 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMAct: A Benchmark for In-Context Imitation Learning with Long Multimodal Demonstrations
Dec 02, 2024Today's largest foundation models have increasingly general capabilities, yet when used as agents, they often struggle with simple reasoning and decision-making tasks, even though they possess good factual knowledge of the task and how to solve it. In this paper, we present a benchmark to pressure-test these models' multimodal decision-making capabilities in the very long-context regime (up to one million tokens) and investigate whether they can learn from a large number of expert demonstrations in their context. We evaluate a wide range of state-of-the-art frontier models as policies across a battery of simple interactive decision-making tasks: playing tic-tac-toe, chess, and Atari, navigating grid worlds, solving crosswords, and controlling a simulated cheetah. We measure the performance of Claude 3.5 Sonnet, Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4o, o1-mini, and o1-preview under increasing amounts of expert demonstrations in the context $\unicode{x2013}$ from no demonstrations up to 512 full episodes, pushing these models' multimodal long-context reasoning capabilities to their limits. Across our tasks, today's frontier models rarely manage to fully reach expert performance, showcasing the difficulty of our benchmark. Presenting more demonstrations often has little effect, but some models steadily improve with more demonstrations on a few tasks. We investigate the effect of encoding observations as text or images and the impact of chain-of-thought prompting. Overall, our results suggest that even today's most capable models often struggle to imitate desired behavior by generalizing purely from in-context demonstrations. To help quantify the impact of other approaches and future innovations aiming to tackle this problem, we open source our benchmark that covers the zero-, few-, and many-shot regimes in a unified evaluation.
ElasticTok: Adaptive Tokenization for Image and Video
Oct 10, 2024



Efficient video tokenization remains a key bottleneck in learning general purpose vision models that are capable of processing long video sequences. Prevailing approaches are restricted to encoding videos to a fixed number of tokens, where too few tokens will result in overly lossy encodings, and too many tokens will result in prohibitively long sequence lengths. In this work, we introduce ElasticTok, a method that conditions on prior frames to adaptively encode a frame into a variable number of tokens. To enable this in a computationally scalable way, we propose a masking technique that drops a random number of tokens at the end of each frames's token encoding. During inference, ElasticTok can dynamically allocate tokens when needed -- more complex data can leverage more tokens, while simpler data only needs a few tokens. Our empirical evaluations on images and video demonstrate the effectiveness of our approach in efficient token usage, paving the way for future development of more powerful multimodal models, world models, and agents.
Vision-Language Models as a Source of Rewards
Dec 14, 2023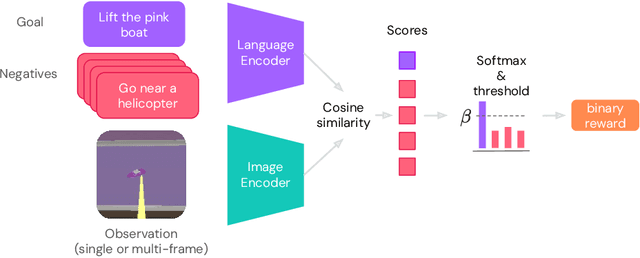
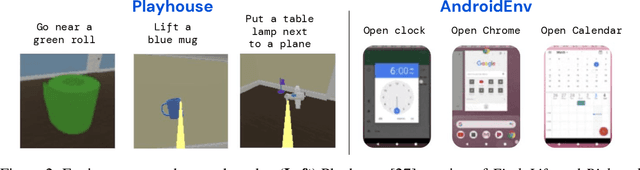
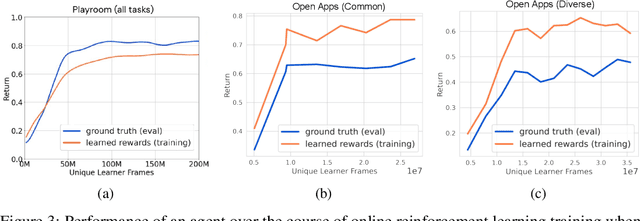
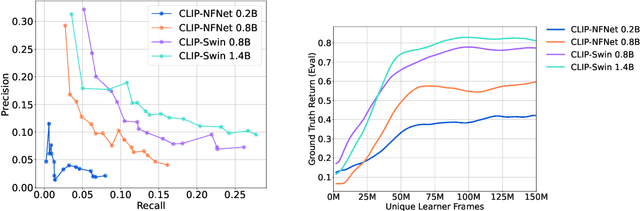
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
In-context Reinforcement Learning with Algorithm Distillation
Oct 25, 2022



We propose Algorithm Distillation (AD), a method for distilling reinforcement learning (RL) algorithms into neural networks by modeling their training histories with a causal sequence model. Algorithm Distillation treats learning to reinforcement learn as an across-episode sequential prediction problem. A dataset of learning histories is generated by a source RL algorithm, and then a causal transformer is trained by autoregressively predicting actions given their preceding learning histories as context. Unlike sequential policy prediction architectures that distill post-learning or expert sequences, AD is able to improve its policy entirely in-context without updating its network parameters. We demonstrate that AD can reinforcement learn in-context in a variety of environments with sparse rewards, combinatorial task structure, and pixel-based observations, and find that AD learns a more data-efficient RL algorithm than the one that generated the source data.
Wasserstein Distance Maximizing Intrinsic Control
Oct 28, 2021
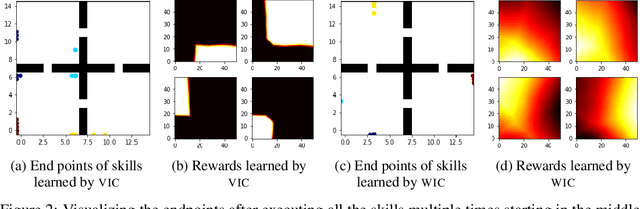

This paper deals with the problem of learning a skill-conditioned policy that acts meaningfully in the absence of a reward signal. Mutual information based objectives have shown some success in learning skills that reach a diverse set of states in this setting. These objectives include a KL-divergence term, which is maximized by visiting distinct states even if those states are not far apart in the MDP. This paper presents an approach that rewards the agent for learning skills that maximize the Wasserstein distance of their state visitation from the start state of the skill. It shows that such an objective leads to a policy that covers more distance in the MDP than diversity based objectives, and validates the results on a variety of Atari environments.
Discovering Diverse Nearly Optimal Policies withSuccessor Features
Jun 01, 2021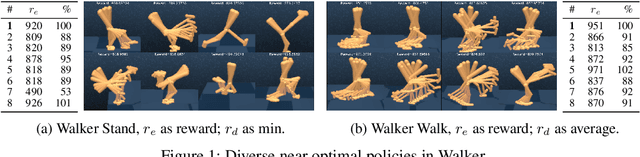


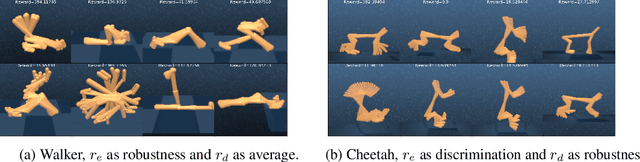
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose Diverse Successive Policies, a method for discovering policies that are diverse in the space of Successor Features, while assuring that they are near optimal. We formalize the problem as a Constrained Markov Decision Process (CMDP) where the goal is to find policies that maximize diversity, characterized by an intrinsic diversity reward, while remaining near-optimal with respect to the extrinsic reward of the MDP. We also analyze how recently proposed robustness and discrimination rewards perform and find that they are sensitive to the initialization of the procedure and may converge to sub-optimal solutions. To alleviate this, we propose new explicit diversity rewards that aim to minimize the correlation between the Successor Features of the policies in the set. We compare the different diversity mechanisms in the DeepMind Control Suite and find that the type of explicit diversity we are proposing is important to discover distinct behavior, like for example different locomotion patterns.
Relative Variational Intrinsic Control
Dec 14, 2020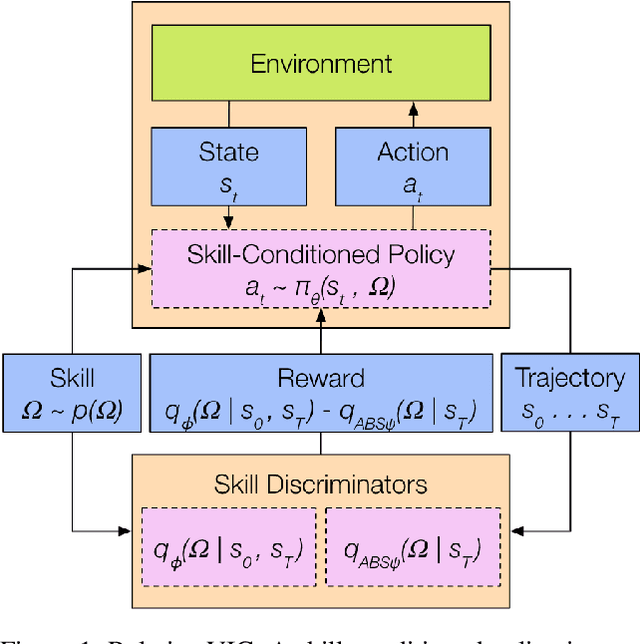
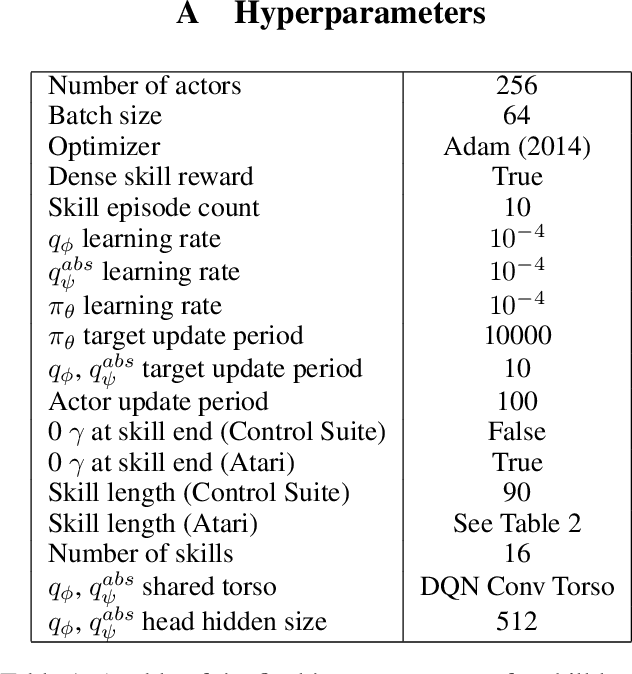
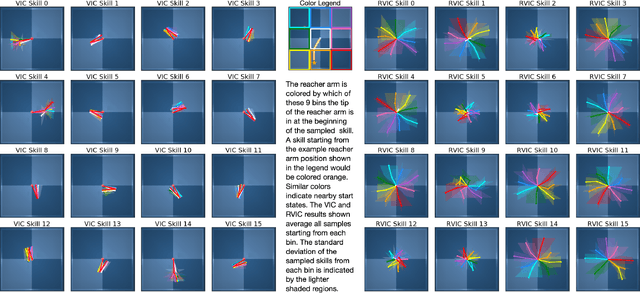
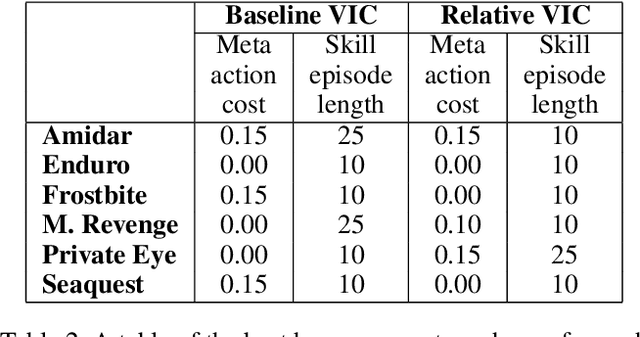
In the absence of external rewards, agents can still learn useful behaviors by identifying and mastering a set of diverse skills within their environment. Existing skill learning methods use mutual information objectives to incentivize each skill to be diverse and distinguishable from the rest. However, if care is not taken to constrain the ways in which the skills are diverse, trivially diverse skill sets can arise. To ensure useful skill diversity, we propose a novel skill learning objective, Relative Variational Intrinsic Control (RVIC), which incentivizes learning skills that are distinguishable in how they change the agent's relationship to its environment. The resulting set of skills tiles the space of affordances available to the agent. We qualitatively analyze skill behaviors on multiple environments and show how RVIC skills are more useful than skills discovered by existing methods when used in hierarchical reinforcement learning.
Q-Learning in enormous action spaces via amortized approximate maximization
Jan 22, 2020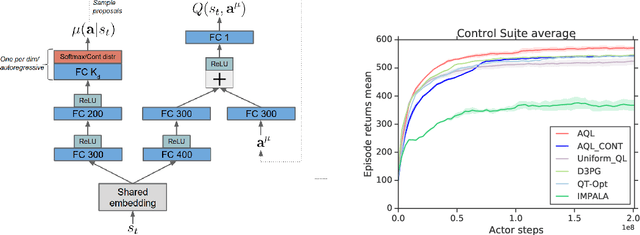

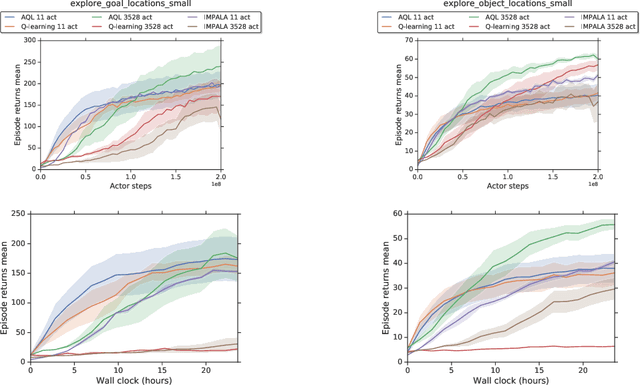

Applying Q-learning to high-dimensional or continuous action spaces can be difficult due to the required maximization over the set of possible actions. Motivated by techniques from amortized inference, we replace the expensive maximization over all actions with a maximization over a small subset of possible actions sampled from a learned proposal distribution. The resulting approach, which we dub Amortized Q-learning (AQL), is able to handle discrete, continuous, or hybrid action spaces while maintaining the benefits of Q-learning. Our experiments on continuous control tasks with up to 21 dimensional actions show that AQL outperforms D3PG (Barth-Maron et al, 2018) and QT-Opt (Kalashnikov et al, 2018). Experiments on structured discrete action spaces demonstrate that AQL can efficiently learn good policies in spaces with thousands of discrete actions.
Unsupervised Learning of Object Keypoints for Perception and Control
Jun 19, 2019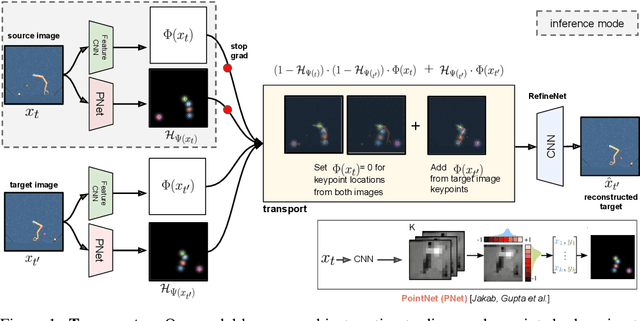

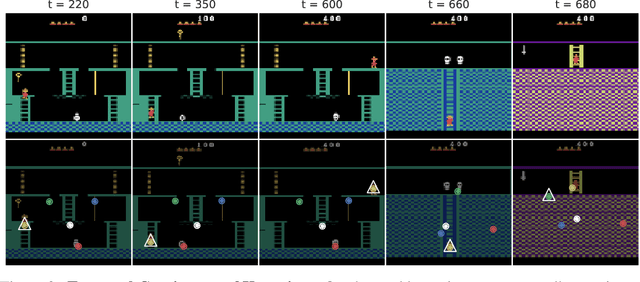
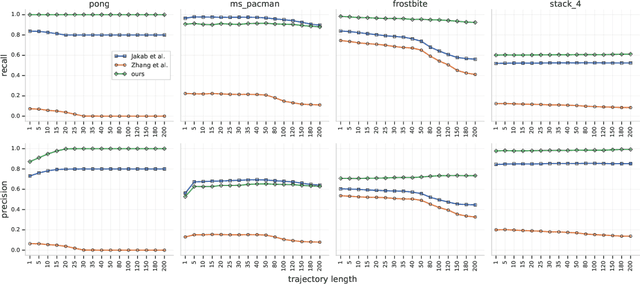
The study of object representations in computer vision has primarily focused on developing representations that are useful for image classification, object detection, or semantic segmentation as downstream tasks. In this work we aim to learn object representations that are useful for control and reinforcement learning (RL). To this end, we introduce Transporter, a neural network architecture for discovering concise geometric object representations in terms of keypoints or image-space coordinates. Our method learns from raw video frames in a fully unsupervised manner, by transporting learnt image features between video frames using a keypoint bottleneck. The discovered keypoints track objects and object parts across long time-horizons more accurately than recent similar methods. Furthermore, consistent long-term tracking enables two notable results in control domains -- (1) using the keypoint co-ordinates and corresponding image features as inputs enables highly sample-efficient reinforcement learning; (2) learning to explore by controlling keypoint locations drastically reduces the search space, enabling deep exploration (leading to states unreachable through random action exploration) without any extrinsic rewards.
Fast Task Inference with Variational Intrinsic Successor Features
Jun 12, 2019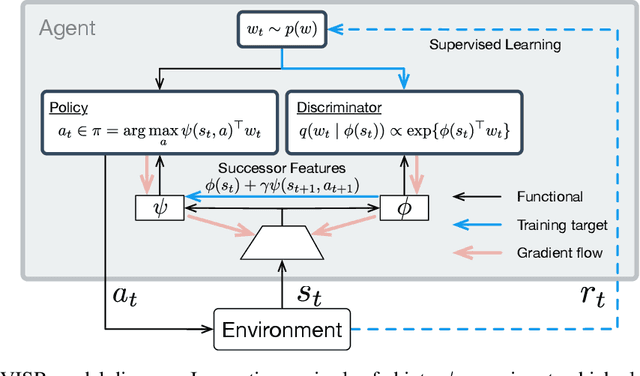
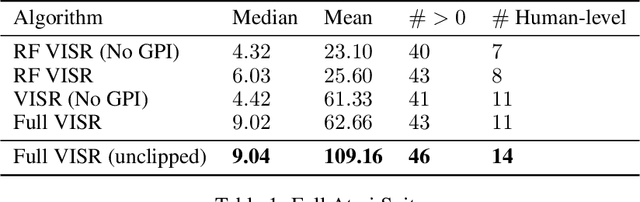
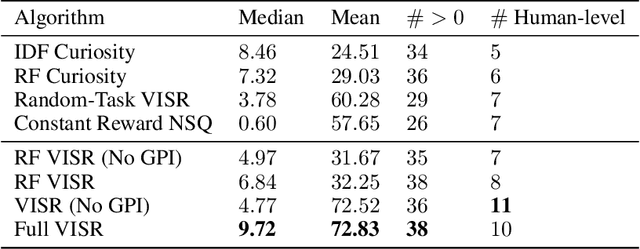
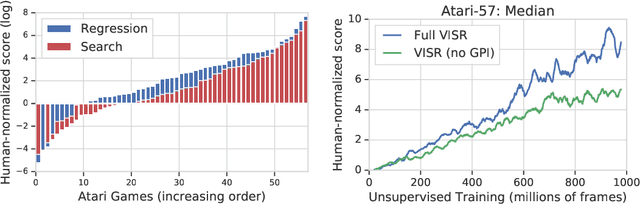
It has been established that diverse behaviors spanning the controllable subspace of an Markov decision process can be trained by rewarding a policy for being distinguishable from other policies \citep{gregor2016variational, eysenbach2018diversity, warde2018unsupervised}. However, one limitation of this formulation is generalizing behaviors beyond the finite set being explicitly learned, as is needed for use on subsequent tasks. Successor features \citep{dayan93improving, barreto2017successor} provide an appealing solution to this generalization problem, but require defining the reward function as linear in some grounded feature space. In this paper, we show that these two techniques can be combined, and that each method solves the other's primary limitation. To do so we introduce Variational Intrinsic Successor FeatuRes (VISR), a novel algorithm which learns controllable features that can be leveraged to provide enhanced generalization and fast task inference through the successor feature framework. We empirically validate VISR on the full Atari suite, in a novel setup wherein the rewards are only exposed briefly after a long unsupervised phase. Achieving human-level performance on 14 games and beating all baselines, we believe VISR represents a step towards agents that rapidly learn from limited feedback.