 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023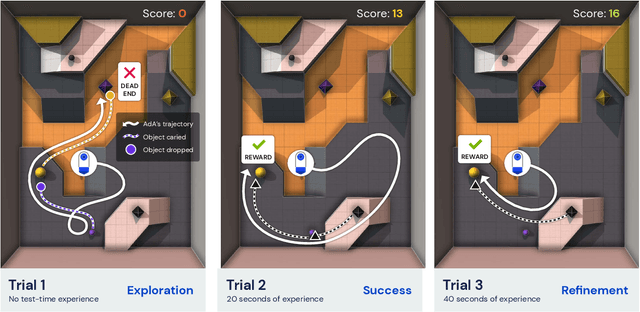
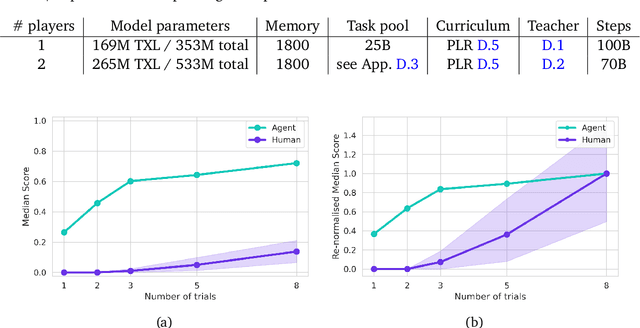
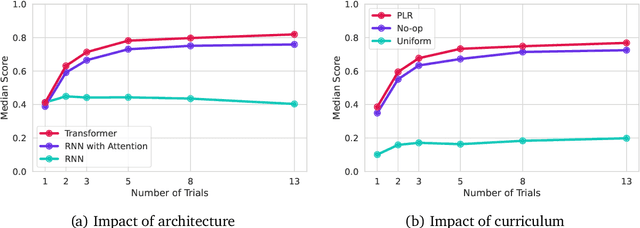
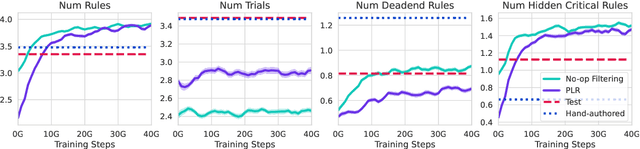
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
Policy Manifold Search: Exploring the Manifold Hypothesis for Diversity-based Neuroevolution
Apr 27, 2021
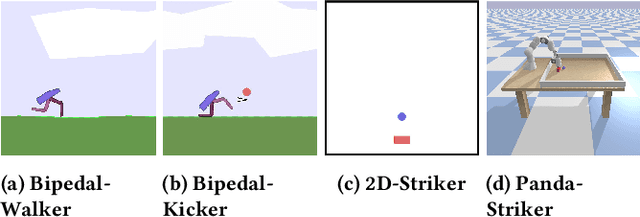


Neuroevolution is an alternative to gradient-based optimisation that has the potential to avoid local minima and allows parallelisation. The main limiting factor is that usually it does not scale well with parameter space dimensionality. Inspired by recent work examining neural network intrinsic dimension and loss landscapes, we hypothesise that there exists a low-dimensional manifold, embedded in the policy network parameter space, around which a high-density of diverse and useful policies are located. This paper proposes a novel method for diversity-based policy search via Neuroevolution, that leverages learned representations of the policy network parameters, by performing policy search in this learned representation space. Our method relies on the Quality-Diversity (QD) framework which provides a principled approach to policy search, and maintains a collection of diverse policies, used as a dataset for learning policy representations. Further, we use the Jacobian of the inverse-mapping function to guide the search in the representation space. This ensures that the generated samples remain in the high-density regions, after mapping back to the original space. Finally, we evaluate our contributions on four continuous-control tasks in simulated environments, and compare to diversity-based baselines.
Policy Manifold Search for Improving Diversity-based Neuroevolution
Dec 15, 2020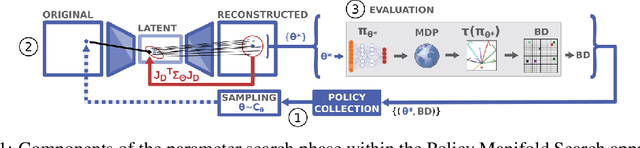


Diversity-based approaches have recently gained popularity as an alternative paradigm to performance-based policy search. A popular approach from this family, Quality-Diversity (QD), maintains a collection of high-performing policies separated in the diversity-metric space, defined based on policies' rollout behaviours. When policies are parameterised as neural networks, i.e. Neuroevolution, QD tends to not scale well with parameter space dimensionality. Our hypothesis is that there exists a low-dimensional manifold embedded in the policy parameter space, containing a high density of diverse and feasible policies. We propose a novel approach to diversity-based policy search via Neuroevolution, that leverages learned latent representations of the policy parameters which capture the local structure of the data. Our approach iteratively collects policies according to the QD framework, in order to (i) build a collection of diverse policies, (ii) use it to learn a latent representation of the policy parameters, (iii) perform policy search in the learned latent space. We use the Jacobian of the inverse transformation (i.e.reconstruction function) to guide the search in the latent space. This ensures that the generated samples remain in the high-density regions of the original space, after reconstruction. We evaluate our contributions on three continuous control tasks in simulated environments, and compare to diversity-based baselines. The findings suggest that our approach yields a more efficient and robust policy search process.
Sim-to-Real Learning for Casualty Detection from Ground Projected Point Cloud Data
Aug 09, 2019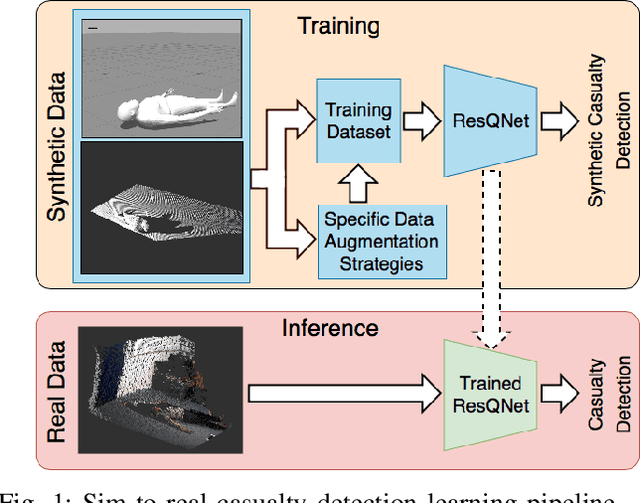

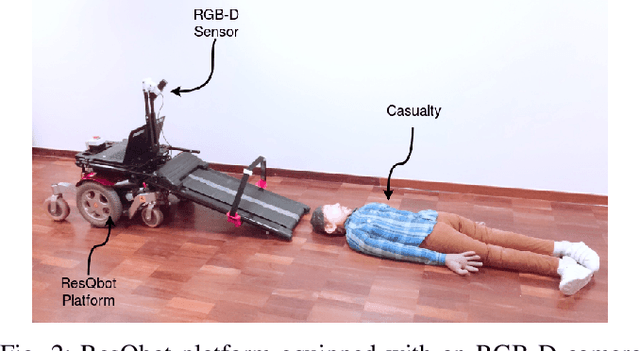
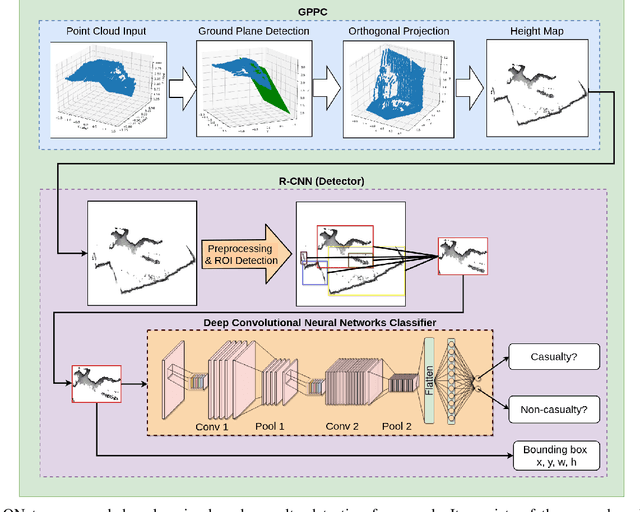
This paper addresses the problem of human body detection---particularly a human body lying on the ground (a.k.a. casualty)---using point cloud data. This ability to detect a casualty is one of the most important features of mobile rescue robots, in order for them to be able to operate autonomously. We propose a deep-learning-based casualty detection method using a deep convolutional neural network (CNN). This network is trained to be able to detect a casualty using a point-cloud data input. In the method we propose, the point cloud input is pre-processed to generate a depth image-like ground-projected heightmap. This heightmap is generated based on the projected distance of each point onto the detected ground plane within the point cloud data. The generated heightmap -- in image form -- is then used as an input for the CNN to detect a human body lying on the ground. To train the neural network, we propose a novel sim-to-real approach, in which the network model is trained using synthetic data obtained in simulation and then tested on real sensor data. To make the model transferable to real data implementations, during the training we adopt specific data augmentation strategies with the synthetic training data. The experimental results show that data augmentation introduced during the training process is essential for improving the performance of the trained model on real data. More specifically, the results demonstrate that the data augmentations on raw point-cloud data have contributed to a considerable improvement of the trained model performance.