 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMR. Video: "MapReduce" is the Principle for Long Video Understanding
Apr 22, 2025We propose MR. Video, an agentic long video understanding framework that demonstrates the simple yet effective MapReduce principle for processing long videos: (1) Map: independently and densely perceiving short video clips, and (2) Reduce: jointly aggregating information from all clips. Compared with sequence-to-sequence vision-language models (VLMs), MR. Video performs detailed short video perception without being limited by context length. Compared with existing video agents that typically rely on sequential key segment selection, the Map operation enables simpler and more scalable sequence parallel perception of short video segments. Its Reduce step allows for more comprehensive context aggregation and reasoning, surpassing explicit key segment retrieval. This MapReduce principle is applicable to both VLMs and video agents, and we use LLM agents to validate its effectiveness. In practice, MR. Video employs two MapReduce stages: (A) Captioning: generating captions for short video clips (map), then standardizing repeated characters and objects into shared names (reduce); (B) Analysis: for each user question, analyzing relevant information from individual short videos (map), and integrating them into a final answer (reduce). MR. Video achieves over 10% accuracy improvement on the challenging LVBench compared to state-of-the-art VLMs and video agents. Code is available at: https://github.com/ziqipang/MR-Video
Aligning Generative Denoising with Discriminative Objectives Unleashes Diffusion for Visual Perception
Apr 15, 2025



With the success of image generation, generative diffusion models are increasingly adopted for discriminative tasks, as pixel generation provides a unified perception interface. However, directly repurposing the generative denoising process for discriminative objectives reveals critical gaps rarely addressed previously. Generative models tolerate intermediate sampling errors if the final distribution remains plausible, but discriminative tasks require rigorous accuracy throughout, as evidenced in challenging multi-modal tasks like referring image segmentation. Motivated by this gap, we analyze and enhance alignment between generative diffusion processes and perception tasks, focusing on how perception quality evolves during denoising. We find: (1) earlier denoising steps contribute disproportionately to perception quality, prompting us to propose tailored learning objectives reflecting varying timestep contributions; (2) later denoising steps show unexpected perception degradation, highlighting sensitivity to training-denoising distribution shifts, addressed by our diffusion-tailored data augmentation; and (3) generative processes uniquely enable interactivity, serving as controllable user interfaces adaptable to correctional prompts in multi-round interactions. Our insights significantly improve diffusion-based perception models without architectural changes, achieving state-of-the-art performance on depth estimation, referring image segmentation, and generalist perception tasks. Code available at https://github.com/ziqipang/ADDP.
* ICLR 2025
AgMMU: A Comprehensive Agricultural Multimodal Understanding and Reasoning Benchmark
Apr 14, 2025We curate a dataset AgMMU for evaluating and developing vision-language models (VLMs) to produce factually accurate answers for knowledge-intensive expert domains. Our AgMMU concentrates on one of the most socially beneficial domains, agriculture, which requires connecting detailed visual observation with precise knowledge to diagnose, e.g., pest identification, management instructions, etc. As a core uniqueness of our dataset, all facts, questions, and answers are extracted from 116,231 conversations between real-world users and authorized agricultural experts. After a three-step dataset curation pipeline with GPT-4o, LLaMA models, and human verification, AgMMU features an evaluation set of 5,460 multiple-choice questions (MCQs) and open-ended questions (OEQs). We also provide a development set that contains 205,399 pieces of agricultural knowledge information, including disease identification, symptoms descriptions, management instructions, insect and pest identification, and species identification. As a multimodal factual dataset, it reveals that existing VLMs face significant challenges with questions requiring both detailed perception and factual knowledge. Moreover, open-source VLMs still demonstrate a substantial performance gap compared to proprietary ones. To advance knowledge-intensive VLMs, we conduct fine-tuning experiments using our development set, which improves LLaVA-1.5 evaluation accuracy by up to 3.1%. We hope that AgMMU can serve both as an evaluation benchmark dedicated to agriculture and a development suite for incorporating knowledge-intensive expertise into general-purpose VLMs.
GLUS: Global-Local Reasoning Unified into A Single Large Language Model for Video Segmentation
Apr 10, 2025
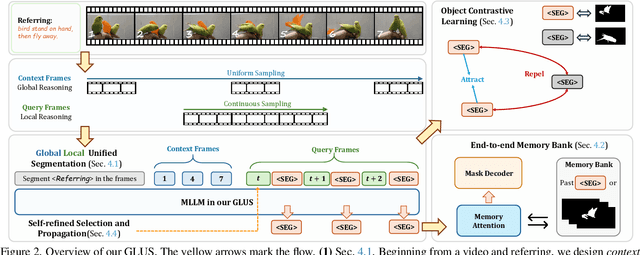
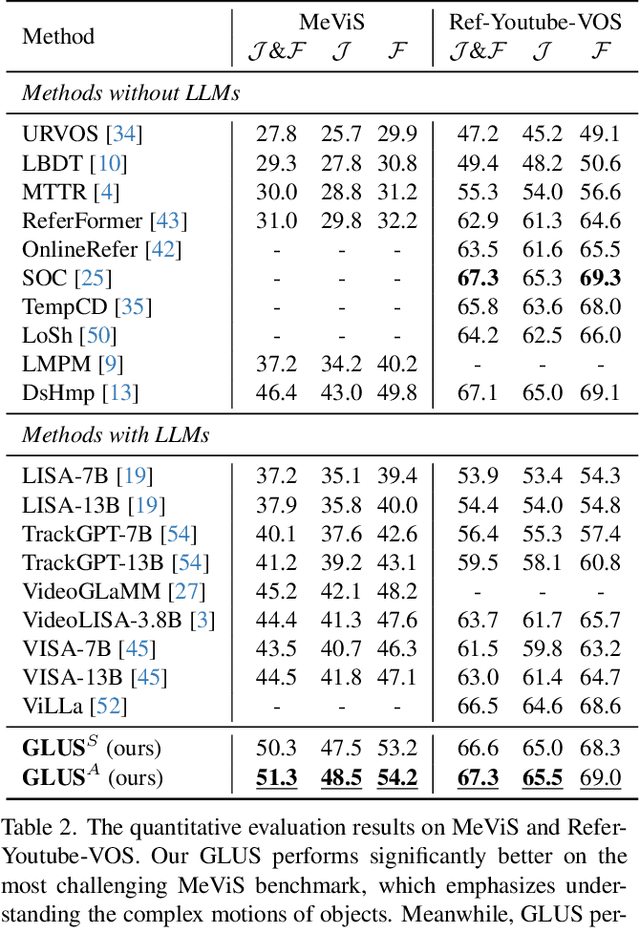
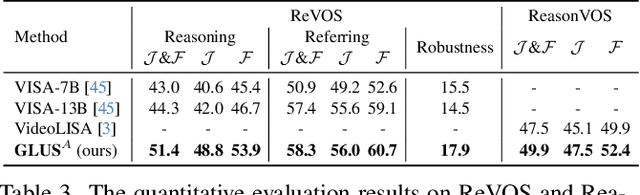
This paper proposes a novel framework utilizing multi-modal large language models (MLLMs) for referring video object segmentation (RefVOS). Previous MLLM-based methods commonly struggle with the dilemma between "Ref" and "VOS": they either specialize in understanding a few key frames (global reasoning) or tracking objects on continuous frames (local reasoning), and rely on external VOS or frame selectors to mitigate the other end of the challenge. However, our framework GLUS shows that global and local consistency can be unified into a single video segmentation MLLM: a set of sparse "context frames" provides global information, while a stream of continuous "query frames" conducts local object tracking. This is further supported by jointly training the MLLM with a pre-trained VOS memory bank to simultaneously digest short-range and long-range temporal information. To improve the information efficiency within the limited context window of MLLMs, we introduce object contrastive learning to distinguish hard false-positive objects and a self-refined framework to identify crucial frames and perform propagation. By collectively integrating these insights, our GLUS delivers a simple yet effective baseline, achieving new state-of-the-art for MLLMs on the MeViS and Ref-Youtube-VOS benchmark. Our project page is at https://glus-video.github.io/.
RandAR: Decoder-only Autoregressive Visual Generation in Random Orders
Dec 02, 2024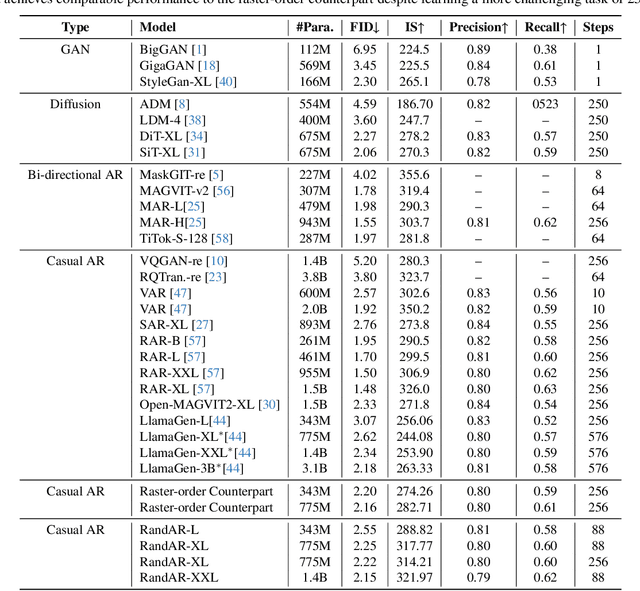
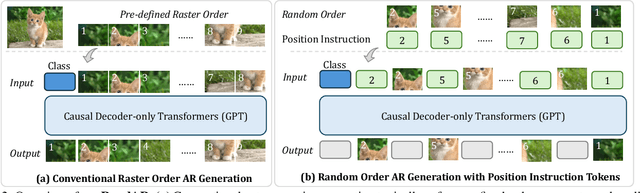
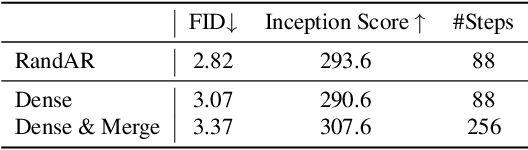
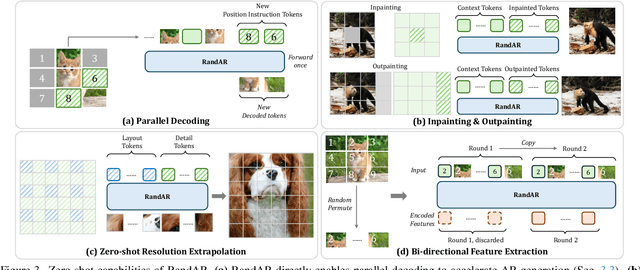
We introduce RandAR, a decoder-only visual autoregressive (AR) model capable of generating images in arbitrary token orders. Unlike previous decoder-only AR models that rely on a predefined generation order, RandAR removes this inductive bias, unlocking new capabilities in decoder-only generation. Our essential design enables random order by inserting a "position instruction token" before each image token to be predicted, representing the spatial location of the next image token. Trained on randomly permuted token sequences -- a more challenging task than fixed-order generation, RandAR achieves comparable performance to its conventional raster-order counterpart. More importantly, decoder-only transformers trained from random orders acquire new capabilities. For the efficiency bottleneck of AR models, RandAR adopts parallel decoding with KV-Cache at inference time, enjoying 2.5x acceleration without sacrificing generation quality. Additionally, RandAR supports inpainting, outpainting and resolution extrapolation in a zero-shot manner. We hope RandAR inspires new directions for decoder-only visual generation models and broadens their applications across diverse scenarios. Our project page is at https://rand-ar.github.io/.
InstructG2I: Synthesizing Images from Multimodal Attributed Graphs
Oct 09, 2024
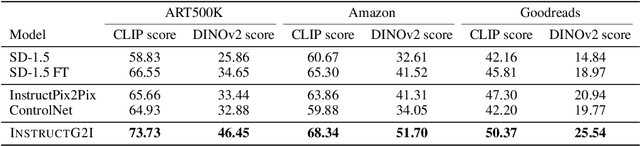

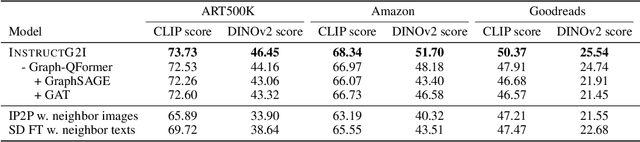
In this paper, we approach an overlooked yet critical task Graph2Image: generating images from multimodal attributed graphs (MMAGs). This task poses significant challenges due to the explosion in graph size, dependencies among graph entities, and the need for controllability in graph conditions. To address these challenges, we propose a graph context-conditioned diffusion model called InstructG2I. InstructG2I first exploits the graph structure and multimodal information to conduct informative neighbor sampling by combining personalized page rank and re-ranking based on vision-language features. Then, a Graph-QFormer encoder adaptively encodes the graph nodes into an auxiliary set of graph prompts to guide the denoising process of diffusion. Finally, we propose graph classifier-free guidance, enabling controllable generation by varying the strength of graph guidance and multiple connected edges to a node. Extensive experiments conducted on three datasets from different domains demonstrate the effectiveness and controllability of our approach. The code is available at https://github.com/PeterGriffinJin/InstructG2I.
* 16 pages
RMem: Restricted Memory Banks Improve Video Object Segmentation
Jun 12, 2024



With recent video object segmentation (VOS) benchmarks evolving to challenging scenarios, we revisit a simple but overlooked strategy: restricting the size of memory banks. This diverges from the prevalent practice of expanding memory banks to accommodate extensive historical information. Our specially designed "memory deciphering" study offers a pivotal insight underpinning such a strategy: expanding memory banks, while seemingly beneficial, actually increases the difficulty for VOS modules to decode relevant features due to the confusion from redundant information. By restricting memory banks to a limited number of essential frames, we achieve a notable improvement in VOS accuracy. This process balances the importance and freshness of frames to maintain an informative memory bank within a bounded capacity. Additionally, restricted memory banks reduce the training-inference discrepancy in memory lengths compared with continuous expansion. This fosters new opportunities in temporal reasoning and enables us to introduce the previously overlooked "temporal positional embedding." Finally, our insights are embodied in "RMem" ("R" for restricted), a simple yet effective VOS modification that excels at challenging VOS scenarios and establishes new state of the art for object state changes (on the VOST dataset) and long videos (on the Long Videos dataset). Our code and demo are available at https://restricted-memory.github.io/.
Frozen Transformers in Language Models Are Effective Visual Encoder Layers
Oct 19, 2023This paper reveals that large language models (LLMs), despite being trained solely on textual data, are surprisingly strong encoders for purely visual tasks in the absence of language. Even more intriguingly, this can be achieved by a simple yet previously overlooked strategy -- employing a frozen transformer block from pre-trained LLMs as a constituent encoder layer to directly process visual tokens. Our work pushes the boundaries of leveraging LLMs for computer vision tasks, significantly departing from conventional practices that typically necessitate a multi-modal vision-language setup with associated language prompts, inputs, or outputs. We demonstrate that our approach consistently enhances performance across a diverse range of tasks, encompassing pure 2D and 3D visual recognition tasks (e.g., image and point cloud classification), temporal modeling tasks (e.g., action recognition), non-semantic tasks (e.g., motion forecasting), and multi-modal tasks (e.g., 2D/3D visual question answering and image-text retrieval). Such improvements are a general phenomenon, applicable to various types of LLMs (e.g., LLaMA and OPT) and different LLM transformer blocks. We additionally propose the information filtering hypothesis to explain the effectiveness of pre-trained LLMs in visual encoding -- the pre-trained LLM transformer blocks discern informative visual tokens and further amplify their effect. This hypothesis is empirically supported by the observation that the feature activation, after training with LLM transformer blocks, exhibits a stronger focus on relevant regions. We hope that our work inspires new perspectives on utilizing LLMs and deepening our understanding of their underlying mechanisms. Code is available at https://github.com/ziqipang/LM4VisualEncoding.
Streaming Motion Forecasting for Autonomous Driving
Oct 02, 2023Trajectory forecasting is a widely-studied problem for autonomous navigation. However, existing benchmarks evaluate forecasting based on independent snapshots of trajectories, which are not representative of real-world applications that operate on a continuous stream of data. To bridge this gap, we introduce a benchmark that continuously queries future trajectories on streaming data and we refer to it as "streaming forecasting." Our benchmark inherently captures the disappearance and re-appearance of agents, presenting the emergent challenge of forecasting for occluded agents, which is a safety-critical problem yet overlooked by snapshot-based benchmarks. Moreover, forecasting in the context of continuous timestamps naturally asks for temporal coherence between predictions from adjacent timestamps. Based on this benchmark, we further provide solutions and analysis for streaming forecasting. We propose a plug-and-play meta-algorithm called "Predictive Streamer" that can adapt any snapshot-based forecaster into a streaming forecaster. Our algorithm estimates the states of occluded agents by propagating their positions with multi-modal trajectories, and leverages differentiable filters to ensure temporal consistency. Both occlusion reasoning and temporal coherence strategies significantly improve forecasting quality, resulting in 25% smaller endpoint errors for occluded agents and 10-20% smaller fluctuations of trajectories. Our work is intended to generate interest within the community by highlighting the importance of addressing motion forecasting in its intrinsic streaming setting. Code is available at https://github.com/ziqipang/StreamingForecasting.
MV-Map: Offboard HD-Map Generation with Multi-view Consistency
May 15, 2023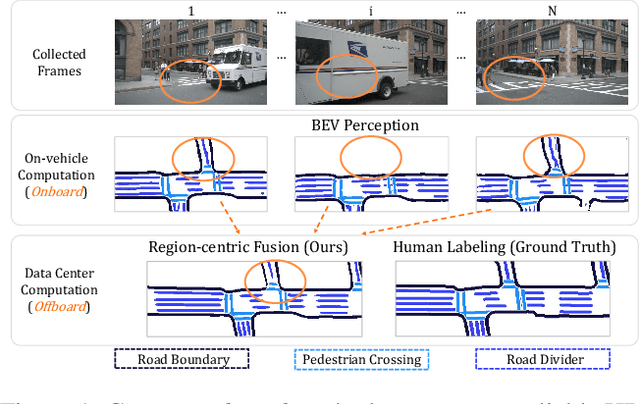



While bird's-eye-view (BEV) perception models can be useful for building high-definition maps (HD-Maps) with less human labor, their results are often unreliable and demonstrate noticeable inconsistencies in the predicted HD-Maps from different viewpoints. This is because BEV perception is typically set up in an 'onboard' manner, which restricts the computation and consequently prevents algorithms from reasoning multiple views simultaneously. This paper overcomes these limitations and advocates a more practical 'offboard' HD-Map generation setup that removes the computation constraints, based on the fact that HD-Maps are commonly reusable infrastructures built offline in data centers. To this end, we propose a novel offboard pipeline called MV-Map that capitalizes multi-view consistency and can handle an arbitrary number of frames with the key design of a 'region-centric' framework. In MV-Map, the target HD-Maps are created by aggregating all the frames of onboard predictions, weighted by the confidence scores assigned by an 'uncertainty network'. To further enhance multi-view consistency, we augment the uncertainty network with the global 3D structure optimized by a voxelized neural radiance field (Voxel-NeRF). Extensive experiments on nuScenes show that our MV-Map significantly improves the quality of HD-Maps, further highlighting the importance of offboard methods for HD-Map generation.