 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Multi-view Black-box Attack against Object Detectors via Layout Optimization
Jul 09, 2024



Object detectors have demonstrated vulnerability to adversarial examples crafted by small perturbations that can deceive the object detector. Existing adversarial attacks mainly focus on white-box attacks and are merely valid at a specific viewpoint, while the universal multi-view black-box attack is less explored, limiting their generalization in practice. In this paper, we propose a novel universal multi-view black-box attack against object detectors, which optimizes a universal adversarial UV texture constructed by multiple image stickers for a 3D object via the designed layout optimization algorithm. Specifically, we treat the placement of image stickers on the UV texture as a circle-based layout optimization problem, whose objective is to find the optimal circle layout filled with image stickers so that it can deceive the object detector under the multi-view scenario. To ensure reasonable placement of image stickers, two constraints are elaborately devised. To optimize the layout, we adopt the random search algorithm enhanced by the devised important-aware selection strategy to find the most appropriate image sticker for each circle from the image sticker pools. Extensive experiments conducted on four common object detectors suggested that the detection performance decreases by a large magnitude of 74.29% on average in multi-view scenarios. Additionally, a novel evaluation tool based on the photo-realistic simulator is designed to assess the texture-based attack fairly.
Universal Perturbation-based Secret Key-Controlled Data Hiding
Nov 03, 2023



Deep neural networks (DNNs) are demonstrated to be vulnerable to universal perturbation, a single quasi-perceptible perturbation that can deceive the DNN on most images. However, the previous works are focused on using universal perturbation to perform adversarial attacks, while the potential usability of universal perturbation as data carriers in data hiding is less explored, especially for the key-controlled data hiding method. In this paper, we propose a novel universal perturbation-based secret key-controlled data-hiding method, realizing data hiding with a single universal perturbation and data decoding with the secret key-controlled decoder. Specifically, we optimize a single universal perturbation, which serves as a data carrier that can hide multiple secret images and be added to most cover images. Then, we devise a secret key-controlled decoder to extract different secret images from the single container image constructed by the universal perturbation by using different secret keys. Moreover, a suppress loss function is proposed to prevent the secret image from leakage. Furthermore, we adopt a robust module to boost the decoder's capability against corruption. Finally, A co-joint optimization strategy is proposed to find the optimal universal perturbation and decoder. Extensive experiments are conducted on different datasets to demonstrate the effectiveness of the proposed method. Additionally, the physical test performed on platforms (e.g., WeChat and Twitter) verifies the usability of the proposed method in practice.
Adversarial Examples in the Physical World: A Survey
Nov 01, 2023Deep neural networks (DNNs) have demonstrated high vulnerability to adversarial examples. Besides the attacks in the digital world, the practical implications of adversarial examples in the physical world present significant challenges and safety concerns. However, current research on physical adversarial examples (PAEs) lacks a comprehensive understanding of their unique characteristics, leading to limited significance and understanding. In this paper, we address this gap by thoroughly examining the characteristics of PAEs within a practical workflow encompassing training, manufacturing, and re-sampling processes. By analyzing the links between physical adversarial attacks, we identify manufacturing and re-sampling as the primary sources of distinct attributes and particularities in PAEs. Leveraging this knowledge, we develop a comprehensive analysis and classification framework for PAEs based on their specific characteristics, covering over 100 studies on physical-world adversarial examples. Furthermore, we investigate defense strategies against PAEs and identify open challenges and opportunities for future research. We aim to provide a fresh, thorough, and systematic understanding of PAEs, thereby promoting the development of robust adversarial learning and its application in open-world scenarios.
RFLA: A Stealthy Reflected Light Adversarial Attack in the Physical World
Jul 14, 2023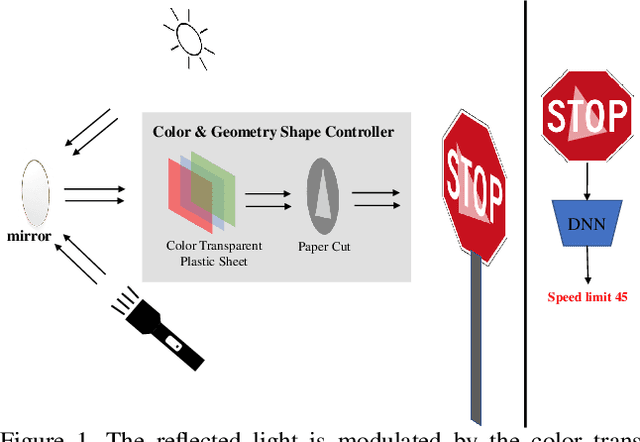


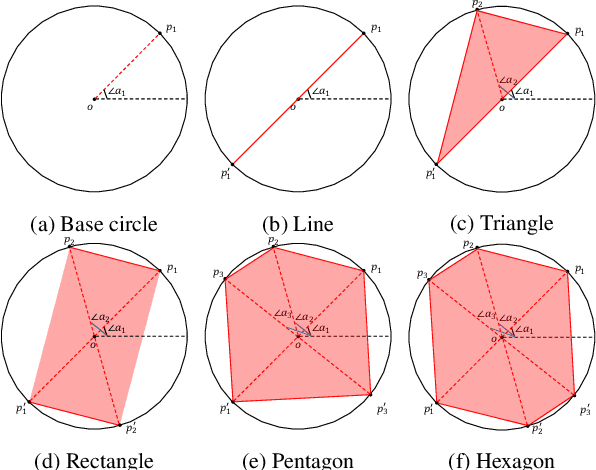
Physical adversarial attacks against deep neural networks (DNNs) have recently gained increasing attention. The current mainstream physical attacks use printed adversarial patches or camouflage to alter the appearance of the target object. However, these approaches generate conspicuous adversarial patterns that show poor stealthiness. Another physical deployable attack is the optical attack, featuring stealthiness while exhibiting weakly in the daytime with sunlight. In this paper, we propose a novel Reflected Light Attack (RFLA), featuring effective and stealthy in both the digital and physical world, which is implemented by placing the color transparent plastic sheet and a paper cut of a specific shape in front of the mirror to create different colored geometries on the target object. To achieve these goals, we devise a general framework based on the circle to model the reflected light on the target object. Specifically, we optimize a circle (composed of a coordinate and radius) to carry various geometrical shapes determined by the optimized angle. The fill color of the geometry shape and its corresponding transparency are also optimized. We extensively evaluate the effectiveness of RFLA on different datasets and models. Experiment results suggest that the proposed method achieves over 99% success rate on different datasets and models in the digital world. Additionally, we verify the effectiveness of the proposed method in different physical environments by using sunlight or a flashlight.
Impact of Light and Shadow on Robustness of Deep Neural Networks
May 23, 2023Deep neural networks (DNNs) have made remarkable strides in various computer vision tasks, including image classification, segmentation, and object detection. However, recent research has revealed a vulnerability in advanced DNNs when faced with deliberate manipulations of input data, known as adversarial attacks. Moreover, the accuracy of DNNs is heavily influenced by the distribution of the training dataset. Distortions or perturbations in the color space of input images can introduce out-of-distribution data, resulting in misclassification. In this work, we propose a brightness-variation dataset, which incorporates 24 distinct brightness levels for each image within a subset of ImageNet. This dataset enables us to simulate the effects of light and shadow on the images, so as is to investigate the impact of light and shadow on the performance of DNNs. In our study, we conduct experiments using several state-of-the-art DNN architectures on the aforementioned dataset. Through our analysis, we discover a noteworthy positive correlation between the brightness levels and the loss of accuracy in DNNs. Furthermore, we assess the effectiveness of recently proposed robust training techniques and strategies, including AugMix, Revisit, and Free Normalizer, using the ResNet50 architecture on our brightness-variation dataset. Our experimental results demonstrate that these techniques can enhance the robustness of DNNs against brightness variation, leading to improved performance when dealing with images exhibiting varying brightness levels.
A Plug-and-Play Defensive Perturbation for Copyright Protection of DNN-based Applications
Apr 20, 2023

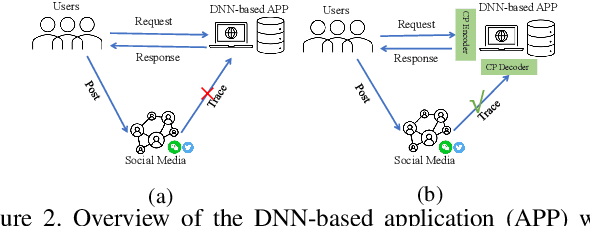

Wide deployment of deep neural networks (DNNs) based applications (e.g., style transfer, cartoonish), stimulating the requirement of copyright protection of such application's production. Although some traditional visible copyright techniques are available, they would introduce undesired traces and result in a poor user experience. In this paper, we propose a novel plug-and-play invisible copyright protection method based on defensive perturbation for DNN-based applications (i.e., style transfer). Rather than apply the perturbation to attack the DNNs model, we explore the potential utilization of perturbation in copyright protection. Specifically, we project the copyright information to the defensive perturbation with the designed copyright encoder, which is added to the image to be protected. Then, we extract the copyright information from the encoded copyrighted image with the devised copyright decoder. Furthermore, we use a robustness module to strengthen the decoding capability of the decoder toward images with various distortions (e.g., JPEG compression), which may be occurred when the user posts the image on social media. To ensure the image quality of encoded images and decoded copyright images, a loss function was elaborately devised. Objective and subjective experiment results demonstrate the effectiveness of the proposed method. We have also conducted physical world tests on social media (i.e., Wechat and Twitter) by posting encoded copyright images. The results show that the copyright information in the encoded image saved from social media can still be correctly extracted.
A Survey on Physical Adversarial Attack in Computer Vision
Sep 28, 2022



In the past decade, deep learning has dramatically changed the traditional hand-craft feature manner with strong feature learning capability, resulting in tremendous improvement of conventional tasks. However, deep neural networks have recently been demonstrated vulnerable to adversarial examples, a kind of malicious samples crafted by small elaborately designed noise, which mislead the DNNs to make the wrong decisions while remaining imperceptible to humans. Adversarial examples can be divided into digital adversarial attacks and physical adversarial attacks. The digital adversarial attack is mostly performed in lab environments, focusing on improving the performance of adversarial attack algorithms. In contrast, the physical adversarial attack focus on attacking the physical world deployed DNN systems, which is a more challenging task due to the complex physical environment (i.e., brightness, occlusion, and so on). Although the discrepancy between digital adversarial and physical adversarial examples is small, the physical adversarial examples have a specific design to overcome the effect of the complex physical environment. In this paper, we review the development of physical adversarial attacks in DNN-based computer vision tasks, including image recognition tasks, object detection tasks, and semantic segmentation. For the sake of completeness of the algorithm evolution, we will briefly introduce the works that do not involve the physical adversarial attack. We first present a categorization scheme to summarize the current physical adversarial attacks. Then discuss the advantages and disadvantages of the existing physical adversarial attacks and focus on the technique used to maintain the adversarial when applied into physical environment. Finally, we point out the issues of the current physical adversarial attacks to be solved and provide promising research directions.