 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreen Screen Augmentation Enables Scene Generalisation in Robotic Manipulation
Jul 10, 2024



Generalising vision-based manipulation policies to novel environments remains a challenging area with limited exploration. Current practices involve collecting data in one location, training imitation learning or reinforcement learning policies with this data, and deploying the policy in the same location. However, this approach lacks scalability as it necessitates data collection in multiple locations for each task. This paper proposes a novel approach where data is collected in a location predominantly featuring green screens. We introduce Green-screen Augmentation (GreenAug), employing a chroma key algorithm to overlay background textures onto a green screen. Through extensive real-world empirical studies with over 850 training demonstrations and 8.2k evaluation episodes, we demonstrate that GreenAug surpasses no augmentation, standard computer vision augmentation, and prior generative augmentation methods in performance. While no algorithmic novelties are claimed, our paper advocates for a fundamental shift in data collection practices. We propose that real-world demonstrations in future research should utilise green screens, followed by the application of GreenAug. We believe GreenAug unlocks policy generalisation to visually distinct novel locations, addressing the current scene generalisation limitations in robot learning.
Hierarchical Diffusion Policy for Kinematics-Aware Multi-Task Robotic Manipulation
Mar 06, 2024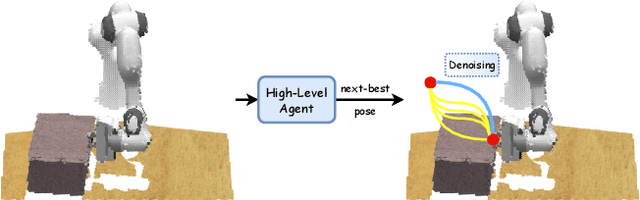


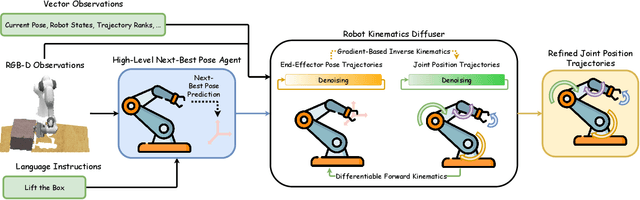
This paper introduces Hierarchical Diffusion Policy (HDP), a hierarchical agent for multi-task robotic manipulation. HDP factorises a manipulation policy into a hierarchical structure: a high-level task-planning agent which predicts a distant next-best end-effector pose (NBP), and a low-level goal-conditioned diffusion policy which generates optimal motion trajectories. The factorised policy representation allows HDP to tackle both long-horizon task planning while generating fine-grained low-level actions. To generate context-aware motion trajectories while satisfying robot kinematics constraints, we present a novel kinematics-aware goal-conditioned control agent, Robot Kinematics Diffuser (RK-Diffuser). Specifically, RK-Diffuser learns to generate both the end-effector pose and joint position trajectories, and distill the accurate but kinematics-unaware end-effector pose diffuser to the kinematics-aware but less accurate joint position diffuser via differentiable kinematics. Empirically, we show that HDP achieves a significantly higher success rate than the state-of-the-art methods in both simulation and real-world.
In-Hand Cube Reconfiguration: Simplified
Aug 23, 2023We present a simple approach to in-hand cube reconfiguration. By simplifying planning, control, and perception as much as possible, while maintaining robust and general performance, we gain insights into the inherent complexity of in-hand cube reconfiguration. We also demonstrate the effectiveness of combining GOFAI-based planning with the exploitation of environmental constraints and inherently compliant end-effectors in the context of dexterous manipulation. The proposed system outperforms a substantially more complex system for cube reconfiguration based on deep learning and accurate physical simulation, contributing arguments to the discussion about what the most promising approach to general manipulation might be. Project website: https://rbo.gitlab-pages.tu-berlin.de/robotics/simpleIHM/