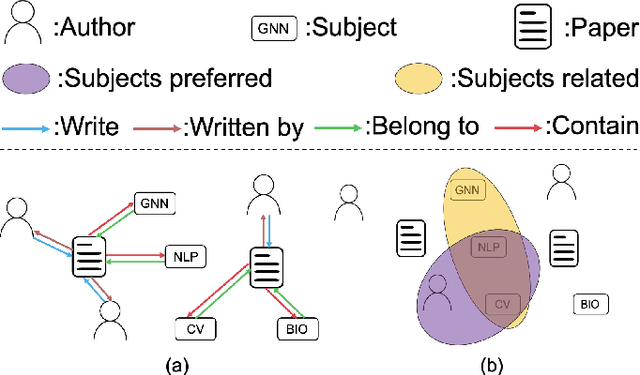
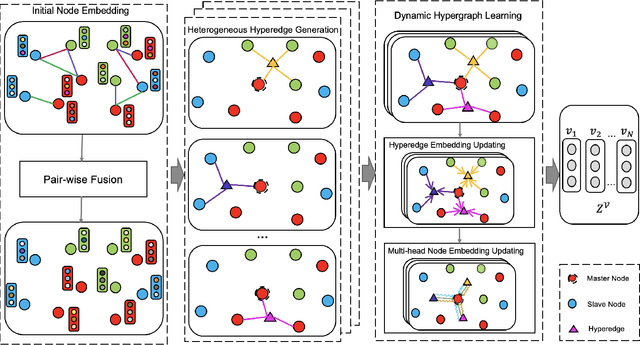
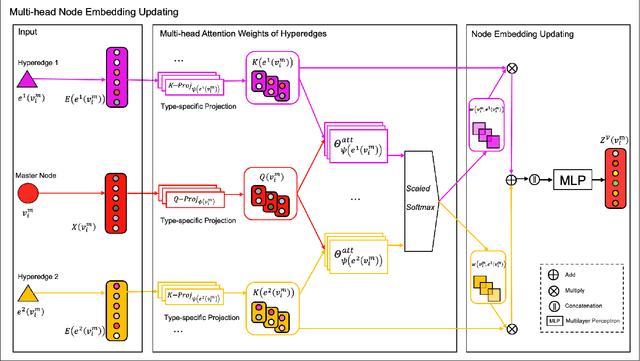
Graph neural network (GNN) has gained increasing popularity in recent years owing to its capability and flexibility in modeling complex graph structure data. Among all graph learning methods, hypergraph learning is a technique for exploring the implicit higher-order correlations when training the embedding space of the graph. In this paper, we propose a hypergraph learning framework named LFH that is capable of dynamic hyperedge construction and attentive embedding update utilizing the heterogeneity attributes of the graph. Specifically, in our framework, the high-quality features are first generated by the pairwise fusion strategy that utilizes explicit graph structure information when generating initial node embedding. Afterwards, a hypergraph is constructed through the dynamic grouping of implicit hyperedges, followed by the type-specific hypergraph learning process. To evaluate the effectiveness of our proposed framework, we conduct comprehensive experiments on several popular datasets with eleven state-of-the-art models on both node classification and link prediction tasks, which fall into categories of homogeneous pairwise graph learning, heterogeneous pairwise graph learning, and hypergraph learning. The experiment results demonstrate a significant performance gain (average 12.5% in node classification and 13.3% in link prediction) compared with recent state-of-the-art methods.
From Wide to Deep: Dimension Lifting Network for Parameter-efficient Knowledge Graph Embedding
Mar 22, 2023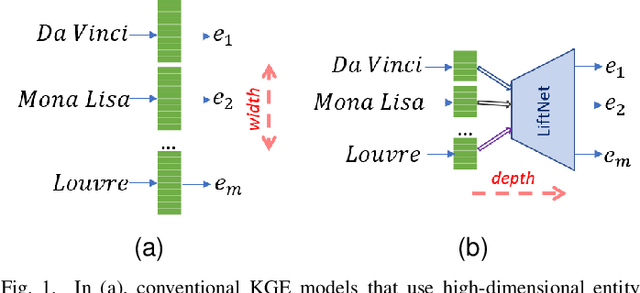
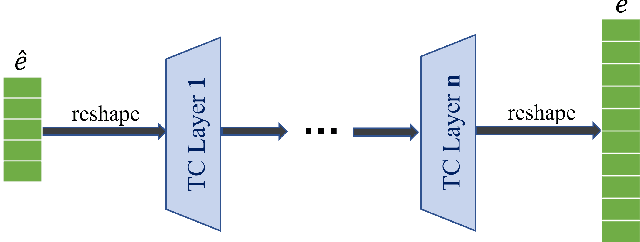
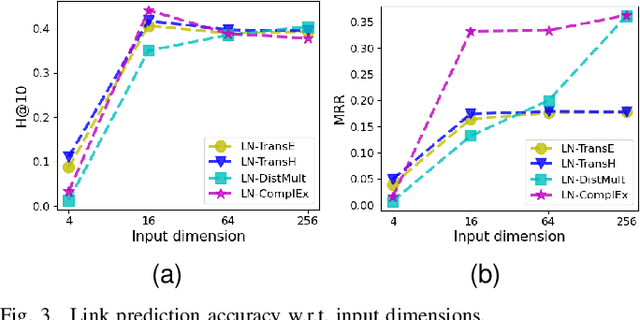
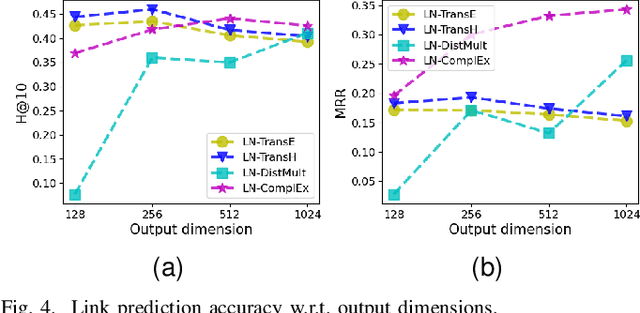
Knowledge graph embedding (KGE) that maps entities and relations into vector representations is essential for downstream tasks. Conventional KGE methods require relatively high-dimensional entity representations to preserve the structural information of knowledge graph, but lead to oversized model parameters. Recent methods reduce model parameters by adopting low-dimensional entity representations, while developing techniques (e.g., knowledge distillation) to compensate for the reduced dimension. However, such operations produce degraded model accuracy and limited reduction of model parameters. Specifically, we view the concatenation of all entity representations as an embedding layer, and then conventional KGE methods that adopt high-dimensional entity representations equal to enlarging the width of the embedding layer to gain expressiveness. To achieve parameter efficiency without sacrificing accuracy, we instead increase the depth and propose a deeper embedding network for entity representations, i.e., a narrow embedding layer and a multi-layer dimension lifting network (LiftNet). Experiments on three public datasets show that the proposed method (implemented based on TransE and DistMult) with 4-dimensional entity representations achieves more accurate link prediction results than counterpart parameter-efficient KGE methods and strong KGE baselines, including TransE and DistMult with 512-dimensional entity representations.
Towards Relation-centered Pooling and Convolution for Heterogeneous Graph Learning Networks
Oct 31, 2022


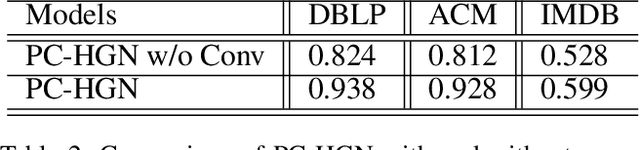
Heterogeneous graph neural network has unleashed great potential on graph representation learning and shown superior performance on downstream tasks such as node classification and clustering. Existing heterogeneous graph learning networks are primarily designed to either rely on pre-defined meta-paths or use attention mechanisms for type-specific attentive message propagation on different nodes/edges, incurring many customization efforts and computational costs. To this end, we design a relation-centered Pooling and Convolution for Heterogeneous Graph learning Network, namely PC-HGN, to enable relation-specific sampling and cross-relation convolutions, from which the structural heterogeneity of the graph can be better encoded into the embedding space through the adaptive training process. We evaluate the performance of the proposed model by comparing with state-of-the-art graph learning models on three different real-world datasets, and the results show that PC-HGN consistently outperforms all the baseline and improves the performance maximumly up by 17.8%.
Task Offloading with Multi-Tier Computing Resources in Next Generation Wireless Networks
May 27, 2022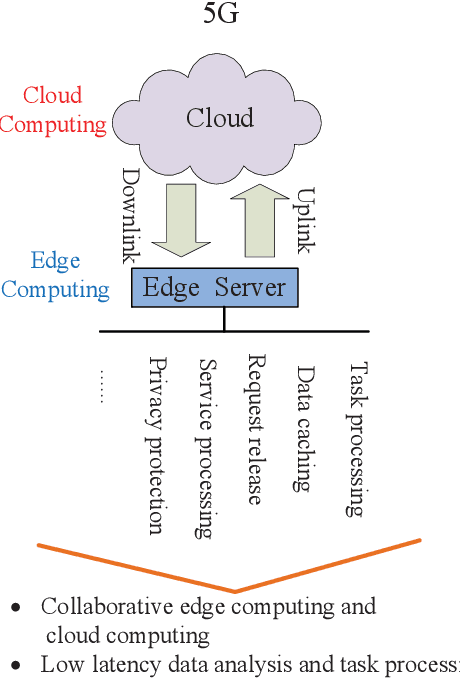
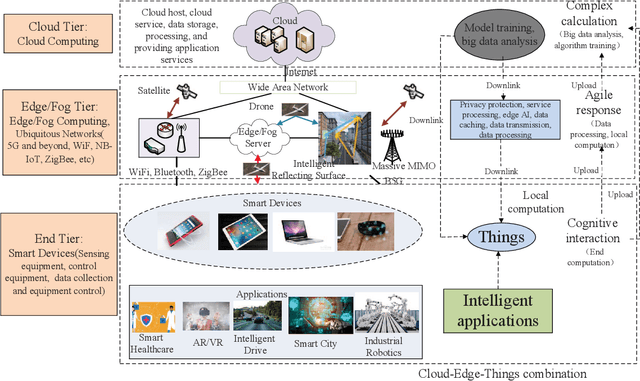
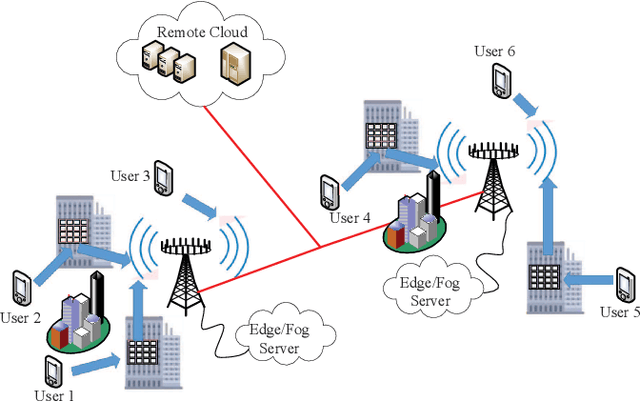
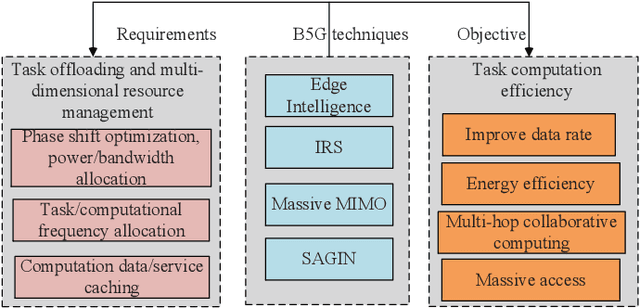
With the development of next-generation wireless networks, the Internet of Things (IoT) is evolving towards the intelligent IoT (iIoT), where intelligent applications usually have stringent delay and jitter requirements. In order to provide low-latency services to heterogeneous users in the emerging iIoT, multi-tier computing was proposed by effectively combining edge computing and fog computing. More specifically, multi-tier computing systems compensate for cloud computing through task offloading and dispersing computing tasks to multi-tier nodes along the continuum from the cloud to things. In this paper, we investigate key techniques and directions for wireless communications and resource allocation approaches to enable task offloading in multi-tier computing systems. A multi-tier computing model, with its main functionality and optimization methods, is presented in details. We hope that this paper will serve as a valuable reference and guide to the theoretical, algorithmic, and systematic opportunities of multi-tier computing towards next-generation wireless networks.