 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fragile Guardrail: Diffusion LLM's Safety Blessing and Its Failure Mode
Jan 30, 2026Diffusion large language models (D-LLMs) offer an alternative to autoregressive LLMs (AR-LLMs) and have demonstrated advantages in generation efficiency. Beyond the utility benefits, we argue that D-LLMs exhibit a previously underexplored safety blessing: their diffusion-style generation confers intrinsic robustness against jailbreak attacks originally designed for AR-LLMs. In this work, we provide an initial analysis of the underlying mechanism, showing that the diffusion trajectory induces a stepwise reduction effect that progressively suppresses unsafe generations. This robustness, however, is not absolute. We identify a simple yet effective failure mode, termed context nesting, where harmful requests are embedded within structured benign contexts, effectively bypassing the stepwise reduction mechanism. Empirically, we show that this simple strategy is sufficient to bypass D-LLMs' safety blessing, achieving state-of-the-art attack success rates across models and benchmarks. Most notably, it enables the first successful jailbreak of Gemini Diffusion, to our knowledge, exposing a critical vulnerability in commercial D-LLMs. Together, our results characterize both the origins and the limits of D-LLMs' safety blessing, constituting an early-stage red-teaming of D-LLMs.
GLUS: Global-Local Reasoning Unified into A Single Large Language Model for Video Segmentation
Apr 10, 2025
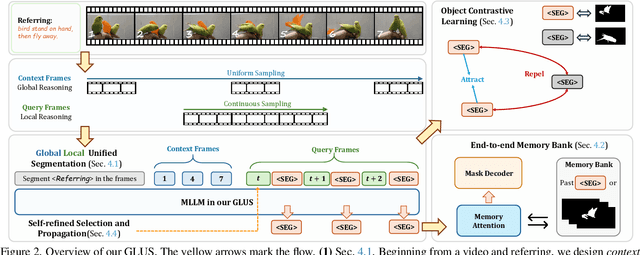
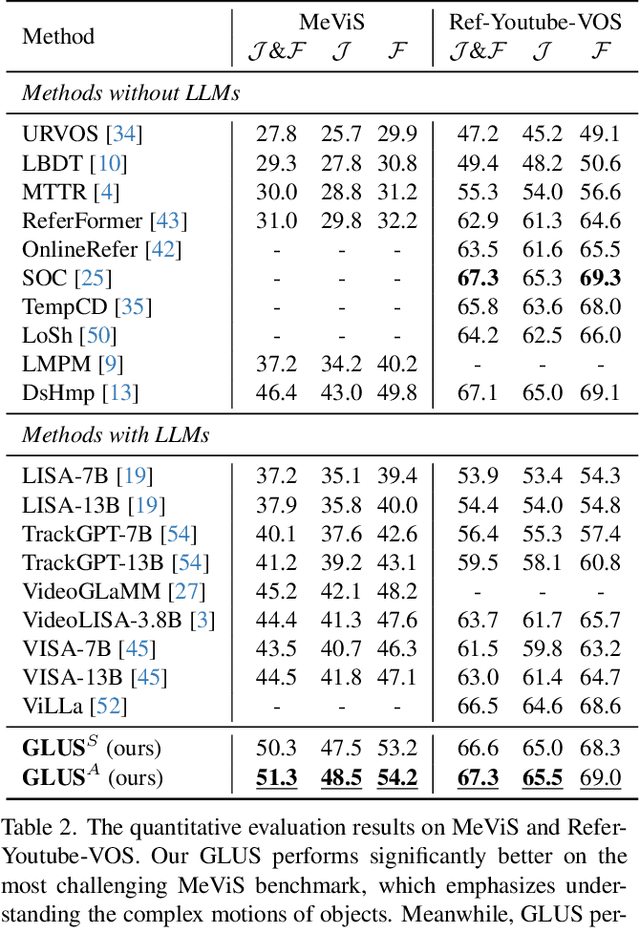
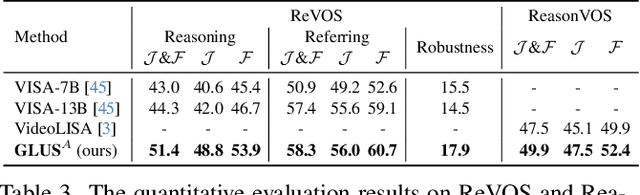
This paper proposes a novel framework utilizing multi-modal large language models (MLLMs) for referring video object segmentation (RefVOS). Previous MLLM-based methods commonly struggle with the dilemma between "Ref" and "VOS": they either specialize in understanding a few key frames (global reasoning) or tracking objects on continuous frames (local reasoning), and rely on external VOS or frame selectors to mitigate the other end of the challenge. However, our framework GLUS shows that global and local consistency can be unified into a single video segmentation MLLM: a set of sparse "context frames" provides global information, while a stream of continuous "query frames" conducts local object tracking. This is further supported by jointly training the MLLM with a pre-trained VOS memory bank to simultaneously digest short-range and long-range temporal information. To improve the information efficiency within the limited context window of MLLMs, we introduce object contrastive learning to distinguish hard false-positive objects and a self-refined framework to identify crucial frames and perform propagation. By collectively integrating these insights, our GLUS delivers a simple yet effective baseline, achieving new state-of-the-art for MLLMs on the MeViS and Ref-Youtube-VOS benchmark. Our project page is at https://glus-video.github.io/.
Improving Location-based Thermal Emission Side-Channel Analysis Using Iterative Transfer Learning
Dec 30, 2024



This paper proposes the use of iterative transfer learning applied to deep learning models for side-channel attacks. Currently, most of the side-channel attack methods train a model for each individual byte, without considering the correlation between bytes. However, since the models' parameters for attacking different bytes may be similar, we can leverage transfer learning, meaning that we first train the model for one of the key bytes, then use the trained model as a pretrained model for the remaining bytes. This technique can be applied iteratively, a process known as iterative transfer learning. Experimental results show that when using thermal or power consumption map images as input, and multilayer perceptron or convolutional neural network as the model, our method improves average performance, especially when the amount of data is insufficient.
A Plug-and-Play Defensive Perturbation for Copyright Protection of DNN-based Applications
Apr 20, 2023

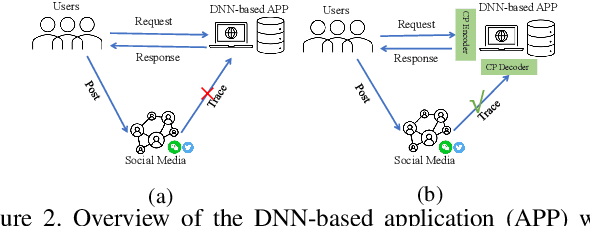

Wide deployment of deep neural networks (DNNs) based applications (e.g., style transfer, cartoonish), stimulating the requirement of copyright protection of such application's production. Although some traditional visible copyright techniques are available, they would introduce undesired traces and result in a poor user experience. In this paper, we propose a novel plug-and-play invisible copyright protection method based on defensive perturbation for DNN-based applications (i.e., style transfer). Rather than apply the perturbation to attack the DNNs model, we explore the potential utilization of perturbation in copyright protection. Specifically, we project the copyright information to the defensive perturbation with the designed copyright encoder, which is added to the image to be protected. Then, we extract the copyright information from the encoded copyrighted image with the devised copyright decoder. Furthermore, we use a robustness module to strengthen the decoding capability of the decoder toward images with various distortions (e.g., JPEG compression), which may be occurred when the user posts the image on social media. To ensure the image quality of encoded images and decoded copyright images, a loss function was elaborately devised. Objective and subjective experiment results demonstrate the effectiveness of the proposed method. We have also conducted physical world tests on social media (i.e., Wechat and Twitter) by posting encoded copyright images. The results show that the copyright information in the encoded image saved from social media can still be correctly extracted.