 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMAct: A Benchmark for In-Context Imitation Learning with Long Multimodal Demonstrations
Dec 02, 2024Today's largest foundation models have increasingly general capabilities, yet when used as agents, they often struggle with simple reasoning and decision-making tasks, even though they possess good factual knowledge of the task and how to solve it. In this paper, we present a benchmark to pressure-test these models' multimodal decision-making capabilities in the very long-context regime (up to one million tokens) and investigate whether they can learn from a large number of expert demonstrations in their context. We evaluate a wide range of state-of-the-art frontier models as policies across a battery of simple interactive decision-making tasks: playing tic-tac-toe, chess, and Atari, navigating grid worlds, solving crosswords, and controlling a simulated cheetah. We measure the performance of Claude 3.5 Sonnet, Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4o, o1-mini, and o1-preview under increasing amounts of expert demonstrations in the context $\unicode{x2013}$ from no demonstrations up to 512 full episodes, pushing these models' multimodal long-context reasoning capabilities to their limits. Across our tasks, today's frontier models rarely manage to fully reach expert performance, showcasing the difficulty of our benchmark. Presenting more demonstrations often has little effect, but some models steadily improve with more demonstrations on a few tasks. We investigate the effect of encoding observations as text or images and the impact of chain-of-thought prompting. Overall, our results suggest that even today's most capable models often struggle to imitate desired behavior by generalizing purely from in-context demonstrations. To help quantify the impact of other approaches and future innovations aiming to tackle this problem, we open source our benchmark that covers the zero-, few-, and many-shot regimes in a unified evaluation.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Vision-Language Models as a Source of Rewards
Dec 14, 2023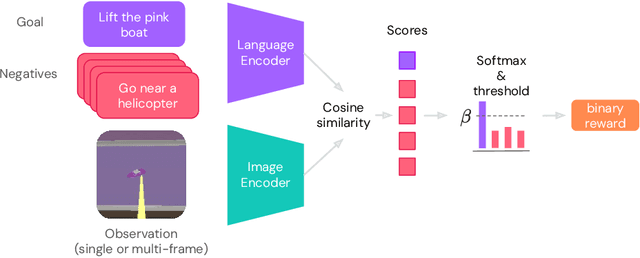
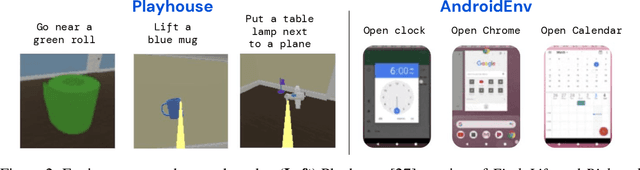
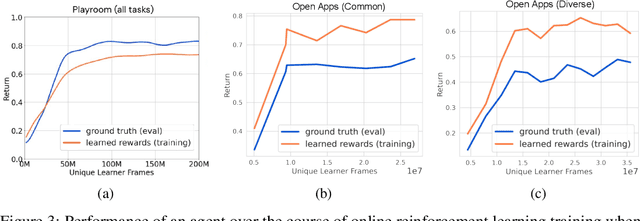
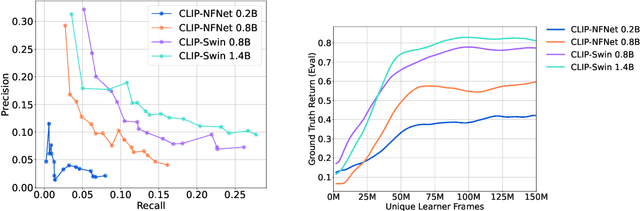
Building generalist agents that can accomplish many goals in rich open-ended environments is one of the research frontiers for reinforcement learning. A key limiting factor for building generalist agents with RL has been the need for a large number of reward functions for achieving different goals. We investigate the feasibility of using off-the-shelf vision-language models, or VLMs, as sources of rewards for reinforcement learning agents. We show how rewards for visual achievement of a variety of language goals can be derived from the CLIP family of models, and used to train RL agents that can achieve a variety of language goals. We showcase this approach in two distinct visual domains and present a scaling trend showing how larger VLMs lead to more accurate rewards for visual goal achievement, which in turn produces more capable RL agents.
OstrichRL: A Musculoskeletal Ostrich Simulation to Study Bio-mechanical Locomotion
Dec 11, 2021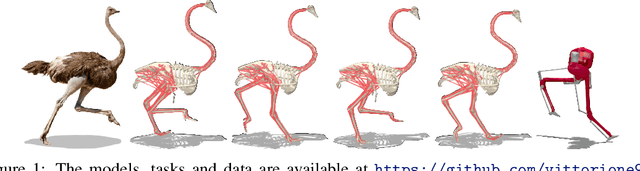
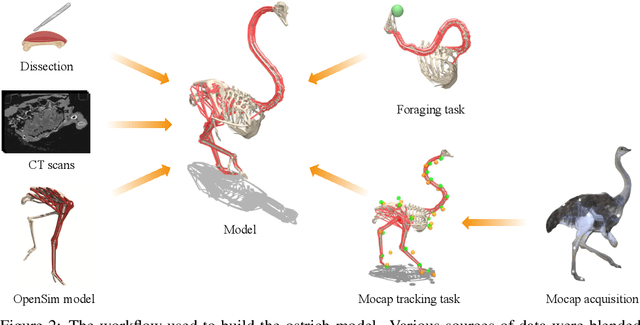
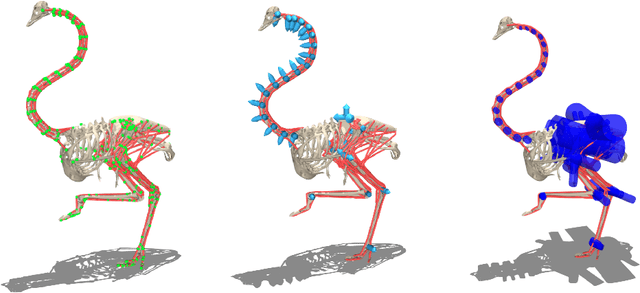
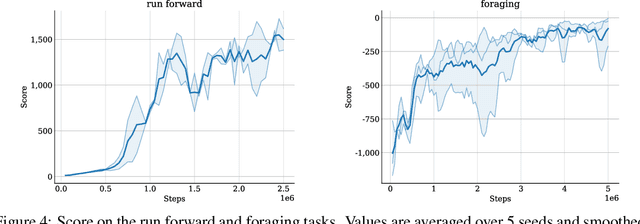
Muscle-actuated control is a research topic of interest spanning different fields, in particular biomechanics, robotics and graphics. This type of control is particularly challenging because models are often overactuated, and dynamics are delayed and non-linear. It is however a very well tested and tuned actuation model that has undergone millions of years of evolution and that involves interesting properties exploiting passive forces of muscle-tendon units and efficient energy storage and release. To facilitate research on muscle-actuated simulation, we release a 3D musculoskeletal simulation of an ostrich based on the MuJoCo simulator. Ostriches are one of the fastest bipeds on earth and are therefore an excellent model for studying muscle-actuated bipedal locomotion. The model is based on CT scans and dissections used to gather actual muscle data such as insertion sites, lengths and pennation angles. Along with this model, we also provide a set of reinforcement learning tasks, including reference motion tracking and a reaching task with the neck. The reference motion data are based on motion capture clips of various behaviors which we pre-processed and adapted to our model. This paper describes how the model was built and iteratively improved using the tasks. We evaluate the accuracy of the muscle actuation patterns by comparing them to experimentally collected electromyographic data from locomoting birds. We believe that this work can be a useful bridge between the biomechanics, reinforcement learning, graphics and robotics communities, by providing a fast and easy to use simulation.
Ivy: Templated Deep Learning for Inter-Framework Portability
Feb 15, 2021

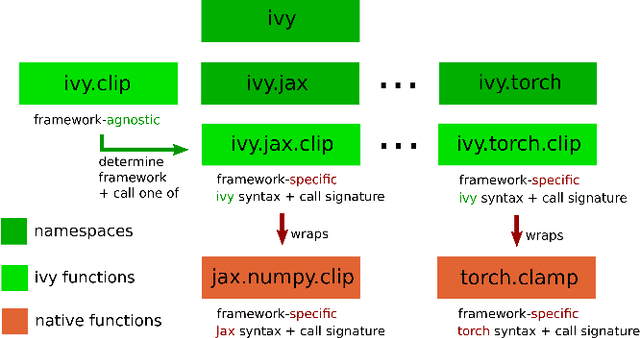

We introduce Ivy, a templated Deep Learning (DL) framework which abstracts existing DL frameworks such that their core functions all exhibit consistent call signatures, syntax and input-output behaviour. Ivy allows high-level framework-agnostic functions to be implemented through the use of framework templates. The framework templates act as placeholders for the specific framework at development time, which are then determined at runtime. The portability of Ivy functions enables their use in projects of any supported framework. Ivy currently supports TensorFlow, PyTorch, MXNet, Jax and NumPy. Alongside Ivy, we release four pure-Ivy libraries for mechanics, 3D vision, robotics, and differentiable environments. Through our evaluations, we show that Ivy can significantly reduce lines of code with a runtime overhead of less than 1% in most cases. We welcome developers to join the Ivy community by writing their own functions, layers and libraries in Ivy, maximizing their audience and helping to accelerate DL research through the creation of lifelong inter-framework codebases. More information can be found at https://ivy-dl.org.
Tonic: A Deep Reinforcement Learning Library for Fast Prototyping and Benchmarking
Nov 15, 2020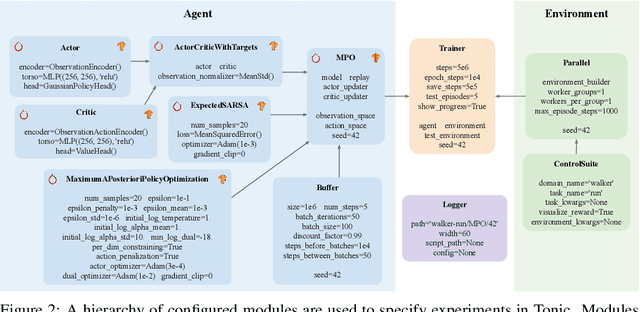

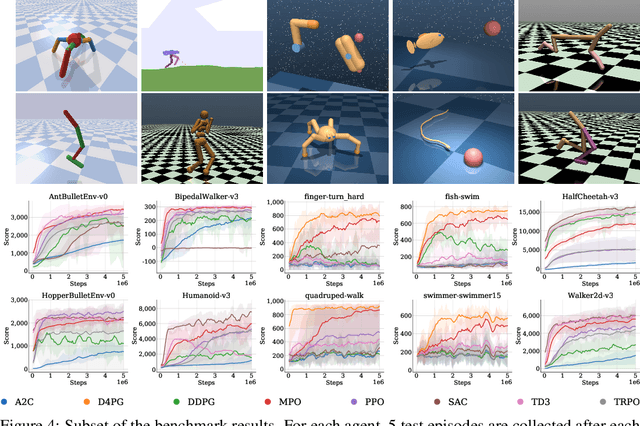
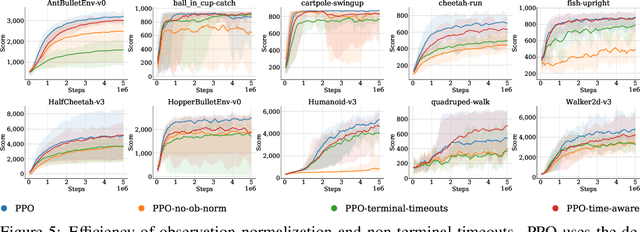
Deep reinforcement learning has been one of the fastest growing fields of machine learning over the past years and numerous libraries have been open sourced to support research. However, most codebases have a steep learning curve or limited flexibility that do not satisfy a need for fast prototyping in fundamental research. This paper introduces Tonic, a Python library allowing researchers to quickly implement new ideas and measure their importance by providing: 1) a collection of configurable modules such as exploration strategies, replays, neural networks, and updaters 2) a collection of baseline agents: A2C, TRPO, PPO, MPO, DDPG, D4PG, TD3 and SAC built with these modules 3) support for the two most popular deep learning frameworks: TensorFlow 2 and PyTorch 4) support for the three most popular sets of continuous-control environments: OpenAI Gym, DeepMind Control Suite and PyBullet 5) a large-scale benchmark of the baseline agents on 70 continuous-control tasks 6) scripts to experiment in a reproducible way, plot results, and play with trained agents.
Goal-oriented Trajectories for Efficient Exploration
Jul 05, 2018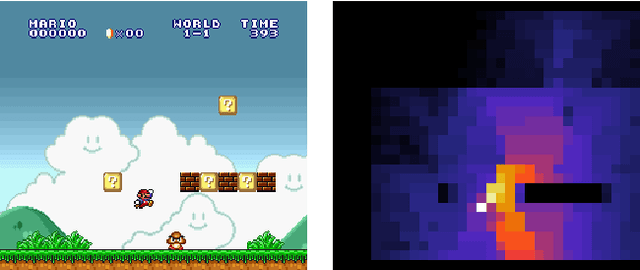
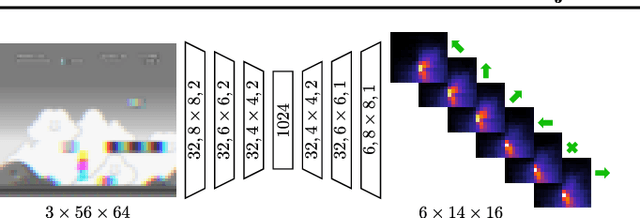

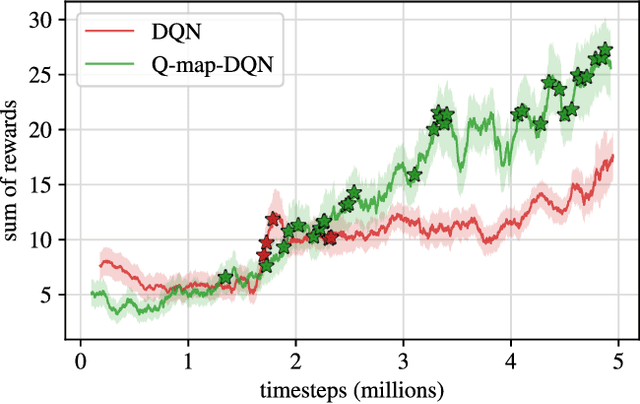
Exploration is a difficult challenge in reinforcement learning and even recent state-of-the art curiosity-based methods rely on the simple epsilon-greedy strategy to generate novelty. We argue that pure random walks do not succeed to properly expand the exploration area in most environments and propose to replace single random action choices by random goals selection followed by several steps in their direction. This approach is compatible with any curiosity-based exploration and off-policy reinforcement learning agents and generates longer and safer trajectories than individual random actions. To illustrate this, we present a task-independent agent that learns to reach coordinates in screen frames and demonstrate its ability to explore with the game Super Mario Bros. improving significantly the score of a baseline DQN agent.
Time Limits in Reinforcement Learning
Jul 05, 2018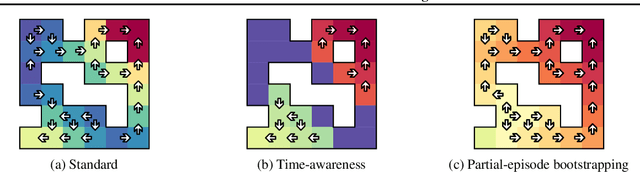
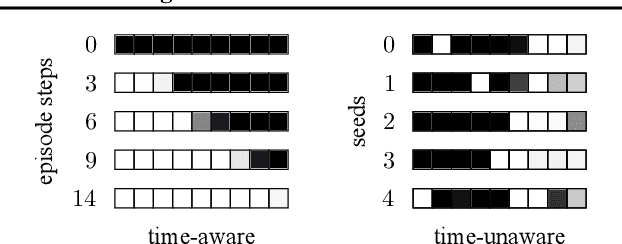
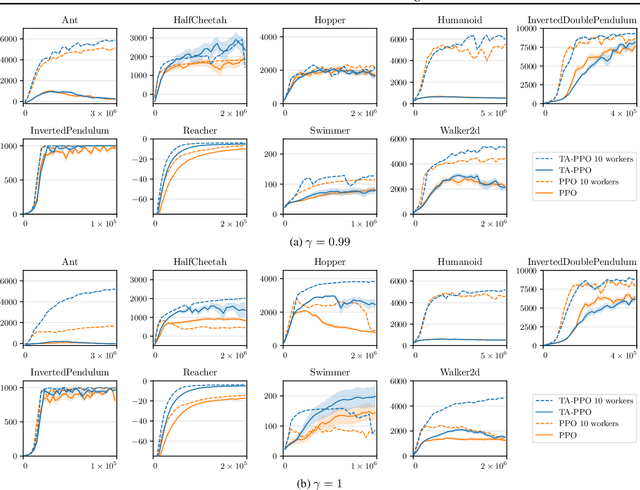
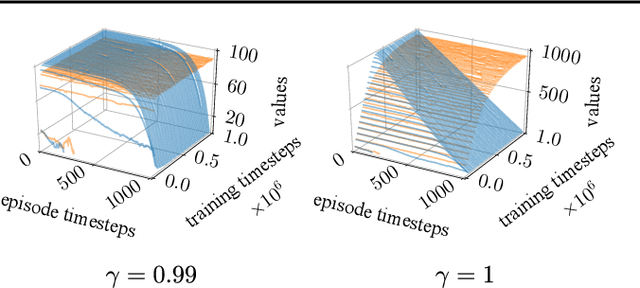
In reinforcement learning, it is common to let an agent interact for a fixed amount of time with its environment before resetting it and repeating the process in a series of episodes. The task that the agent has to learn can either be to maximize its performance over (i) that fixed period, or (ii) an indefinite period where time limits are only used during training to diversify experience. In this paper, we provide a formal account for how time limits could effectively be handled in each of the two cases and explain why not doing so can cause state-aliasing and invalidation of experience replay, leading to suboptimal policies and training instability. In case (i), we argue that the terminations due to time limits are in fact part of the environment, and thus a notion of the remaining time should be included as part of the agent's input to avoid violation of the Markov property. In case (ii), the time limits are not part of the environment and are only used to facilitate learning. We argue that this insight should be incorporated by bootstrapping from the value of the state at the end of each partial episode. For both cases, we illustrate empirically the significance of our considerations in improving the performance and stability of existing reinforcement learning algorithms, showing state-of-the-art results on several control tasks.
* ICML 2018, NIPS 2017 Deep RL Symposium, code and videos: https://sites.google.com/view/time-limits-in-rl
Action Branching Architectures for Deep Reinforcement Learning
Nov 24, 2017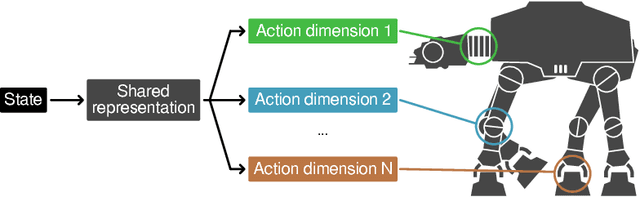

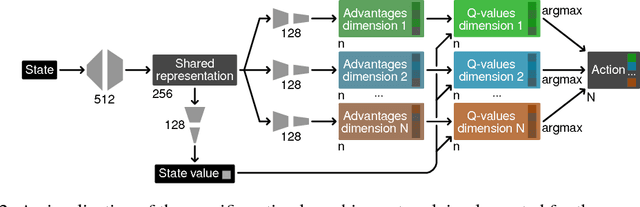
Discrete-action algorithms have been central to numerous recent successes of deep reinforcement learning. However, applying these algorithms to high-dimensional action tasks requires tackling the combinatorial increase of the number of possible actions with the number of action dimensions. This problem is further exacerbated for continuous-action tasks that require fine control of actions via discretization. In this paper, we propose a novel neural architecture featuring a shared decision module followed by several network branches, one for each action dimension. This approach achieves a linear increase of the number of network outputs with the number of degrees of freedom by allowing a level of independence for each individual action dimension. To illustrate the approach, we present a novel agent, called Branching Dueling Q-Network (BDQ), as a branching variant of the Dueling Double Deep Q-Network (Dueling DDQN). We evaluate the performance of our agent on a set of challenging continuous control tasks. The empirical results show that the proposed agent scales gracefully to environments with increasing action dimensionality and indicate the significance of the shared decision module in coordination of the distributed action branches. Furthermore, we show that the proposed agent performs competitively against a state-of-the-art continuous control algorithm, Deep Deterministic Policy Gradient (DDPG).