 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multimodal Cues of Children's Uncertainty
Oct 17, 2024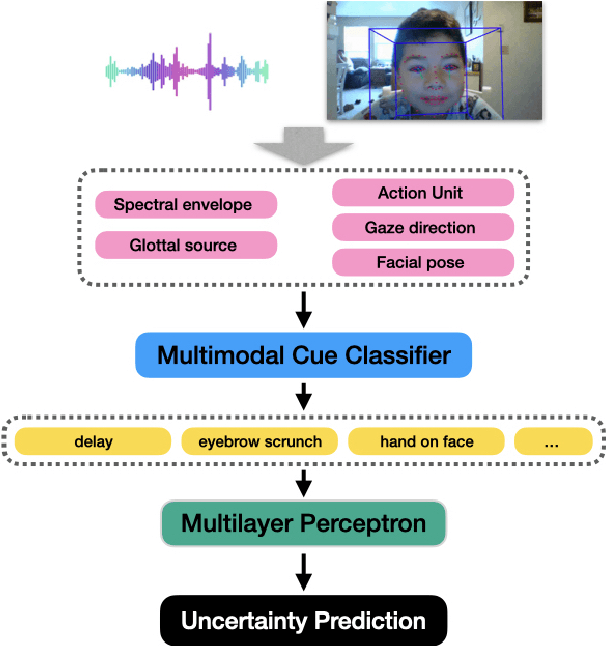
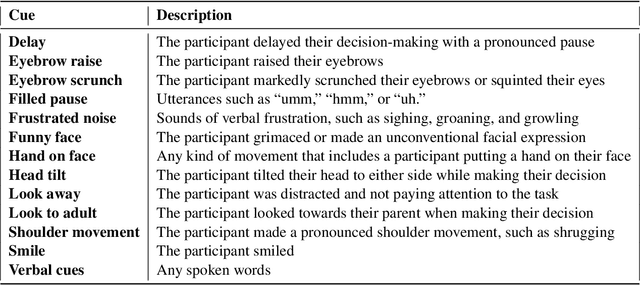
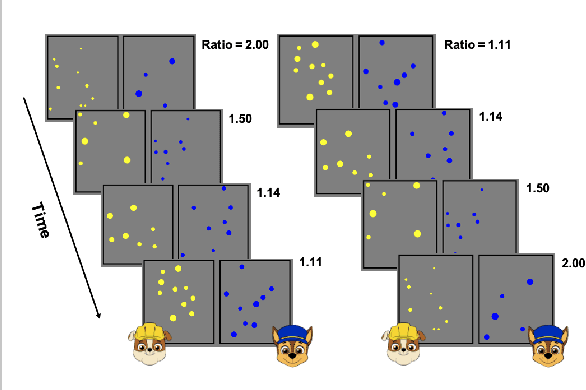
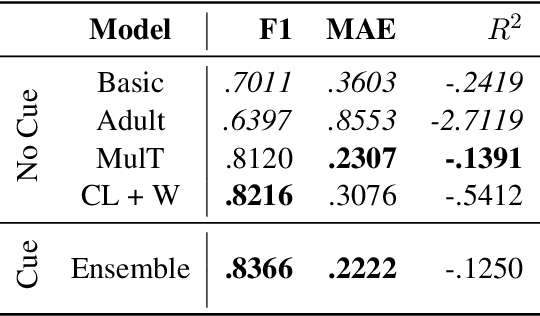
Understanding uncertainty plays a critical role in achieving common ground (Clark et al.,1983). This is especially important for multimodal AI systems that collaborate with users to solve a problem or guide the user through a challenging concept. In this work, for the first time, we present a dataset annotated in collaboration with developmental and cognitive psychologists for the purpose of studying nonverbal cues of uncertainty. We then present an analysis of the data, studying different roles of uncertainty and its relationship with task difficulty and performance. Lastly, we present a multimodal machine learning model that can predict uncertainty given a real-time video clip of a participant, which we find improves upon a baseline multimodal transformer model. This work informs research on cognitive coordination between human-human and human-AI and has broad implications for gesture understanding and generation. The anonymized version of our data and code will be publicly available upon the completion of the required consent forms and data sheets.
Learning Distributional Demonstration Spaces for Task-Specific Cross-Pose Estimation
May 07, 2024



Relative placement tasks are an important category of tasks in which one object needs to be placed in a desired pose relative to another object. Previous work has shown success in learning relative placement tasks from just a small number of demonstrations when using relational reasoning networks with geometric inductive biases. However, such methods cannot flexibly represent multimodal tasks, like a mug hanging on any of n racks. We propose a method that incorporates additional properties that enable learning multimodal relative placement solutions, while retaining the provably translation-invariant and relational properties of prior work. We show that our method is able to learn precise relative placement tasks with only 10-20 multimodal demonstrations with no human annotations across a diverse set of objects within a category.
Information is Power: Intrinsic Control via Information Capture
Dec 07, 2021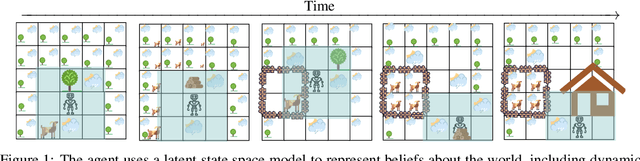
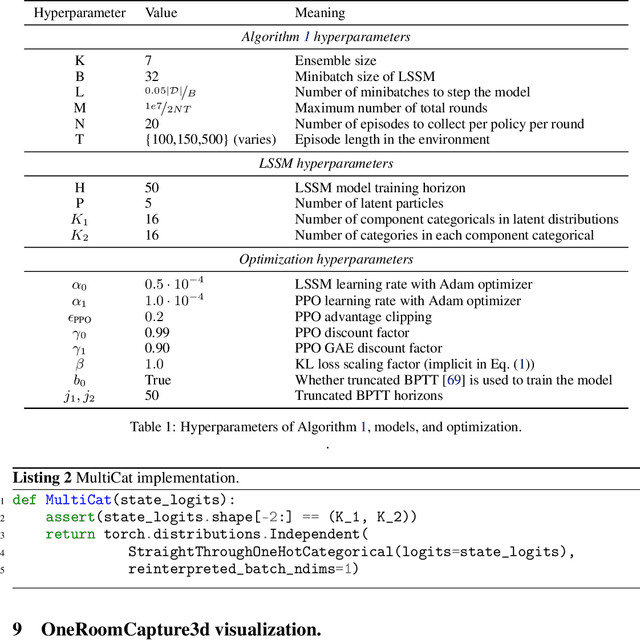


Humans and animals explore their environment and acquire useful skills even in the absence of clear goals, exhibiting intrinsic motivation. The study of intrinsic motivation in artificial agents is concerned with the following question: what is a good general-purpose objective for an agent? We study this question in dynamic partially-observed environments, and argue that a compact and general learning objective is to minimize the entropy of the agent's state visitation estimated using a latent state-space model. This objective induces an agent to both gather information about its environment, corresponding to reducing uncertainty, and to gain control over its environment, corresponding to reducing the unpredictability of future world states. We instantiate this approach as a deep reinforcement learning agent equipped with a deep variational Bayes filter. We find that our agent learns to discover, represent, and exercise control of dynamic objects in a variety of partially-observed environments sensed with visual observations without extrinsic reward.