 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-KnG: Visual Scene Understanding for Navigation Goal Identification using Spatiotemporal Knowledge Graphs
Oct 01, 2025
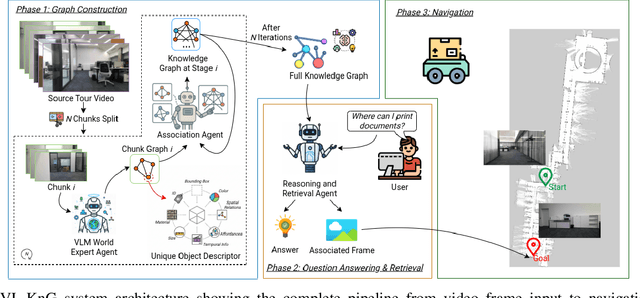
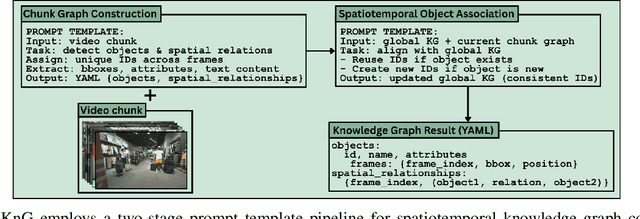
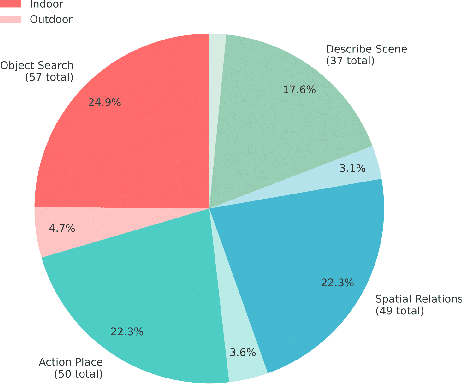
Vision-language models (VLMs) have shown potential for robot navigation but encounter fundamental limitations: they lack persistent scene memory, offer limited spatial reasoning, and do not scale effectively with video duration for real-time application. We present VL-KnG, a Visual Scene Understanding system that tackles these challenges using spatiotemporal knowledge graph construction and computationally efficient query processing for navigation goal identification. Our approach processes video sequences in chunks utilizing modern VLMs, creates persistent knowledge graphs that maintain object identity over time, and enables explainable spatial reasoning through queryable graph structures. We also introduce WalkieKnowledge, a new benchmark with about 200 manually annotated questions across 8 diverse trajectories spanning approximately 100 minutes of video data, enabling fair comparison between structured approaches and general-purpose VLMs. Real-world deployment on a differential drive robot demonstrates practical applicability, with our method achieving 77.27% success rate and 76.92% answer accuracy, matching Gemini 2.5 Pro performance while providing explainable reasoning supported by the knowledge graph, computational efficiency for real-time deployment across different tasks, such as localization, navigation and planning. Code and dataset will be released after acceptance.
ReplaceMe: Network Simplification via Layer Pruning and Linear Transformations
May 05, 2025We introduce ReplaceMe, a generalized training-free depth pruning method that effectively replaces transformer blocks with a linear operation, while maintaining high performance for low compression ratios. In contrast to conventional pruning approaches that require additional training or fine-tuning, our approach requires only a small calibration dataset that is used to estimate a linear transformation to approximate the pruned blocks. This estimated linear mapping can be seamlessly merged with the remaining transformer blocks, eliminating the need for any additional network parameters. Our experiments show that ReplaceMe consistently outperforms other training-free approaches and remains highly competitive with state-of-the-art pruning methods that involve extensive retraining/fine-tuning and architectural modifications. Applied to several large language models (LLMs), ReplaceMe achieves up to 25% pruning while retaining approximately 90% of the original model's performance on open benchmarks - without any training or healing steps, resulting in minimal computational overhead (see Fig.1). We provide an open-source library implementing ReplaceMe alongside several state-of-the-art depth pruning techniques, available at this repository.
Mapping the Unseen: Unified Promptable Panoptic Mapping with Dynamic Labeling using Foundation Models
May 03, 2024In the field of robotics and computer vision, efficient and accurate semantic mapping remains a significant challenge due to the growing demand for intelligent machines that can comprehend and interact with complex environments. Conventional panoptic mapping methods, however, are limited by predefined semantic classes, thus making them ineffective for handling novel or unforeseen objects. In response to this limitation, we introduce the Unified Promptable Panoptic Mapping (UPPM) method. UPPM utilizes recent advances in foundation models to enable real-time, on-demand label generation using natural language prompts. By incorporating a dynamic labeling strategy into traditional panoptic mapping techniques, UPPM provides significant improvements in adaptability and versatility while maintaining high performance levels in map reconstruction. We demonstrate our approach on real-world and simulated datasets. Results show that UPPM can accurately reconstruct scenes and segment objects while generating rich semantic labels through natural language interactions. A series of ablation experiments validated the advantages of foundation model-based labeling over fixed label sets.
Standing Between Past and Future: Spatio-Temporal Modeling for Multi-Camera 3D Multi-Object Tracking
Feb 07, 2023This work proposes an end-to-end multi-camera 3D multi-object tracking (MOT) framework. It emphasizes spatio-temporal continuity and integrates both past and future reasoning for tracked objects. Thus, we name it "Past-and-Future reasoning for Tracking" (PF-Track). Specifically, our method adapts the "tracking by attention" framework and represents tracked instances coherently over time with object queries. To explicitly use historical cues, our "Past Reasoning" module learns to refine the tracks and enhance the object features by cross-attending to queries from previous frames and other objects. The "Future Reasoning" module digests historical information and predicts robust future trajectories. In the case of long-term occlusions, our method maintains the object positions and enables re-association by integrating motion predictions. On the nuScenes dataset, our method improves AMOTA by a large margin and remarkably reduces ID-Switches by 90% compared to prior approaches, which is an order of magnitude less. The code and models are made available at https://github.com/TRI-ML/PF-Track.
Safe Real-World Autonomous Driving by Learning to Predict and Plan with a Mixture of Experts
Nov 03, 2022The goal of autonomous vehicles is to navigate public roads safely and comfortably. To enforce safety, traditional planning approaches rely on handcrafted rules to generate trajectories. Machine learning-based systems, on the other hand, scale with data and are able to learn more complex behaviors. However, they often ignore that agents and self-driving vehicle trajectory distributions can be leveraged to improve safety. In this paper, we propose modeling a distribution over multiple future trajectories for both the self-driving vehicle and other road agents, using a unified neural network architecture for prediction and planning. During inference, we select the planning trajectory that minimizes a cost taking into account safety and the predicted probabilities. Our approach does not depend on any rule-based planners for trajectory generation or optimization, improves with more training data and is simple to implement. We extensively evaluate our method through a realistic simulator and show that the predicted trajectory distribution corresponds to different driving profiles. We also successfully deploy it on a self-driving vehicle on urban public roads, confirming that it drives safely without compromising comfort. The code for training and testing our model on a public prediction dataset and the video of the road test are available at https://woven.mobi/safepathnet
CW-ERM: Improving Autonomous Driving Planning with Closed-loop Weighted Empirical Risk Minimization
Oct 11, 2022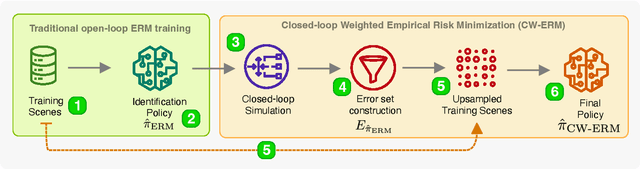
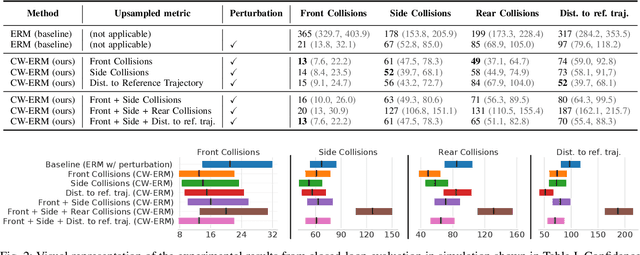
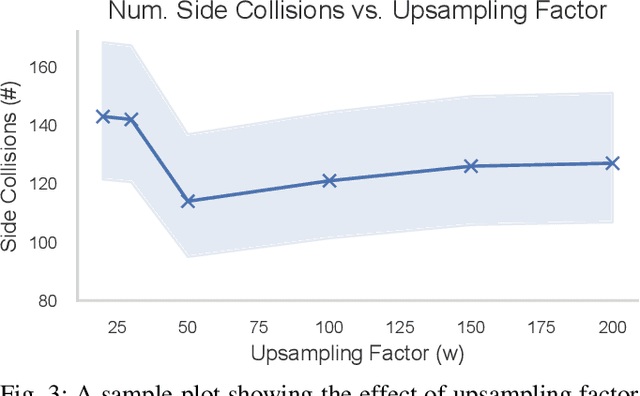
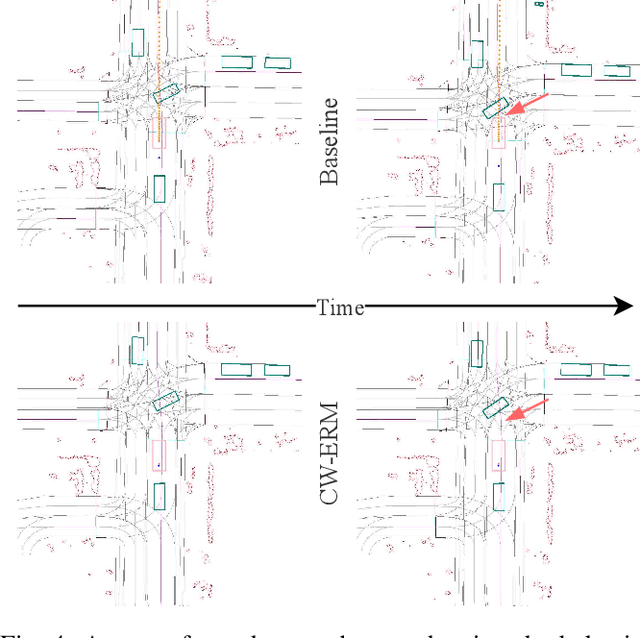
The imitation learning of self-driving vehicle policies through behavioral cloning is often carried out in an open-loop fashion, ignoring the effect of actions to future states. Training such policies purely with Empirical Risk Minimization (ERM) can be detrimental to real-world performance, as it biases policy networks towards matching only open-loop behavior, showing poor results when evaluated in closed-loop. In this work, we develop an efficient and simple-to-implement principle called Closed-loop Weighted Empirical Risk Minimization (CW-ERM), in which a closed-loop evaluation procedure is first used to identify training data samples that are important for practical driving performance and then we these samples to help debias the policy network. We evaluate CW-ERM in a challenging urban driving dataset and show that this procedure yields a significant reduction in collisions as well as other non-differentiable closed-loop metrics.
End-to-End Object Detection with Transformers
May 28, 2020
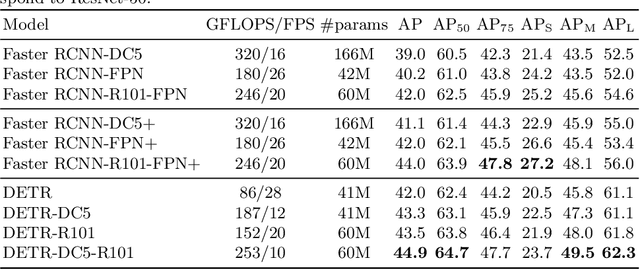
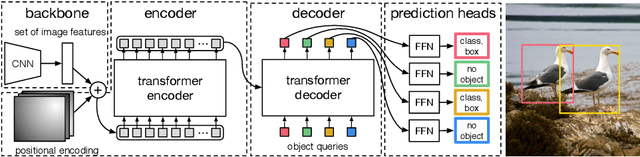
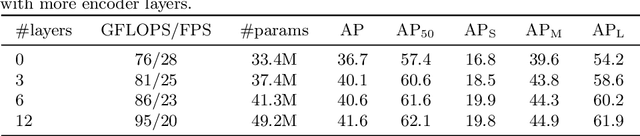
We present a new method that views object detection as a direct set prediction problem. Our approach streamlines the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task. The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture. Given a fixed small set of learned object queries, DETR reasons about the relations of the objects and the global image context to directly output the final set of predictions in parallel. The new model is conceptually simple and does not require a specialized library, unlike many other modern detectors. DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner. We show that it significantly outperforms competitive baselines. Training code and pretrained models are available at https://github.com/facebookresearch/detr.
Polygames: Improved Zero Learning
Jan 27, 2020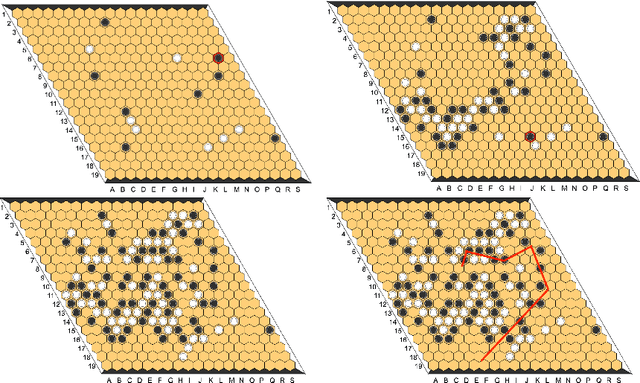
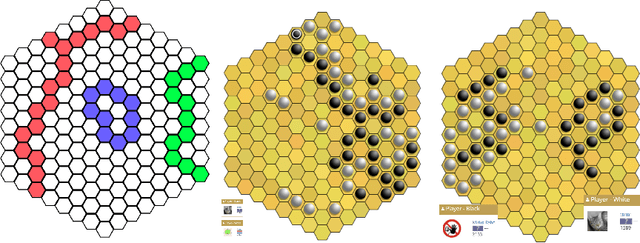
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
Monte-Carlo Tree Search for Efficient Visually Guided Rearrangement Planning
Apr 23, 2019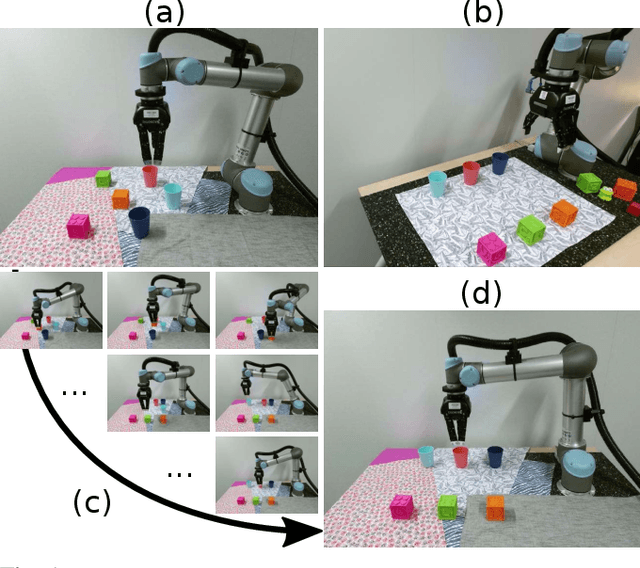
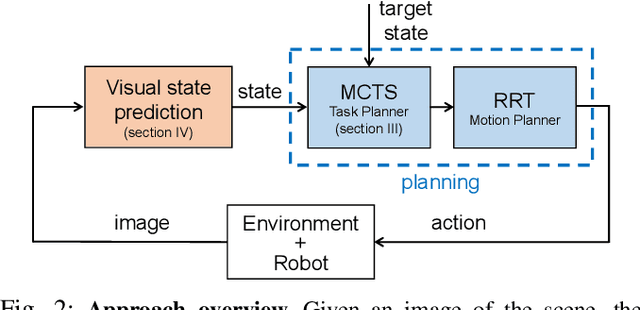
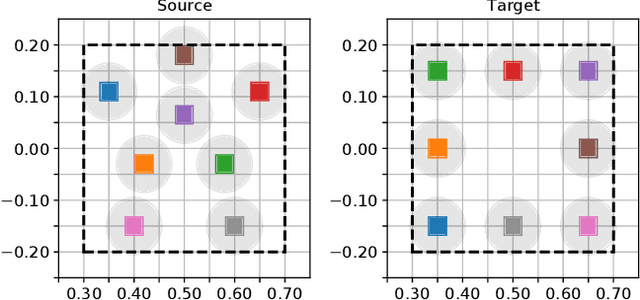
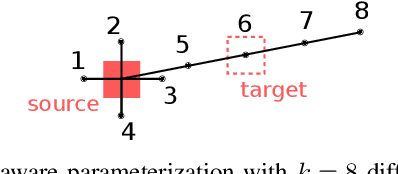
In this paper, we address the problem of visually guided rearrangement planning with many movable objects, i.e., finding a sequence of actions to move a set of objects from an initial arrangement to a desired one, while relying directly on visual inputs coming from a camera. We introduce an efficient and scalable rearrangement planning method, addressing a fundamental limitation of most existing approaches that do not scale well with the number of objects. This increased efficiency allows us to use planning in a closed loop with visual workspace analysis to build a robust rearrangement framework that can recover from errors and external perturbations. The contributions of this work are threefold. First, we develop an AlphaGo-like strategy for rearrangement planning, improving the efficiency of Monte-Carlo Tree Search (MCTS) using a policy trained from rearrangement planning examples. We show empirically that the proposed approach scales well with the number of objects. Second, in order to demonstrate the efficiency of the planner on a real robot, we adopt a state-of-the-art calibration-free visual recognition system that outputs position of a single object and extend it to estimate the state of a workspace containing multiple objects. Third, we validate the complete pipeline with several experiments on a real UR-5 robotic arm solving rearrangement planning problems with multiple movable objects and only requiring few seconds of computation to compute the plan. We also show empirically that the robot can successfully recover from errors and perturbations in the workspace. Source code and pretrained models for our work are available at https://github.com/ylabbe/rearrangement-planning
Exploring Weight Symmetry in Deep Neural Networks
Jan 10, 2019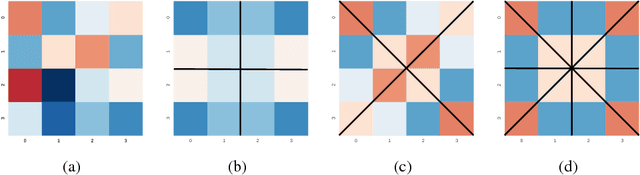
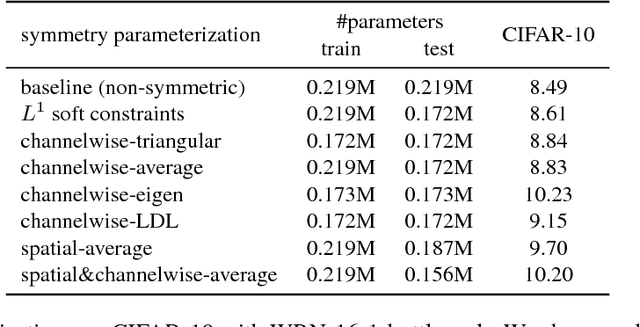
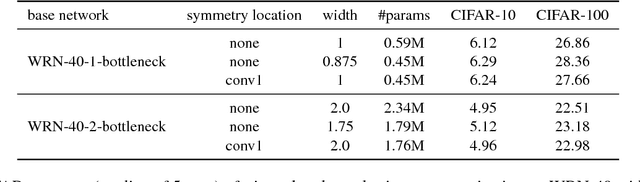
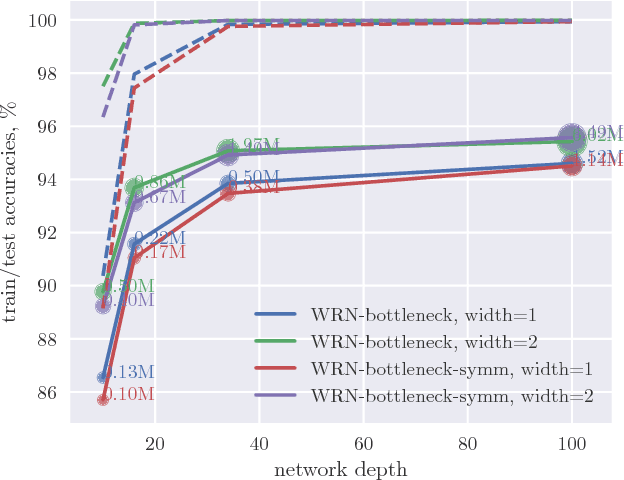
We propose to impose symmetry in neural network parameters to improve parameter usage and make use of dedicated convolution and matrix multiplication routines. Due to significant reduction in the number of parameters as a result of the symmetry constraints, one would expect a dramatic drop in accuracy. Surprisingly, we show that this is not the case, and, depending on network size, symmetry can have little or no negative effect on network accuracy, especially in deep overparameterized networks. We propose several ways to impose local symmetry in recurrent and convolutional neural networks, and show that our symmetry parameterizations satisfy universal approximation property for single hidden layer networks. We extensively evaluate these parameterizations on CIFAR, ImageNet and language modeling datasets, showing significant benefits from the use of symmetry. For instance, our ResNet-101 with channel-wise symmetry has almost 25% less parameters and only 0.2% accuracy loss on ImageNet. Code for our experiments is available at https://github.com/hushell/deep-symmetry