 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended Hybrid Zero Dynamics for Bipedal Walking of the Knee-less Robot SLIDER
Apr 01, 2025Knee-less bipedal robots like SLIDER have the advantage of ultra-lightweight legs and improved walking energy efficiency compared to traditional humanoid robots. In this paper, we firstly introduce an improved hardware design of the bipedal robot SLIDER with new line-feet and more optimized mass distribution which enables higher locomotion speeds. Secondly, we propose an extended Hybrid Zero Dynamics (eHZD) method, which can be applied to prismatic joint robots like SLIDER. The eHZD method is then used to generate a library of gaits with varying reference velocities in an offline way. Thirdly, a Guided Deep Reinforcement Learning (DRL) algorithm is proposed to use the pre-generated library to create walking control policies in real-time. This approach allows us to combine the advantages of both HZD (for generating stable gaits with a full-dynamics model) and DRL (for real-time adaptive gait generation). The experimental results show that this approach achieves 150% higher walking velocity than the previous MPC-based approach.
A Backbone for Long-Horizon Robot Task Understanding
Aug 07, 2024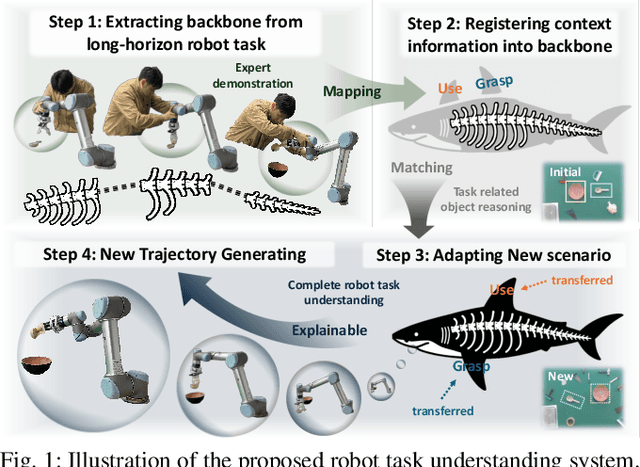
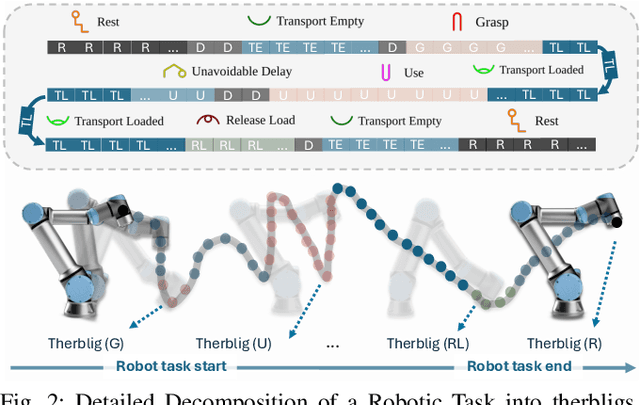
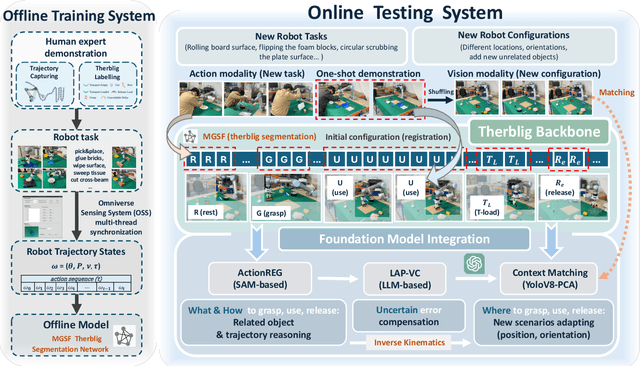
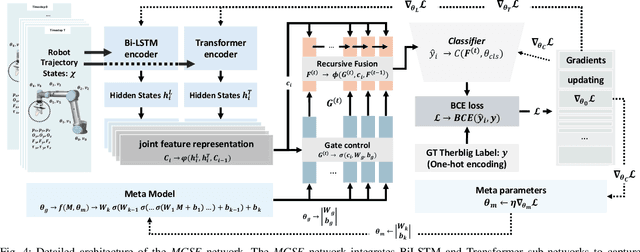
End-to-end robot learning, particularly for long-horizon tasks, often results in unpredictable outcomes and poor generalization. To address these challenges, we propose a novel Therblig-based Backbone Framework (TBBF) to enhance robot task understanding and transferability. This framework uses therbligs (basic action elements) as the backbone to decompose high-level robot tasks into elemental robot configurations, which are then integrated with current foundation models to improve task understanding. The approach consists of two stages: offline training and online testing. During the offline training stage, we developed the Meta-RGate SynerFusion (MGSF) network for accurate therblig segmentation across various tasks. In the online testing stage, after a one-shot demonstration of a new task is collected, our MGSF network extracts high-level knowledge, which is then encoded into the image using Action Registration (ActionREG). Additionally, the Large Language Model (LLM)-Alignment Policy for Visual Correction (LAP-VC) is employed to ensure precise action execution, facilitating trajectory transfer in novel robot scenarios. Experimental results validate these methods, achieving 94.37% recall in therblig segmentation and success rates of 94.4% and 80% in real-world online robot testing for simple and complex scenarios, respectively. Supplementary material is available at: https://sites.google.com/view/therbligsbasedbackbone/home
G.O.G: A Versatile Gripper-On-Gripper Design for Bimanual Cloth Manipulation with a Single Robotic Arm
Jan 19, 2024The manipulation of garments poses research challenges due to their deformable nature and the extensive variability in shapes and sizes. Despite numerous attempts by researchers to address these via approaches involving robot perception and control, there has been a relatively limited interest in resolving it through the co-development of robot hardware. Consequently, the majority of studies employ off-the-shelf grippers in conjunction with dual robot arms to enable bimanual manipulation and high dexterity. However, this dual-arm system increases the overall cost of the robotic system as well as its control complexity in order to tackle robot collisions and other robot coordination issues. As an alternative approach, we propose to enable bimanual cloth manipulation using a single robot arm via novel end effector design -- sharing dexterity skills between manipulator and gripper rather than relying entirely on robot arm coordination. To this end, we introduce a new gripper, called G.O.G., based on a gripper-on-gripper structure where the first gripper independently regulates the span, up to 500mm, between its fingers which are in turn also grippers. These finger grippers consist of a variable friction module that enables two grasping modes: firm and sliding grasps. Household item and cloth object benchmarks are employed to evaluate the performance of the proposed design, encompassing both experiments on the gripper design itself and on cloth manipulation. Experimental results demonstrate the potential of the introduced ideas to undertake a range of bimanual cloth manipulation tasks with a single robot arm. Supplementary material is available at https://sites.google.com/view/gripperongripper.
* Accepted for IEEE Robotics and Automation Letters in January 2024. Dongmyoung Lee and Wei Chen contributed equally to this research
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022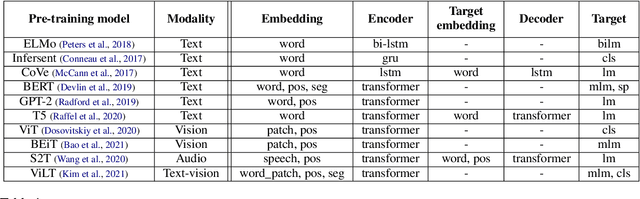
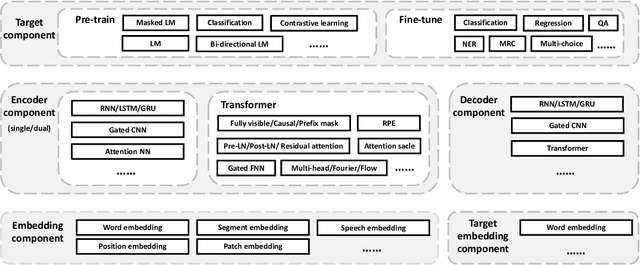
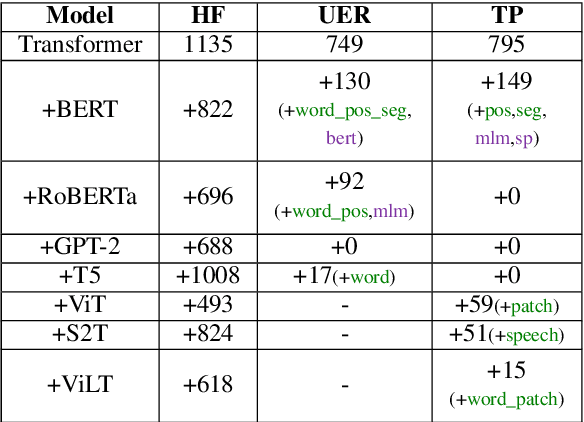
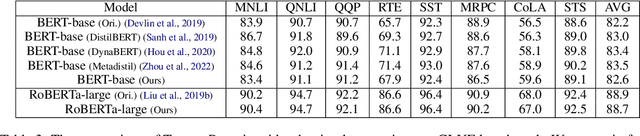
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.