 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPOT: Calibration-Optimized Matrix Procrustes Orthogonalization for Transformers Compression
Feb 16, 2026Post-training compression of Transformer models commonly relies on truncated singular value decomposition (SVD). However, enforcing a single shared subspace can degrade accuracy even at moderate compression. Sparse dictionary learning provides a more flexible union-of-subspaces representation, but existing approaches often suffer from iterative dictionary and coefficient updates. We propose COMPOT (Calibration-Optimized Matrix Procrustes Orthogonalization for Transformers), a training-free compression framework that uses a small calibration dataset to estimate a sparse weight factorization. COMPOT employs orthogonal dictionaries that enable closed-form Procrustes updates for the dictionary and analytical single-step sparse coding for the coefficients, eliminating iterative optimization. To handle heterogeneous layer sensitivity under a global compression budget, COMPOT further introduces a one-shot dynamic allocation strategy that adaptively redistributes layer-wise compression rates. Extensive experiments across diverse architectures and tasks show that COMPOT consistently delivers a superior quality-compression trade-off over strong low-rank and sparse baselines, while remaining fully compatible with post-training quantization for extreme compression. Code is available $\href{https://github.com/mts-ai/COMPOT}{here}$.
ROCKET: Rapid Optimization via Calibration-guided Knapsack Enhanced Truncation for Efficient Model Compression
Feb 11, 2026We present ROCKET, a training-free model compression method that achieves state-of-the-art performance in comparison with factorization, structured-sparsification and dynamic compression baselines. Operating under a global compression budget, ROCKET comprises two key innovations: First, it formulates layer-wise compression allocation as a multi-choice knapsack problem, selecting the optimal compression level for each layer to minimize total reconstruction error while adhering to a target model size. Second, it introduces a single-step sparse matrix factorization inspired by dictionary learning: using only a small calibration set, it sparsifies weight coefficients based on activation-weights sensitivity and then updates the dictionary in closed form via least squares bypassing iterative optimization, sparse coding, or backpropagation entirely. ROCKET consistently outperforms existing compression approaches across different model architectures at 20-50\% compression rates. Notably, it retains over 90\% of the original model's performance at 30\% compression without any fine-tuning. Moreover, when applying a light fine-tuning phase, recovery is substantially enhanced: for instance, compressing Qwen3-14B to an 8B-parameter model and healing it with just 30 million tokens yields performance nearly on par with the original Qwen3-8B. The code for ROCKET is at github.com/mts-ai/ROCKET/tree/main.
Speak, Edit, Repeat: High-Fidelity Voice Editing and Zero-Shot TTS with Cross-Attentive Mamba
Oct 06, 2025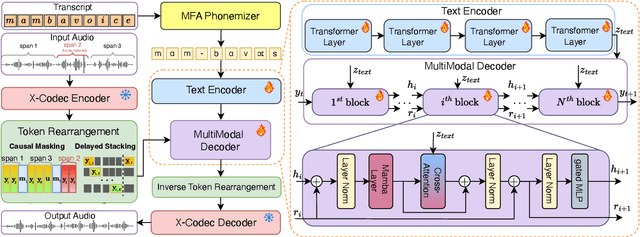
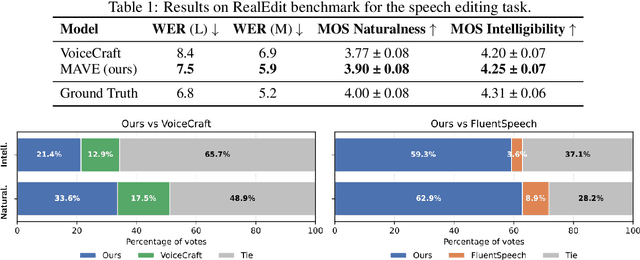


We introduce MAVE (Mamba with Cross-Attention for Voice Editing and Synthesis), a novel autoregressive architecture for text-conditioned voice editing and high-fidelity text-to-speech (TTS) synthesis, built on a cross-attentive Mamba backbone. MAVE achieves state-of-the-art performance in speech editing and very competitive results in zero-shot TTS, while not being explicitly trained on the latter task, outperforming leading autoregressive and diffusion models on diverse, real-world audio. By integrating Mamba for efficient audio sequence modeling with cross-attention for precise text-acoustic alignment, MAVE enables context-aware voice editing with exceptional naturalness and speaker consistency. In pairwise human evaluations on a random 40-sample subset of the RealEdit benchmark (400 judgments), 57.2% of listeners rated MAVE - edited speech as perceptually equal to the original, while 24.8% prefered the original and 18.0% MAVE - demonstrating that in the majority of cases edits are indistinguishable from the source. MAVE compares favorably with VoiceCraft and FluentSpeech both on pairwise comparisons and standalone mean opinion score (MOS) evaluations. For zero-shot TTS, MAVE exceeds VoiceCraft in both speaker similarity and naturalness, without requiring multiple inference runs or post-processing. Remarkably, these quality gains come with a significantly lower memory cost and approximately the same latency: MAVE requires ~6x less memory than VoiceCraft during inference on utterances from the RealEdit database (mean duration: 6.21s, A100, FP16, batch size 1). Our results demonstrate that MAVE establishes a new standard for flexible, high-fidelity voice editing and synthesis through the synergistic integration of structured state-space modeling and cross-modal attention.
COSPADI: Compressing LLMs via Calibration-Guided Sparse Dictionary Learning
Sep 26, 2025Post-training compression of large language models (LLMs) largely relies on low-rank weight approximation, which represents each column of a weight matrix in a shared low-dimensional subspace. While this is a computationally efficient strategy, the imposed structural constraint is rigid and can lead to a noticeable model accuracy drop. In this work, we propose CoSpaDi (Compression via Sparse Dictionary Learning), a novel training-free compression framework that replaces low-rank decomposition with a more flexible structured sparse factorization in which each weight matrix is represented with a dense dictionary and a column-sparse coefficient matrix. This formulation enables a union-of-subspaces representation: different columns of the original weight matrix are approximated in distinct subspaces spanned by adaptively selected dictionary atoms, offering greater expressiveness than a single invariant basis. Crucially, CoSpaDi leverages a small calibration dataset to optimize the factorization such that the output activations of compressed projection layers closely match those of the original ones, thereby minimizing functional reconstruction error rather than mere weight approximation. This data-aware strategy preserves better model fidelity without any fine-tuning under reasonable compression ratios. Moreover, the resulting structured sparsity allows efficient sparse-dense matrix multiplication and is compatible with post-training quantization for further memory and latency gains. We evaluate CoSpaDi across multiple Llama and Qwen models under per-layer and per-group settings at 20-50\% compression ratios, demonstrating consistent superiority over state-of-the-art data-aware low-rank methods both in accuracy and perplexity. Our results establish structured sparse dictionary learning as a powerful alternative to conventional low-rank approaches for efficient LLM deployment.
Share Your Attention: Transformer Weight Sharing via Matrix-based Dictionary Learning
Aug 06, 2025Large language models (LLMs) have revolutionized AI applications, yet their high computational and memory demands hinder their widespread deployment. Existing compression techniques focus on intra-block optimizations (e.g. low-rank approximation, attention head pruning), while the repetitive layered structure of transformers implies significant inter-block redundancy - a dimension largely unexplored beyond key-value (KV) caching. Inspired by dictionary learning in CNNs, we propose a framework for structured weight sharing across transformer layers. Our approach decomposes attention projection matrices into shared dictionary atoms, reducing the attention module's parameters by 66.7% while achieving on-par performance. Unlike complex methods requiring distillation or architectural changes, MASA (Matrix Atom Sharing in Attention) operates as a drop-in replacement - trained with standard optimizers - and represents each layer's weights as linear combinations of shared matrix atoms. Experiments across scales (100M-700M parameters) show that MASA achieves better benchmark accuracy and perplexity than grouped-query attention (GQA), low-rank baselines and recently proposed Repeat-all-over/Sequential sharing at comparable parameter budgets. Ablation studies confirm robustness to the dictionary size and the efficacy of shared representations in capturing cross-layer statistical regularities. Extending to Vision Transformers (ViT), MASA matches performance metrics on image classification and detection tasks with 66.7% fewer attention parameters. By combining dictionary learning strategies with transformer efficiency, MASA offers a scalable blueprint for parameter-efficient models without sacrificing performance. Finally, we investigate the possibility of employing MASA on pretrained LLMs to reduce their number of parameters without experiencing any significant drop in their performance.
ReplaceMe: Network Simplification via Layer Pruning and Linear Transformations
May 05, 2025We introduce ReplaceMe, a generalized training-free depth pruning method that effectively replaces transformer blocks with a linear operation, while maintaining high performance for low compression ratios. In contrast to conventional pruning approaches that require additional training or fine-tuning, our approach requires only a small calibration dataset that is used to estimate a linear transformation to approximate the pruned blocks. This estimated linear mapping can be seamlessly merged with the remaining transformer blocks, eliminating the need for any additional network parameters. Our experiments show that ReplaceMe consistently outperforms other training-free approaches and remains highly competitive with state-of-the-art pruning methods that involve extensive retraining/fine-tuning and architectural modifications. Applied to several large language models (LLMs), ReplaceMe achieves up to 25% pruning while retaining approximately 90% of the original model's performance on open benchmarks - without any training or healing steps, resulting in minimal computational overhead (see Fig.1). We provide an open-source library implementing ReplaceMe alongside several state-of-the-art depth pruning techniques, available at this repository.
A Modular Conditional Diffusion Framework for Image Reconstruction
Nov 08, 2024Diffusion Probabilistic Models (DPMs) have been recently utilized to deal with various blind image restoration (IR) tasks, where they have demonstrated outstanding performance in terms of perceptual quality. However, the task-specific nature of existing solutions and the excessive computational costs related to their training, make such models impractical and challenging to use for different IR tasks than those that were initially trained for. This hinders their wider adoption, especially by those who lack access to powerful computational resources and vast amount of training data. In this work we aim to address the above issues and enable the successful adoption of DPMs in practical IR-related applications. Towards this goal, we propose a modular diffusion probabilistic IR framework (DP-IR), which allows us to combine the performance benefits of existing pre-trained state-of-the-art IR networks and generative DPMs, while it requires only the additional training of a relatively small module (0.7M params) related to the particular IR task of interest. Moreover, the architecture of the proposed framework allows for a sampling strategy that leads to at least four times reduction of neural function evaluations without suffering any performance loss, while it can also be combined with existing acceleration techniques such as DDIM. We evaluate our model on four benchmarks for the tasks of burst JDD-SR, dynamic scene deblurring, and super-resolution. Our method outperforms existing approaches in terms of perceptual quality while it retains a competitive performance with respect to fidelity metrics.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022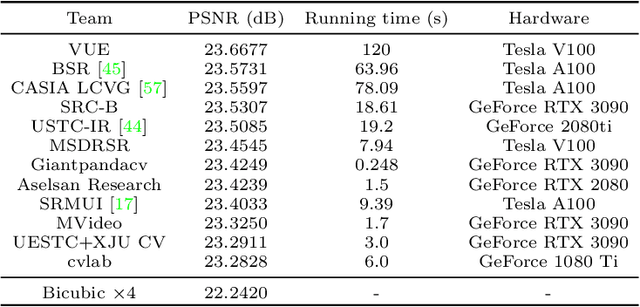
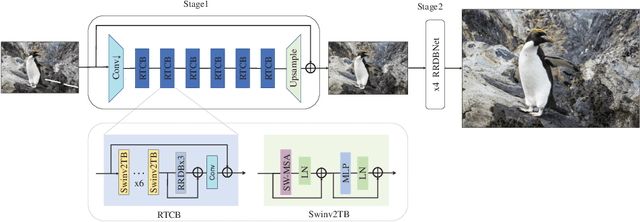

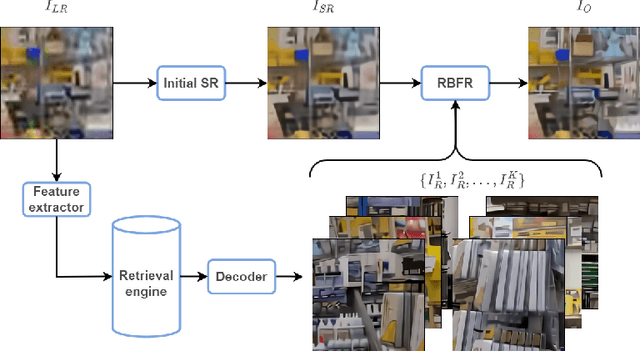
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
NTIRE 2021 Challenge on Burst Super-Resolution: Methods and Results
Jun 07, 2021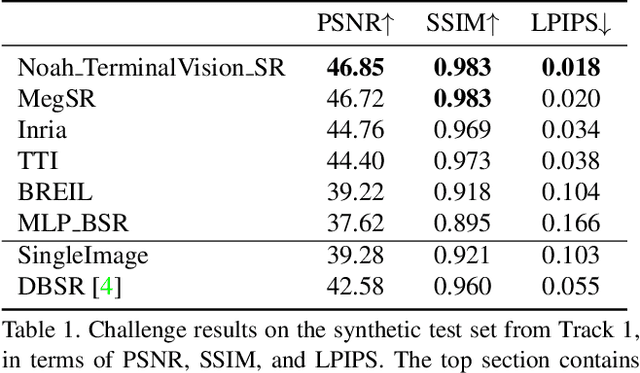

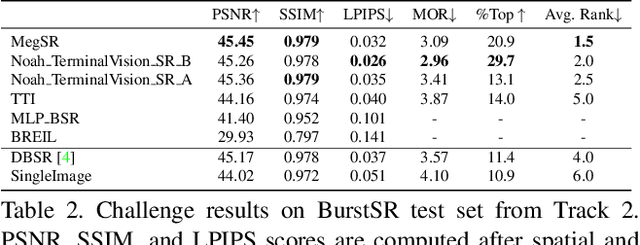

This paper reviews the NTIRE2021 challenge on burst super-resolution. Given a RAW noisy burst as input, the task in the challenge was to generate a clean RGB image with 4 times higher resolution. The challenge contained two tracks; Track 1 evaluating on synthetically generated data, and Track 2 using real-world bursts from mobile camera. In the final testing phase, 6 teams submitted results using a diverse set of solutions. The top-performing methods set a new state-of-the-art for the burst super-resolution task.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
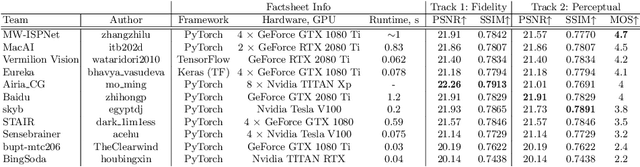
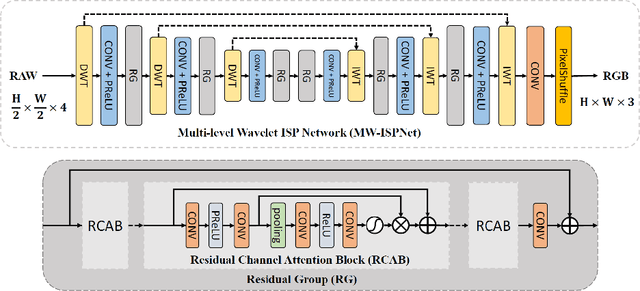
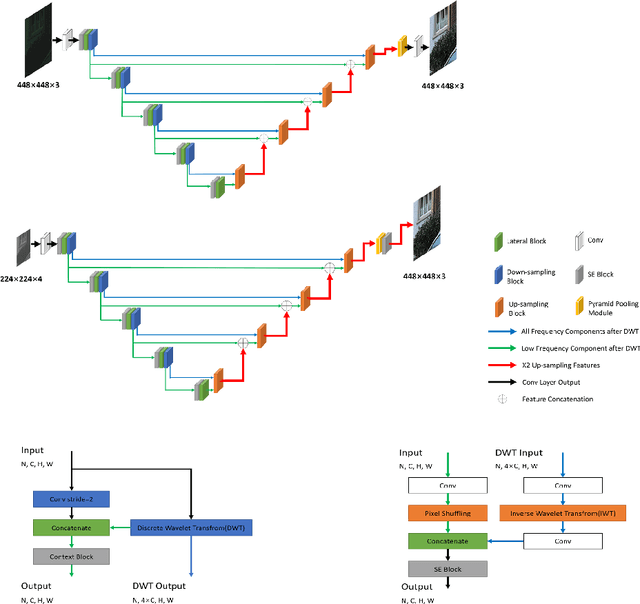
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.