 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to unfold cloth: Scaling up world models to deformable object manipulation
Feb 18, 2026Learning to manipulate cloth is both a paradigmatic problem for robotic research and a problem of immediate relevance to a variety of applications ranging from assistive care to the service industry. The complex physics of the deformable object makes this problem of cloth manipulation nontrivial. In order to create a general manipulation strategy that addresses a variety of shapes, sizes, fold and wrinkle patterns, in addition to the usual problems of appearance variations, it becomes important to carefully consider model structure and their implications for generalisation performance. In this paper, we present an approach to in-air cloth manipulation that uses a variation of a recently proposed reinforcement learning architecture, DreamerV2. Our implementation modifies this architecture to utilise surface normals input, in addition to modiying the replay buffer and data augmentation procedures. Taken together these modifications represent an enhancement to the world model used by the robot, addressing the physical complexity of the object being manipulated by the robot. We present evaluations both in simulation and in a zero-shot deployment of the trained policies in a physical robot setup, performing in-air unfolding of a variety of different cloth types, demonstrating the generalisation benefits of our proposed architecture.
BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark
Jul 11, 2024



We introduce BiGym, a new benchmark and learning environment for mobile bi-manual demo-driven robotic manipulation. BiGym features 40 diverse tasks set in home environments, ranging from simple target reaching to complex kitchen cleaning. To capture the real-world performance accurately, we provide human-collected demonstrations for each task, reflecting the diverse modalities found in real-world robot trajectories. BiGym supports a variety of observations, including proprioceptive data and visual inputs such as RGB, and depth from 3 camera views. To validate the usability of BiGym, we thoroughly benchmark the state-of-the-art imitation learning algorithms and demo-driven reinforcement learning algorithms within the environment and discuss the future opportunities.
Green Screen Augmentation Enables Scene Generalisation in Robotic Manipulation
Jul 10, 2024



Generalising vision-based manipulation policies to novel environments remains a challenging area with limited exploration. Current practices involve collecting data in one location, training imitation learning or reinforcement learning policies with this data, and deploying the policy in the same location. However, this approach lacks scalability as it necessitates data collection in multiple locations for each task. This paper proposes a novel approach where data is collected in a location predominantly featuring green screens. We introduce Green-screen Augmentation (GreenAug), employing a chroma key algorithm to overlay background textures onto a green screen. Through extensive real-world empirical studies with over 850 training demonstrations and 8.2k evaluation episodes, we demonstrate that GreenAug surpasses no augmentation, standard computer vision augmentation, and prior generative augmentation methods in performance. While no algorithmic novelties are claimed, our paper advocates for a fundamental shift in data collection practices. We propose that real-world demonstrations in future research should utilise green screens, followed by the application of GreenAug. We believe GreenAug unlocks policy generalisation to visually distinct novel locations, addressing the current scene generalisation limitations in robot learning.
Continuous Control with Coarse-to-fine Reinforcement Learning
Jul 10, 2024Despite recent advances in improving the sample-efficiency of reinforcement learning (RL) algorithms, designing an RL algorithm that can be practically deployed in real-world environments remains a challenge. In this paper, we present Coarse-to-fine Reinforcement Learning (CRL), a framework that trains RL agents to zoom-into a continuous action space in a coarse-to-fine manner, enabling the use of stable, sample-efficient value-based RL algorithms for fine-grained continuous control tasks. Our key idea is to train agents that output actions by iterating the procedure of (i) discretizing the continuous action space into multiple intervals and (ii) selecting the interval with the highest Q-value to further discretize at the next level. We then introduce a concrete, value-based algorithm within the CRL framework called Coarse-to-fine Q-Network (CQN). Our experiments demonstrate that CQN significantly outperforms RL and behavior cloning baselines on 20 sparsely-rewarded RLBench manipulation tasks with a modest number of environment interactions and expert demonstrations. We also show that CQN robustly learns to solve real-world manipulation tasks within a few minutes of online training.
Generative Image as Action Models
Jul 10, 2024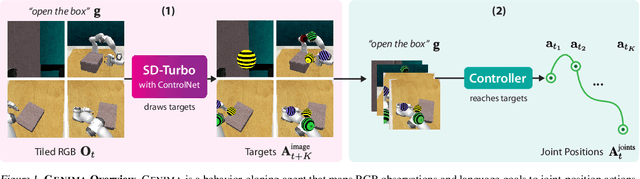

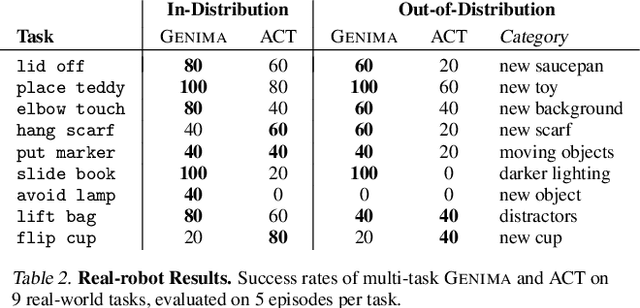
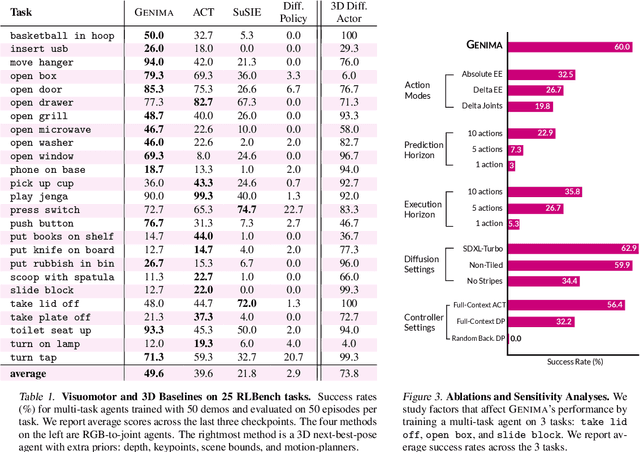
Image-generation diffusion models have been fine-tuned to unlock new capabilities such as image-editing and novel view synthesis. Can we similarly unlock image-generation models for visuomotor control? We present GENIMA, a behavior-cloning agent that fine-tunes Stable Diffusion to 'draw joint-actions' as targets on RGB images. These images are fed into a controller that maps the visual targets into a sequence of joint-positions. We study GENIMA on 25 RLBench and 9 real-world manipulation tasks. We find that, by lifting actions into image-space, internet pre-trained diffusion models can generate policies that outperform state-of-the-art visuomotor approaches, especially in robustness to scene perturbations and generalizing to novel objects. Our method is also competitive with 3D agents, despite lacking priors such as depth, keypoints, or motion-planners.
Redundancy-aware Action Spaces for Robot Learning
Jun 06, 2024



Joint space and task space control are the two dominant action modes for controlling robot arms within the robot learning literature. Actions in joint space provide precise control over the robot's pose, but tend to suffer from inefficient training; actions in task space boast data-efficient training but sacrifice the ability to perform tasks in confined spaces due to limited control over the full joint configuration. This work analyses the criteria for designing action spaces for robot manipulation and introduces ER (End-effector Redundancy), a novel action space formulation that, by addressing the redundancies present in the manipulator, aims to combine the advantages of both joint and task spaces, offering fine-grained comprehensive control with overactuated robot arms whilst achieving highly efficient robot learning. We present two implementations of ER, ERAngle (ERA) and ERJoint (ERJ), and we show that ERJ in particular demonstrates superior performance across multiple settings, especially when precise control over the robot configuration is required. We validate our results both in simulated and real robotic environments.
Render and Diffuse: Aligning Image and Action Spaces for Diffusion-based Behaviour Cloning
May 28, 2024In the field of Robot Learning, the complex mapping between high-dimensional observations such as RGB images and low-level robotic actions, two inherently very different spaces, constitutes a complex learning problem, especially with limited amounts of data. In this work, we introduce Render and Diffuse (R&D) a method that unifies low-level robot actions and RGB observations within the image space using virtual renders of the 3D model of the robot. Using this joint observation-action representation it computes low-level robot actions using a learnt diffusion process that iteratively updates the virtual renders of the robot. This space unification simplifies the learning problem and introduces inductive biases that are crucial for sample efficiency and spatial generalisation. We thoroughly evaluate several variants of R&D in simulation and showcase their applicability on six everyday tasks in the real world. Our results show that R&D exhibits strong spatial generalisation capabilities and is more sample efficient than more common image-to-action methods.
Hierarchical Diffusion Policy for Kinematics-Aware Multi-Task Robotic Manipulation
Mar 06, 2024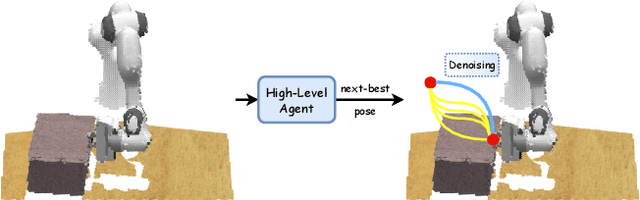


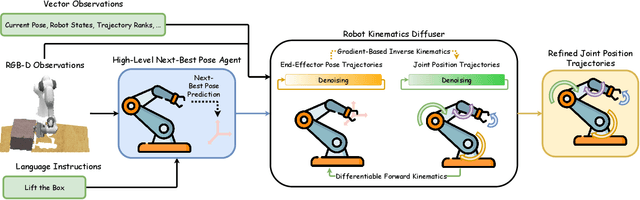
This paper introduces Hierarchical Diffusion Policy (HDP), a hierarchical agent for multi-task robotic manipulation. HDP factorises a manipulation policy into a hierarchical structure: a high-level task-planning agent which predicts a distant next-best end-effector pose (NBP), and a low-level goal-conditioned diffusion policy which generates optimal motion trajectories. The factorised policy representation allows HDP to tackle both long-horizon task planning while generating fine-grained low-level actions. To generate context-aware motion trajectories while satisfying robot kinematics constraints, we present a novel kinematics-aware goal-conditioned control agent, Robot Kinematics Diffuser (RK-Diffuser). Specifically, RK-Diffuser learns to generate both the end-effector pose and joint position trajectories, and distill the accurate but kinematics-unaware end-effector pose diffuser to the kinematics-aware but less accurate joint position diffuser via differentiable kinematics. Empirically, we show that HDP achieves a significantly higher success rate than the state-of-the-art methods in both simulation and real-world.
Speed Co-Augmentation for Unsupervised Audio-Visual Pre-training
Sep 25, 2023This work aims to improve unsupervised audio-visual pre-training. Inspired by the efficacy of data augmentation in visual contrastive learning, we propose a novel speed co-augmentation method that randomly changes the playback speeds of both audio and video data. Despite its simplicity, the speed co-augmentation method possesses two compelling attributes: (1) it increases the diversity of audio-visual pairs and doubles the size of negative pairs, resulting in a significant enhancement in the learned representations, and (2) it changes the strict correlation between audio-visual pairs but introduces a partial relationship between the augmented pairs, which is modeled by our proposed SoftInfoNCE loss to further boost the performance. Experimental results show that the proposed method significantly improves the learned representations when compared to vanilla audio-visual contrastive learning.
Language-Conditioned Path Planning
Aug 31, 2023Contact is at the core of robotic manipulation. At times, it is desired (e.g. manipulation and grasping), and at times, it is harmful (e.g. when avoiding obstacles). However, traditional path planning algorithms focus solely on collision-free paths, limiting their applicability in contact-rich tasks. To address this limitation, we propose the domain of Language-Conditioned Path Planning, where contact-awareness is incorporated into the path planning problem. As a first step in this domain, we propose Language-Conditioned Collision Functions (LACO) a novel approach that learns a collision function using only a single-view image, language prompt, and robot configuration. LACO predicts collisions between the robot and the environment, enabling flexible, conditional path planning without the need for manual object annotations, point cloud data, or ground-truth object meshes. In both simulation and the real world, we demonstrate that LACO can facilitate complex, nuanced path plans that allow for interaction with objects that are safe to collide, rather than prohibiting any collision.