 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Hybrid Zero Dynamics for Bipedal Walking of the Knee-less Robot SLIDER
Apr 01, 2025Knee-less bipedal robots like SLIDER have the advantage of ultra-lightweight legs and improved walking energy efficiency compared to traditional humanoid robots. In this paper, we firstly introduce an improved hardware design of the bipedal robot SLIDER with new line-feet and more optimized mass distribution which enables higher locomotion speeds. Secondly, we propose an extended Hybrid Zero Dynamics (eHZD) method, which can be applied to prismatic joint robots like SLIDER. The eHZD method is then used to generate a library of gaits with varying reference velocities in an offline way. Thirdly, a Guided Deep Reinforcement Learning (DRL) algorithm is proposed to use the pre-generated library to create walking control policies in real-time. This approach allows us to combine the advantages of both HZD (for generating stable gaits with a full-dynamics model) and DRL (for real-time adaptive gait generation). The experimental results show that this approach achieves 150% higher walking velocity than the previous MPC-based approach.
Haptic-ACT: Bridging Human Intuition with Compliant Robotic Manipulation via Immersive VR
Sep 18, 2024



Robotic manipulation is essential for the widespread adoption of robots in industrial and home settings and has long been a focus within the robotics community. Advances in artificial intelligence have introduced promising learning-based methods to address this challenge, with imitation learning emerging as particularly effective. However, efficiently acquiring high-quality demonstrations remains a challenge. In this work, we introduce an immersive VR-based teleoperation setup designed to collect demonstrations from a remote human user. We also propose an imitation learning framework called Haptic Action Chunking with Transformers (Haptic-ACT). To evaluate the platform, we conducted a pick-and-place task and collected 50 demonstration episodes. Results indicate that the immersive VR platform significantly reduces demonstrator fingertip forces compared to systems without haptic feedback, enabling more delicate manipulation. Additionally, evaluations of the Haptic-ACT framework in both the MuJoCo simulator and on a real robot demonstrate its effectiveness in teaching robots more compliant manipulation compared to the original ACT. Additional materials are available at https://sites.google.com/view/hapticact.
A Backbone for Long-Horizon Robot Task Understanding
Aug 07, 2024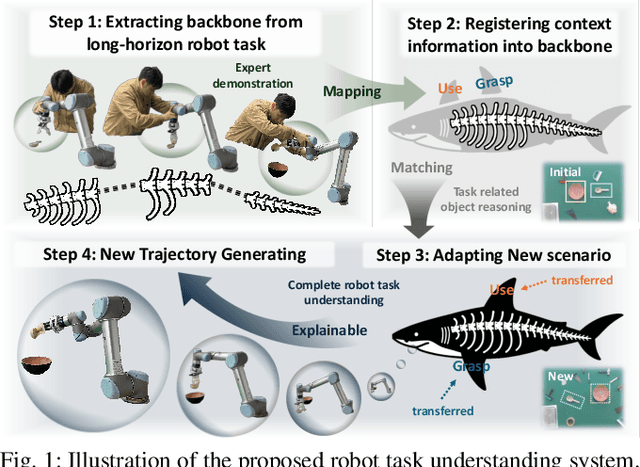
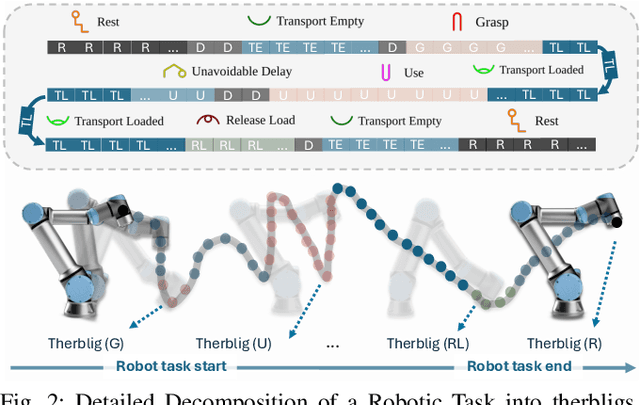
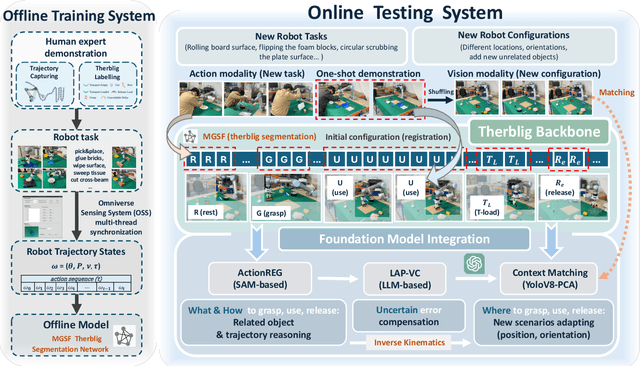
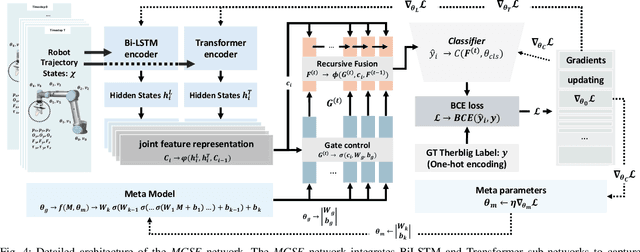
End-to-end robot learning, particularly for long-horizon tasks, often results in unpredictable outcomes and poor generalization. To address these challenges, we propose a novel Therblig-based Backbone Framework (TBBF) to enhance robot task understanding and transferability. This framework uses therbligs (basic action elements) as the backbone to decompose high-level robot tasks into elemental robot configurations, which are then integrated with current foundation models to improve task understanding. The approach consists of two stages: offline training and online testing. During the offline training stage, we developed the Meta-RGate SynerFusion (MGSF) network for accurate therblig segmentation across various tasks. In the online testing stage, after a one-shot demonstration of a new task is collected, our MGSF network extracts high-level knowledge, which is then encoded into the image using Action Registration (ActionREG). Additionally, the Large Language Model (LLM)-Alignment Policy for Visual Correction (LAP-VC) is employed to ensure precise action execution, facilitating trajectory transfer in novel robot scenarios. Experimental results validate these methods, achieving 94.37% recall in therblig segmentation and success rates of 94.4% and 80% in real-world online robot testing for simple and complex scenarios, respectively. Supplementary material is available at: https://sites.google.com/view/therbligsbasedbackbone/home
The Hydra Hand: A Mode-Switching Underactuated Gripper with Precision and Power Grasping Modes
Sep 26, 2023Human hands are able to grasp a wide range of object sizes, shapes, and weights, achieved via reshaping and altering their apparent grasping stiffness between compliant power and rigid precision. Achieving similar versatility in robotic hands remains a challenge, which has often been addressed by adding extra controllable degrees of freedom, tactile sensors, or specialised extra grasping hardware, at the cost of control complexity and robustness. We introduce a novel reconfigurable four-fingered two-actuator underactuated gripper -- the Hydra Hand -- that switches between compliant power and rigid precision grasps using a single motor, while generating grasps via a single hydraulic actuator -- exhibiting adaptive grasping between finger pairs, enabling the power grasping of two objects simultaneously. The mode switching mechanism and the hand's kinematics are presented and analysed, and performance is tested on two grasping benchmarks: one focused on rigid objects, and the other on items of clothing. The Hydra Hand is shown to excel at grasping large and irregular objects, and small objects with its respective compliant power and rigid precision configurations. The hand's versatility is then showcased by executing the challenging manipulation task of safely grasping and placing a bunch of grapes, and then plucking a single grape from the bunch.
When and Where to Step: Terrain-Aware Real-Time Footstep Location and Timing Optimization for Bipedal Robots
Feb 14, 2023



Online footstep planning is essential for bipedal walking robots, allowing them to walk in the presence of disturbances and sensory noise. Most of the literature on the topic has focused on optimizing the footstep placement while keeping the step timing constant. In this work, we introduce a footstep planner capable of optimizing footstep placement and step time online. The proposed planner, consisting of an Interior Point Optimizer (IPOPT) and an optimizer based on Augmented Lagrangian (AL) method with analytical gradient descent, solves the full dynamics of the Linear Inverted Pendulum (LIP) model in real time to optimize for footstep location as well as step timing at the rate of 200~Hz. We show that such asynchronous real-time optimization with the AL method (ARTO-AL) provides the required robustness and speed for successful online footstep planning. Furthermore, ARTO-AL can be extended to plan footsteps in 3D, allowing terrain-aware footstep planning on uneven terrains. Compared to an algorithm with no footstep time adaptation, our proposed ARTO-AL demonstrates increased stability in simulated walking experiments as it can resist pushes on flat ground and on a $10^{\circ}$ ramp up to 120 N and 100 N respectively. For the video, see https://youtu.be/ABdnvPqCUu4. For code, see https://github.com/WangKeAlchemist/ARTO-AL/tree/master.
OstrichRL: A Musculoskeletal Ostrich Simulation to Study Bio-mechanical Locomotion
Dec 11, 2021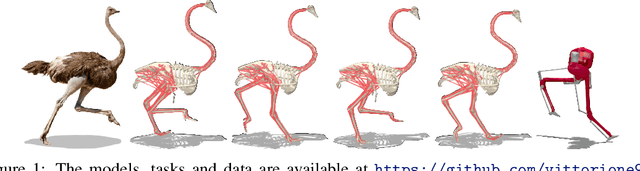
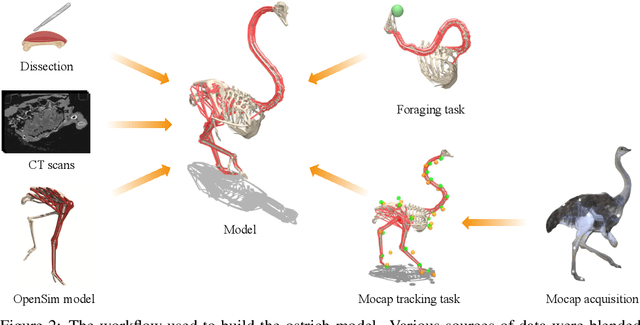
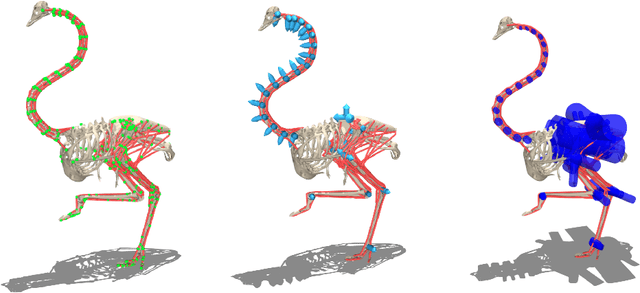
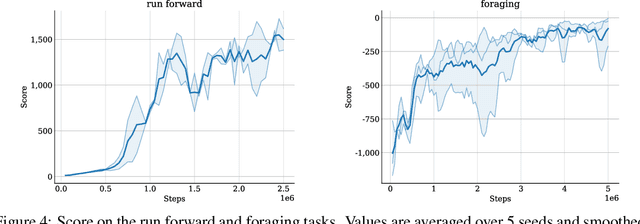
Muscle-actuated control is a research topic of interest spanning different fields, in particular biomechanics, robotics and graphics. This type of control is particularly challenging because models are often overactuated, and dynamics are delayed and non-linear. It is however a very well tested and tuned actuation model that has undergone millions of years of evolution and that involves interesting properties exploiting passive forces of muscle-tendon units and efficient energy storage and release. To facilitate research on muscle-actuated simulation, we release a 3D musculoskeletal simulation of an ostrich based on the MuJoCo simulator. Ostriches are one of the fastest bipeds on earth and are therefore an excellent model for studying muscle-actuated bipedal locomotion. The model is based on CT scans and dissections used to gather actual muscle data such as insertion sites, lengths and pennation angles. Along with this model, we also provide a set of reinforcement learning tasks, including reference motion tracking and a reaching task with the neck. The reference motion data are based on motion capture clips of various behaviors which we pre-processed and adapted to our model. This paper describes how the model was built and iteratively improved using the tasks. We evaluate the accuracy of the muscle actuation patterns by comparing them to experimentally collected electromyographic data from locomoting birds. We believe that this work can be a useful bridge between the biomechanics, reinforcement learning, graphics and robotics communities, by providing a fast and easy to use simulation.
Fast Online Optimization for Terrain-Blind Bipedal Robot Walking with a Decoupled Actuated SLIP Model
Sep 20, 2021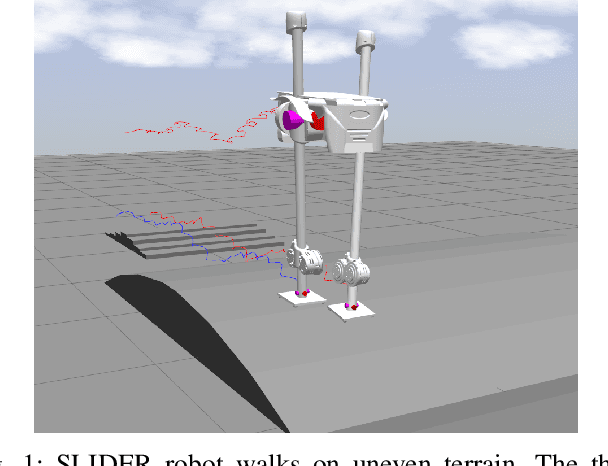
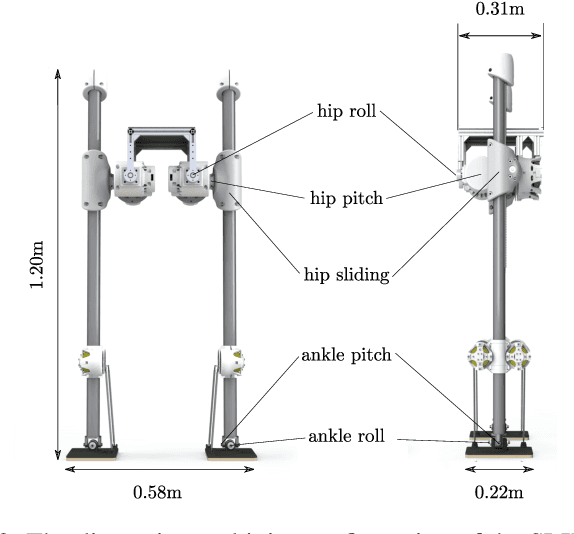
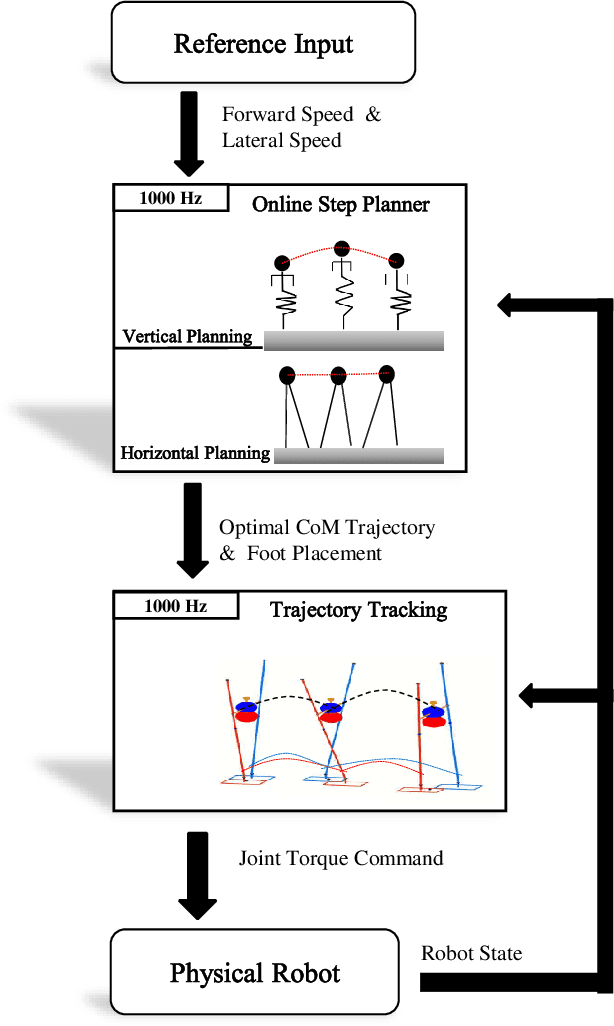
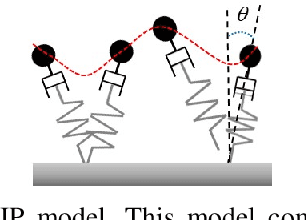
We present a highly reactive controller which enables bipedal robots to blindly walk over various kinds of uneven terrains while resisting pushes. The high level motion planner does fast online optimization for footstep locations and Center of Mass (CoM) height using the decoupled actuated Spring Loaded Inverted Pendulum (aSLIP) model. The decoupled aSLIP model simplifies the original aSLIP with Linear Inverted Pendulum (LIP) dynamics in horizontal states and spring dynamics in the vertical state. The motion planning can be formulated as a discrete-time Model Predictive Control (MPC) and solved at a frequency of 1k~HZ. The output of the motion planner using a reduced-order model is fed into an inverse-dynamics based whole body controller for execution on the robot. A key result of this controller is that the foot of the robot is compliant, which further extends the robot's ability to be robust to unobserved terrain changes. We evaluate our method in simulation with the bipedal robot SLIDER. Results show the robot can blindly walk over various uneven terrains including slopes, wave fields and stairs. It can also resist pushes while walking on uneven terrain.
A Unified Model with Inertia Shaping for Highly Dynamic Jumps of Legged Robots
Sep 09, 2021

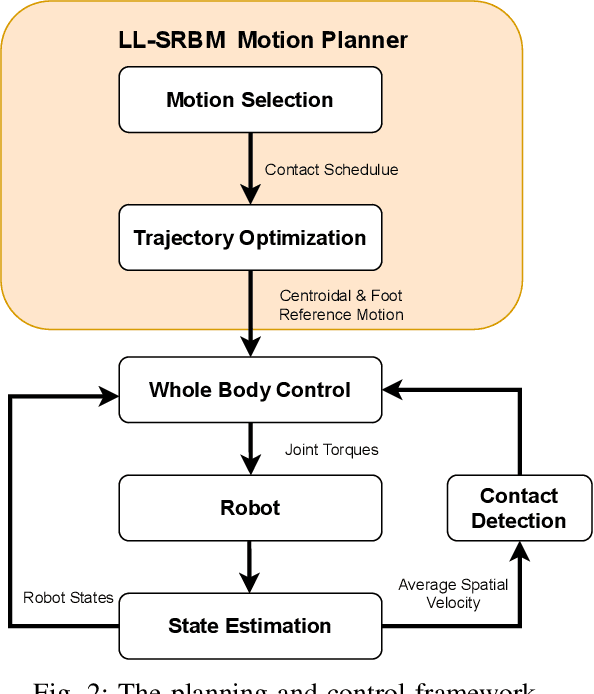

To achieve highly dynamic jumps of legged robots, it is essential to control the rotational dynamics of the robot. In this paper, we aim to improve the jumping performance by proposing a unified model for planning highly dynamic jumps that can approximately model the centroidal inertia. This model abstracts the robot as a single rigid body for the base and point masses for the legs. The model is called the Lump Leg Single Rigid Body Model (LL-SRBM) and can be used to plan motions for both bipedal and quadrupedal robots. By taking the effects of leg dynamics into account, LL-SRBM provides a computationally efficient way for the motion planner to change the centroidal inertia of the robot with various leg configurations. Concurrently, we propose a novel contact detection method by using the norm of the average spatial velocity. After the contact is detected, the controller is switched to force control to achieve a soft landing. Twisting jump and forward jump experiments on the bipedal robot SLIDER and quadrupedal robot ANYmal demonstrate the improved jump performance by actively changing the centroidal inertia. These experiments also show the generalization and the robustness of the integrated planning and control framework.
Policy Manifold Search: Exploring the Manifold Hypothesis for Diversity-based Neuroevolution
Apr 27, 2021


Neuroevolution is an alternative to gradient-based optimisation that has the potential to avoid local minima and allows parallelisation. The main limiting factor is that usually it does not scale well with parameter space dimensionality. Inspired by recent work examining neural network intrinsic dimension and loss landscapes, we hypothesise that there exists a low-dimensional manifold, embedded in the policy network parameter space, around which a high-density of diverse and useful policies are located. This paper proposes a novel method for diversity-based policy search via Neuroevolution, that leverages learned representations of the policy network parameters, by performing policy search in this learned representation space. Our method relies on the Quality-Diversity (QD) framework which provides a principled approach to policy search, and maintains a collection of diverse policies, used as a dataset for learning policy representations. Further, we use the Jacobian of the inverse-mapping function to guide the search in the representation space. This ensures that the generated samples remain in the high-density regions, after mapping back to the original space. Finally, we evaluate our contributions on four continuous-control tasks in simulated environments, and compare to diversity-based baselines.
Policy Manifold Search for Improving Diversity-based Neuroevolution
Dec 15, 2020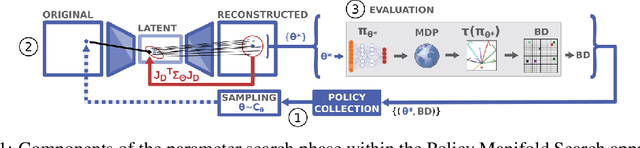


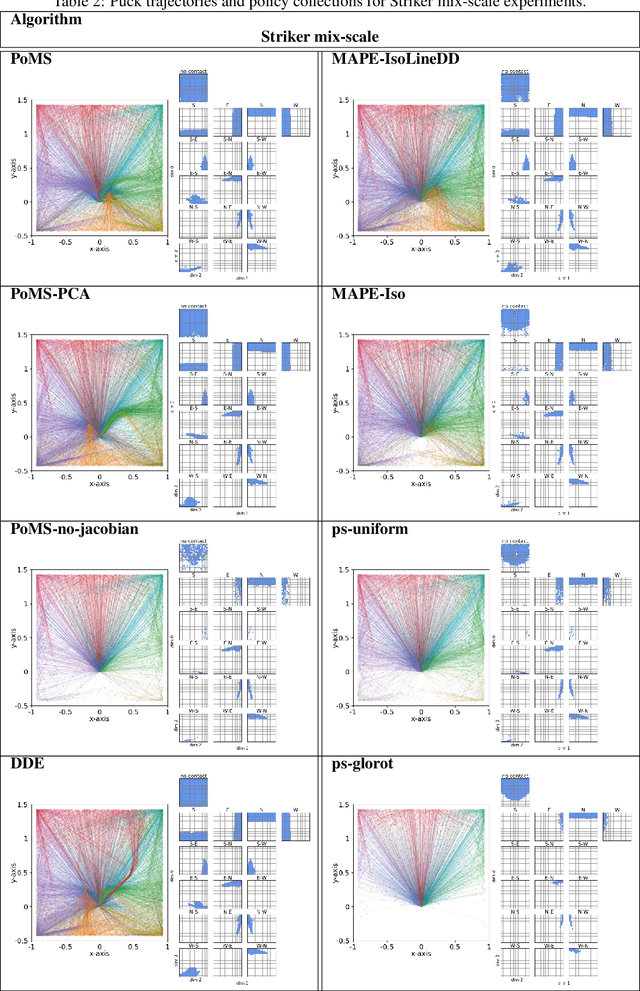
Diversity-based approaches have recently gained popularity as an alternative paradigm to performance-based policy search. A popular approach from this family, Quality-Diversity (QD), maintains a collection of high-performing policies separated in the diversity-metric space, defined based on policies' rollout behaviours. When policies are parameterised as neural networks, i.e. Neuroevolution, QD tends to not scale well with parameter space dimensionality. Our hypothesis is that there exists a low-dimensional manifold embedded in the policy parameter space, containing a high density of diverse and feasible policies. We propose a novel approach to diversity-based policy search via Neuroevolution, that leverages learned latent representations of the policy parameters which capture the local structure of the data. Our approach iteratively collects policies according to the QD framework, in order to (i) build a collection of diverse policies, (ii) use it to learn a latent representation of the policy parameters, (iii) perform policy search in the learned latent space. We use the Jacobian of the inverse transformation (i.e.reconstruction function) to guide the search in the latent space. This ensures that the generated samples remain in the high-density regions of the original space, after reconstruction. We evaluate our contributions on three continuous control tasks in simulated environments, and compare to diversity-based baselines. The findings suggest that our approach yields a more efficient and robust policy search process.