 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Partitioning Strategies on Energy Consumption in Distributed CNN Inference at The Edge
Oct 15, 2022

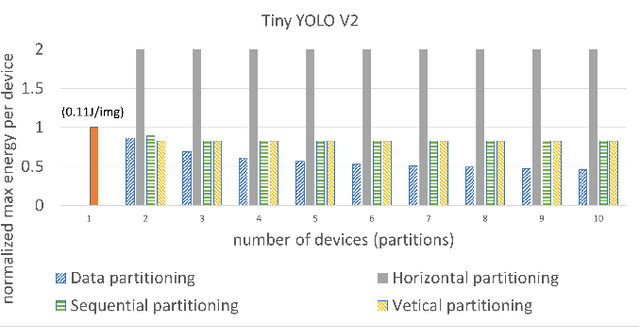

Nowadays, many AI applications utilizing resource-constrained edge devices (e.g., small mobile robots, tiny IoT devices, etc.) require Convolutional Neural Network (CNN) inference on a distributed system at the edge due to limited resources of a single edge device to accommodate and execute a large CNN. There are four main partitioning strategies that can be utilized to partition a large CNN model and perform distributed CNN inference on multiple devices at the edge. However, to the best of our knowledge, no research has been conducted to investigate how these four partitioning strategies affect the energy consumption per edge device. Such an investigation is important because it will reveal the potential of these partitioning strategies to be used effectively for reduction of the per-device energy consumption when a large CNN model is deployed for distributed inference at the edge. Therefore, in this paper, we investigate and compare the per-device energy consumption of CNN model inference at the edge on a distributed system when the four partitioning strategies are utilized. The goal of our investigation and comparison is to find out which partitioning strategies (and under what conditions) have the highest potential to decrease the energy consumption per edge device when CNN inference is performed at the edge on a distributed system.
AutoDiCE: Fully Automated Distributed CNN Inference at the Edge
Jul 20, 2022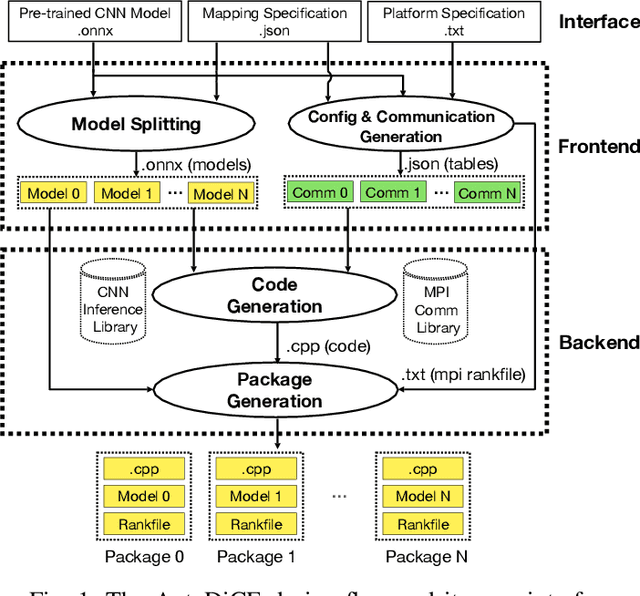
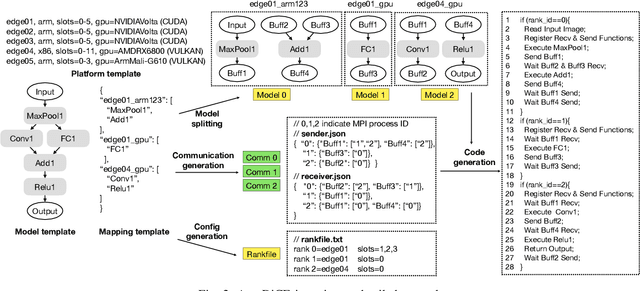
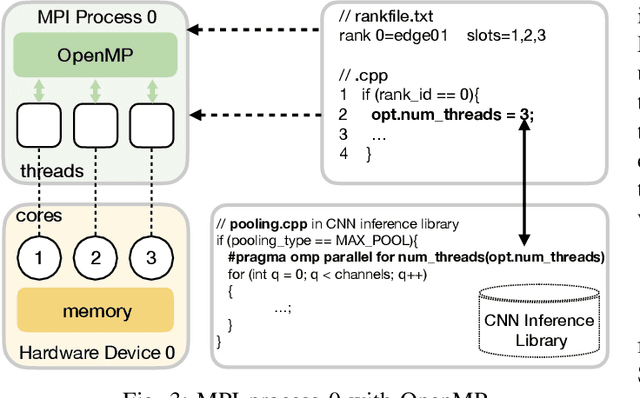
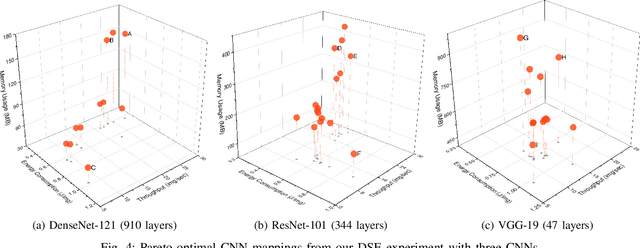
Deep Learning approaches based on Convolutional Neural Networks (CNNs) are extensively utilized and very successful in a wide range of application areas, including image classification and speech recognition. For the execution of trained CNNs, i.e. model inference, we nowadays witness a shift from the Cloud to the Edge. Unfortunately, deploying and inferring large, compute and memory intensive CNNs on edge devices is challenging because these devices typically have limited power budgets and compute/memory resources. One approach to address this challenge is to leverage all available resources across multiple edge devices to deploy and execute a large CNN by properly partitioning the CNN and running each CNN partition on a separate edge device. Although such distribution, deployment, and execution of large CNNs on multiple edge devices is a desirable and beneficial approach, there currently does not exist a design and programming framework that takes a trained CNN model, together with a CNN partitioning specification, and fully automates the CNN model splitting and deployment on multiple edge devices to facilitate distributed CNN inference at the Edge. Therefore, in this paper, we propose a novel framework, called AutoDiCE, for automated splitting of a CNN model into a set of sub-models and automated code generation for distributed and collaborative execution of these sub-models on multiple, possibly heterogeneous, edge devices, while supporting the exploitation of parallelism among and within the edge devices. Our experimental results show that AutoDiCE can deliver distributed CNN inference with reduced energy consumption and memory usage per edge device, and improved overall system throughput at the same time.