 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Starting States for Reinforcement Learning
Nov 27, 2018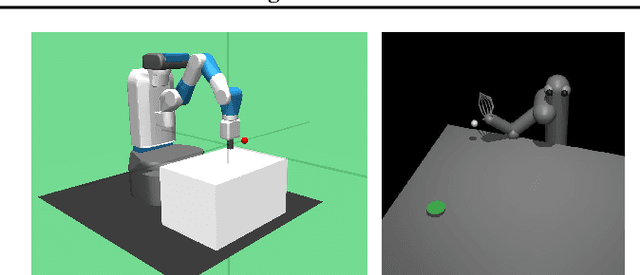
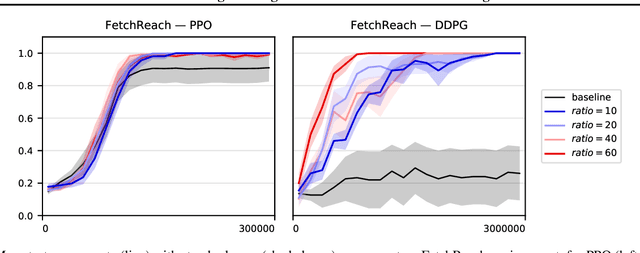
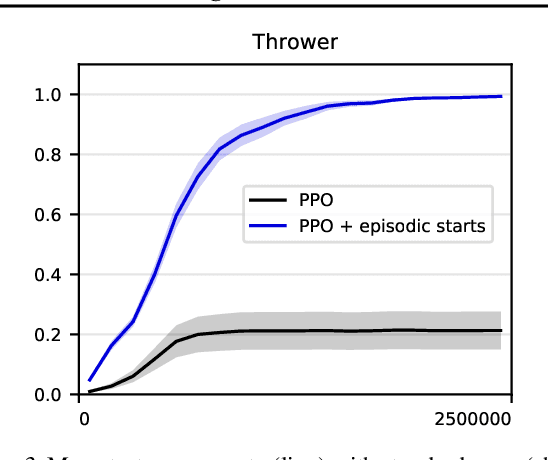
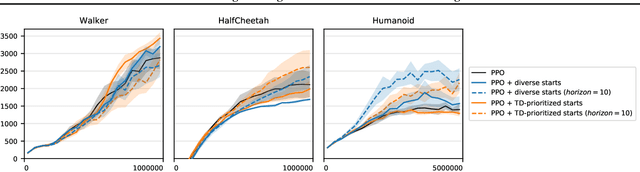
Online, off-policy reinforcement learning algorithms are able to use an experience memory to remember and replay past experiences. In prior work, this approach was used to stabilize training by breaking the temporal correlations of the updates and avoiding the rapid forgetting of possibly rare experiences. In this work, we propose a conceptually simple framework that uses an experience memory to help exploration by prioritizing the starting states from which the agent starts acting in the environment, importantly, in a fashion that is also compatible with on-policy algorithms. Given the capacity to restart the agent in states corresponding to its past observations, we achieve this objective by (i) enabling the agent to restart in states belonging to significant past experiences (e.g., nearby goals), and (ii) promoting faster coverage of the state space through starting from a more diverse set of states. While, using a good measure of priority to identify significant past transitions, we expect case (i) to more considerably help exploration in certain problems (e.g., sparse reward tasks), we hypothesize that case (ii) will generally be beneficial, even without any prioritization. We show empirically that our approach improves learning performance for both off-policy and on-policy deep reinforcement learning methods, with the most notable improvement in a significantly sparse reward task.
Goal-oriented Trajectories for Efficient Exploration
Jul 05, 2018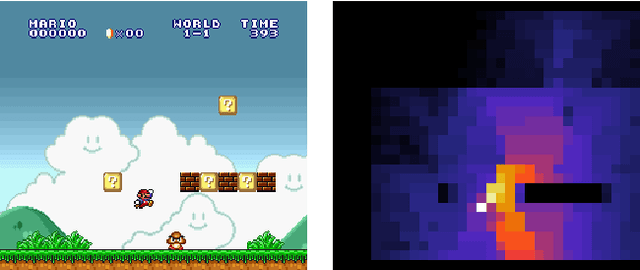
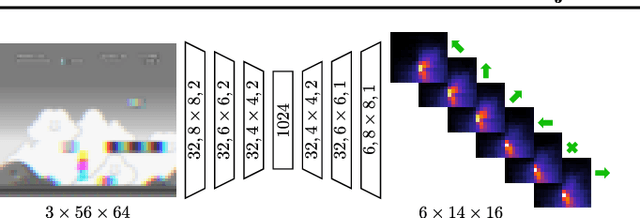

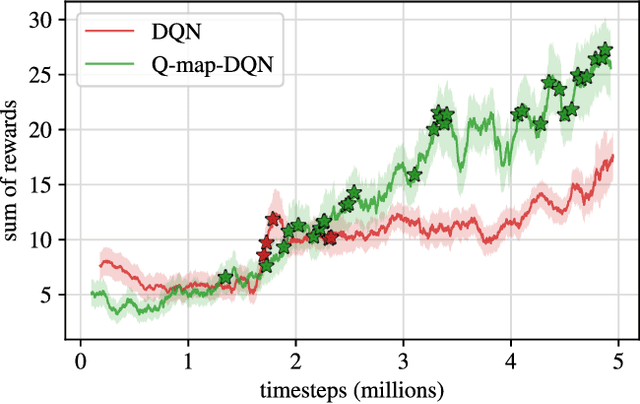
Exploration is a difficult challenge in reinforcement learning and even recent state-of-the art curiosity-based methods rely on the simple epsilon-greedy strategy to generate novelty. We argue that pure random walks do not succeed to properly expand the exploration area in most environments and propose to replace single random action choices by random goals selection followed by several steps in their direction. This approach is compatible with any curiosity-based exploration and off-policy reinforcement learning agents and generates longer and safer trajectories than individual random actions. To illustrate this, we present a task-independent agent that learns to reach coordinates in screen frames and demonstrate its ability to explore with the game Super Mario Bros. improving significantly the score of a baseline DQN agent.
Time Limits in Reinforcement Learning
Jul 05, 2018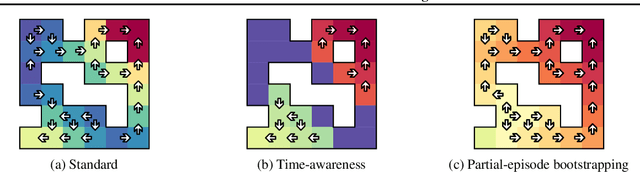
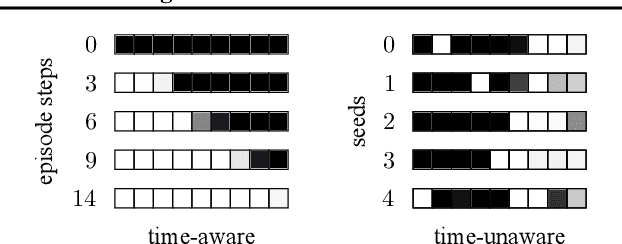
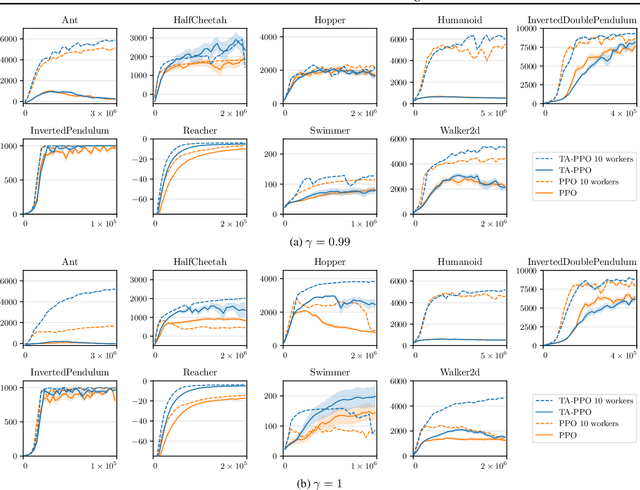
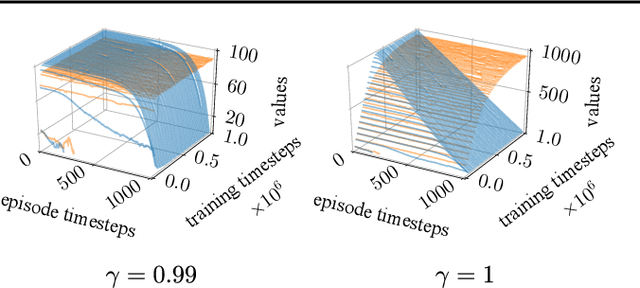
In reinforcement learning, it is common to let an agent interact for a fixed amount of time with its environment before resetting it and repeating the process in a series of episodes. The task that the agent has to learn can either be to maximize its performance over (i) that fixed period, or (ii) an indefinite period where time limits are only used during training to diversify experience. In this paper, we provide a formal account for how time limits could effectively be handled in each of the two cases and explain why not doing so can cause state-aliasing and invalidation of experience replay, leading to suboptimal policies and training instability. In case (i), we argue that the terminations due to time limits are in fact part of the environment, and thus a notion of the remaining time should be included as part of the agent's input to avoid violation of the Markov property. In case (ii), the time limits are not part of the environment and are only used to facilitate learning. We argue that this insight should be incorporated by bootstrapping from the value of the state at the end of each partial episode. For both cases, we illustrate empirically the significance of our considerations in improving the performance and stability of existing reinforcement learning algorithms, showing state-of-the-art results on several control tasks.
* ICML 2018, NIPS 2017 Deep RL Symposium, code and videos: https://sites.google.com/view/time-limits-in-rl