 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Real-World Autonomous Driving by Learning to Predict and Plan with a Mixture of Experts
Nov 03, 2022The goal of autonomous vehicles is to navigate public roads safely and comfortably. To enforce safety, traditional planning approaches rely on handcrafted rules to generate trajectories. Machine learning-based systems, on the other hand, scale with data and are able to learn more complex behaviors. However, they often ignore that agents and self-driving vehicle trajectory distributions can be leveraged to improve safety. In this paper, we propose modeling a distribution over multiple future trajectories for both the self-driving vehicle and other road agents, using a unified neural network architecture for prediction and planning. During inference, we select the planning trajectory that minimizes a cost taking into account safety and the predicted probabilities. Our approach does not depend on any rule-based planners for trajectory generation or optimization, improves with more training data and is simple to implement. We extensively evaluate our method through a realistic simulator and show that the predicted trajectory distribution corresponds to different driving profiles. We also successfully deploy it on a self-driving vehicle on urban public roads, confirming that it drives safely without compromising comfort. The code for training and testing our model on a public prediction dataset and the video of the road test are available at https://woven.mobi/safepathnet
CW-ERM: Improving Autonomous Driving Planning with Closed-loop Weighted Empirical Risk Minimization
Oct 11, 2022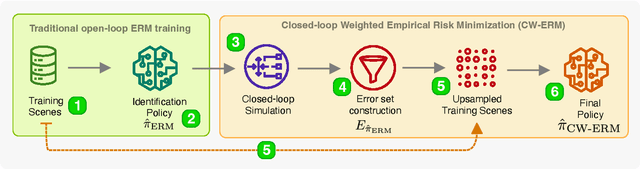
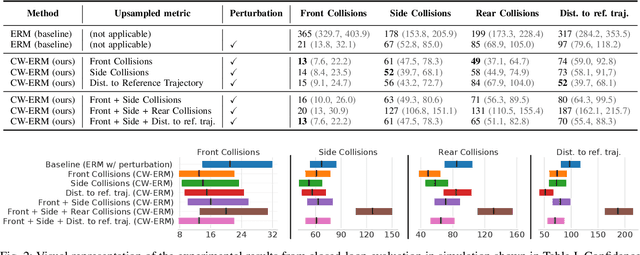
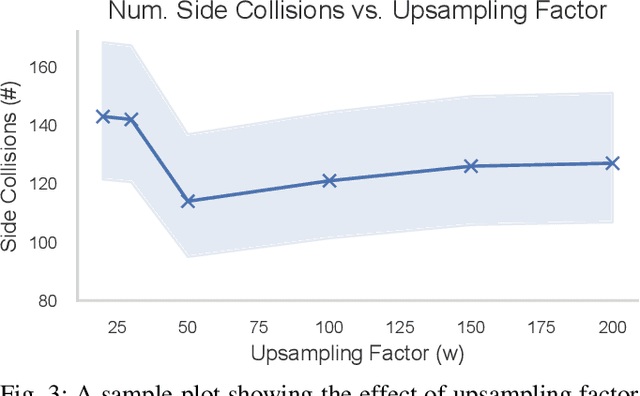
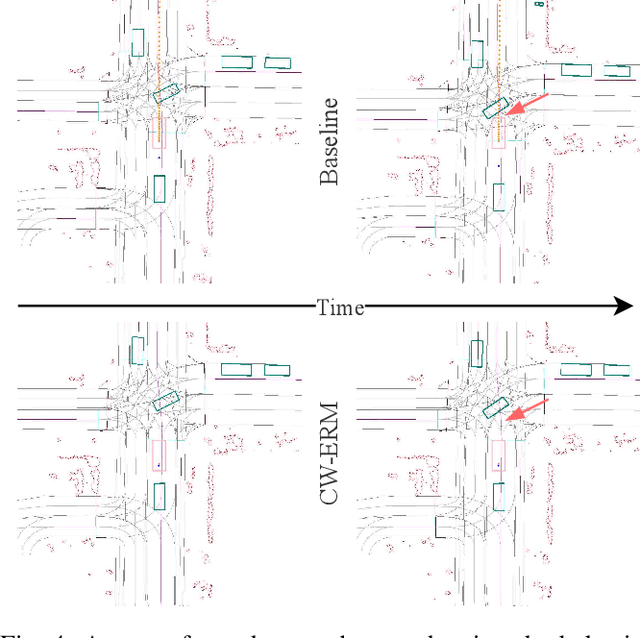
The imitation learning of self-driving vehicle policies through behavioral cloning is often carried out in an open-loop fashion, ignoring the effect of actions to future states. Training such policies purely with Empirical Risk Minimization (ERM) can be detrimental to real-world performance, as it biases policy networks towards matching only open-loop behavior, showing poor results when evaluated in closed-loop. In this work, we develop an efficient and simple-to-implement principle called Closed-loop Weighted Empirical Risk Minimization (CW-ERM), in which a closed-loop evaluation procedure is first used to identify training data samples that are important for practical driving performance and then we these samples to help debias the policy network. We evaluate CW-ERM in a challenging urban driving dataset and show that this procedure yields a significant reduction in collisions as well as other non-differentiable closed-loop metrics.
L2M: Practical posterior Laplace approximation with optimization-driven second moment estimation
Jul 09, 2021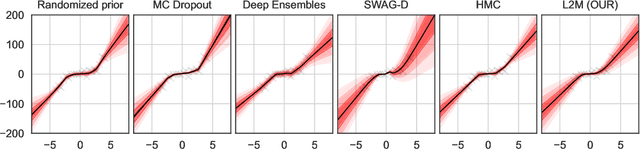
Uncertainty quantification for deep neural networks has recently evolved through many techniques. In this work, we revisit Laplace approximation, a classical approach for posterior approximation that is computationally attractive. However, instead of computing the curvature matrix, we show that, under some regularity conditions, the Laplace approximation can be easily constructed using the gradient second moment. This quantity is already estimated by many exponential moving average variants of Adagrad such as Adam and RMSprop, but is traditionally discarded after training. We show that our method (L2M) does not require changes in models or optimization, can be implemented in a few lines of code to yield reasonable results, and it does not require any extra computational steps besides what is already being computed by optimizers, without introducing any new hyperparameter. We hope our method can open new research directions on using quantities already computed by optimizers for uncertainty estimation in deep neural networks.
U-Net Fixed-Point Quantization for Medical Image Segmentation
Sep 09, 2019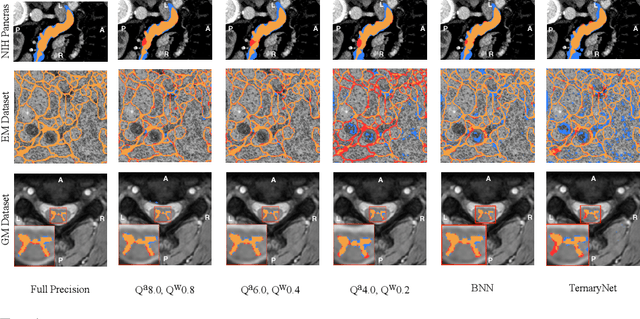
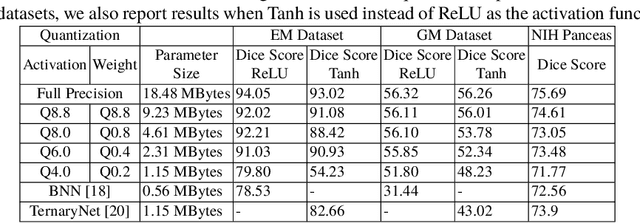
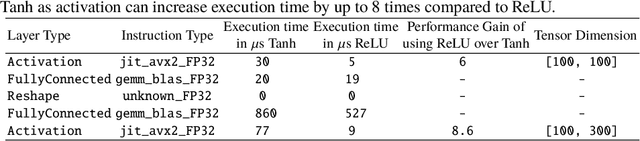
Model quantization is leveraged to reduce the memory consumption and the computation time of deep neural networks. This is achieved by representing weights and activations with a lower bit resolution when compared to their high precision floating point counterparts. The suitable level of quantization is directly related to the model performance. Lowering the quantization precision (e.g. 2 bits), reduces the amount of memory required to store model parameters and the amount of logic required to implement computational blocks, which contributes to reducing the power consumption of the entire system. These benefits typically come at the cost of reduced accuracy. The main challenge is to quantize a network as much as possible, while maintaining the performance accuracy. In this work, we present a quantization method for the U-Net architecture, a popular model in medical image segmentation. We then apply our quantization algorithm to three datasets: (1) the Spinal Cord Gray Matter Segmentation (GM), (2) the ISBI challenge for segmentation of neuronal structures in Electron Microscopic (EM), and (3) the public National Institute of Health (NIH) dataset for pancreas segmentation in abdominal CT scans. The reported results demonstrate that with only 4 bits for weights and 6 bits for activations, we obtain 8 fold reduction in memory requirements while loosing only 2.21%, 0.57% and 2.09% dice overlap score for EM, GM and NIH datasets respectively. Our fixed point quantization provides a flexible trade off between accuracy and memory requirement which is not provided by previous quantization methods for U-Net such as TernaryNet.
Deep Active Learning for Axon-Myelin Segmentation on Histology Data
Jul 11, 2019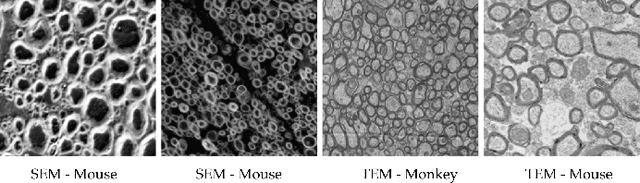
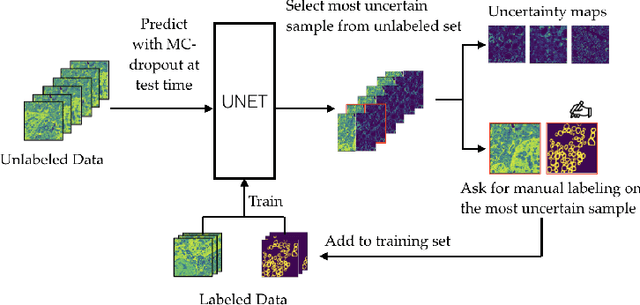
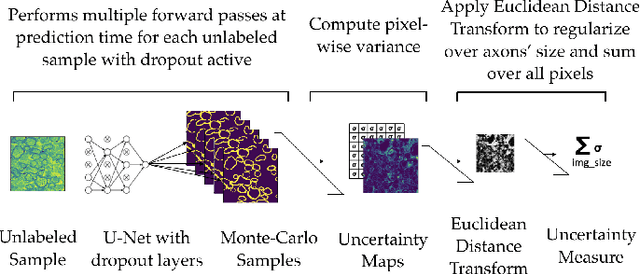

Semantic segmentation is a crucial task in biomedical image processing, which recent breakthroughs in deep learning have allowed to improve. However, deep learning methods in general are not yet widely used in practice since they require large amount of data for training complex models. This is particularly challenging for biomedical images, because data and ground truths are a scarce resource. Annotation efforts for biomedical images come with a real cost, since experts have to manually label images at pixel-level on samples usually containing many instances of the target anatomy (e.g. in histology samples: neurons, astrocytes, mitochondria, etc.). In this paper we provide a framework for Deep Active Learning applied to a real-world scenario. Our framework relies on the U-Net architecture and overall uncertainty measure to suggest which sample to annotate. It takes advantage of the uncertainty measure obtained by taking Monte Carlo samples while using Dropout regularization scheme. Experiments were done on spinal cord and brain microscopic histology samples to perform a myelin segmentation task. Two realistic small datasets of 14 and 24 images were used, from different acquisition settings (Serial Block-Face Electron Microscopy and Transmitting Electron Microscopy) and showed that our method reached a maximum Dice value after adding 3 uncertainty-selected samples to the initial training set, versus 15 randomly-selected samples, thereby significantly reducing the annotation effort. We focused on a plausible scenario and showed evidence that this straightforward implementation achieves a high segmentation performance with very few labelled samples. We believe our framework may benefit any biomedical researcher willing to obtain fast and accurate image segmentation on their own dataset. The code is freely available at https://github.com/neuropoly/deep-active-learning.
The Impact of Feature Causality on Normal Behaviour Models for SCADA-based Wind Turbine Fault Detection
Jun 28, 2019

The cost of wind energy can be reduced by using SCADA data to detect faults in wind turbine components. Normal behavior models are one of the main fault detection approaches, but there is a lack of consensus in how different input features affect the results. In this work, a new taxonomy based on the causal relations between the input features and the target is presented. Based on this taxonomy, the impact of different input feature configurations on the modelling and fault detection performance is evaluated. To this end, a framework that formulates the detection of faults as a classification problem is also presented.
Unsupervised domain adaptation for medical imaging segmentation with self-ensembling
Nov 14, 2018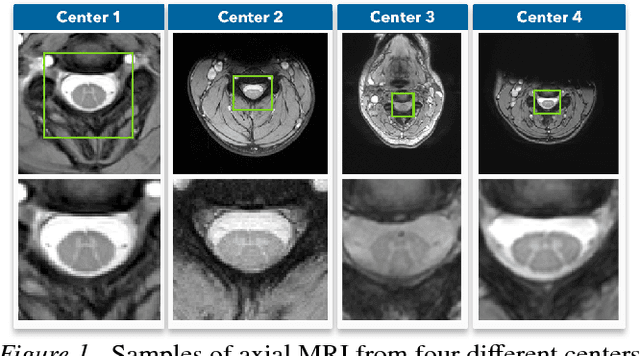
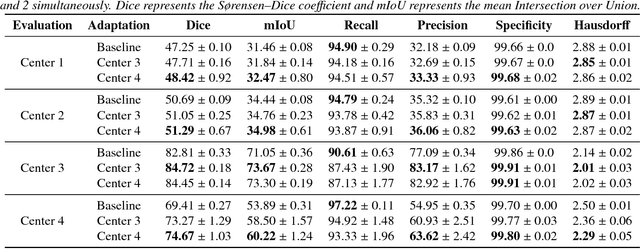
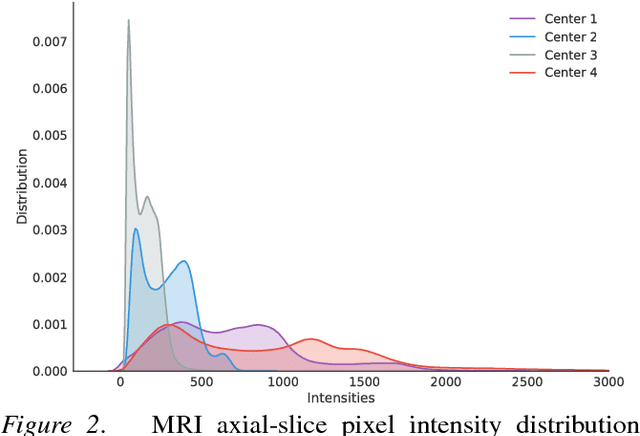
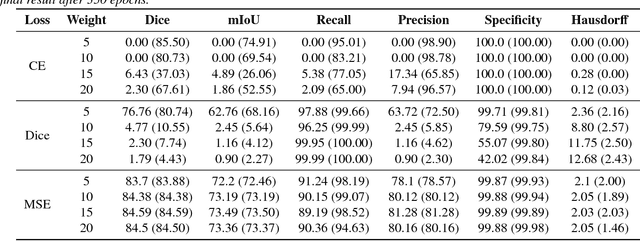
Recent deep learning methods for the medical imaging domain have reached state-of-the-art results and even surpassed human judgment in several tasks. Those models, however, when trained to reduce the empirical risk on a single domain, fail to generalize when applied on other domains, a very common scenario on medical imaging due to the variability of images and anatomical structures, even across the same imaging modality. In this work, we extend the method of unsupervised domain adaptation using self-ensembling for the semantic segmentation task and explore multiple facets of the method on a realistic small data regime using a publicly available magnetic resonance (MRI) dataset. Through an extensive evaluation, we show that self-ensembling can indeed improve the generalization of the models even when using a small amount of unlabelled data.
Deep semi-supervised segmentation with weight-averaged consistency targets
Jul 16, 2018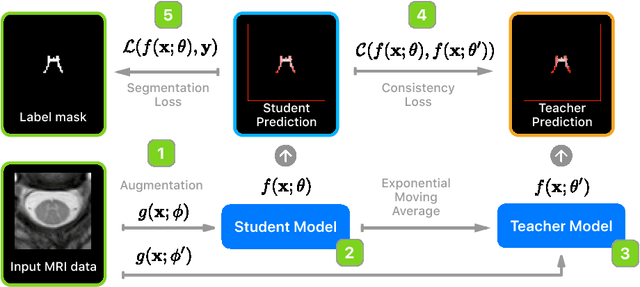
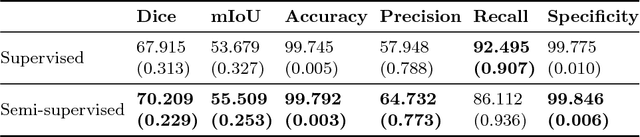
Recently proposed techniques for semi-supervised learning such as Temporal Ensembling and Mean Teacher have achieved state-of-the-art results in many important classification benchmarks. In this work, we expand the Mean Teacher approach to segmentation tasks and show that it can bring important improvements in a realistic small data regime using a publicly available multi-center dataset from the Magnetic Resonance Imaging (MRI) domain. We also devise a method to solve the problems that arise when using traditional data augmentation strategies for segmentation tasks on our new training scheme.
Evaluation of sentence embeddings in downstream and linguistic probing tasks
Jun 16, 2018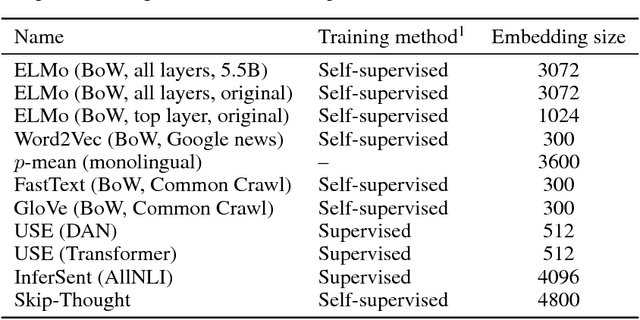
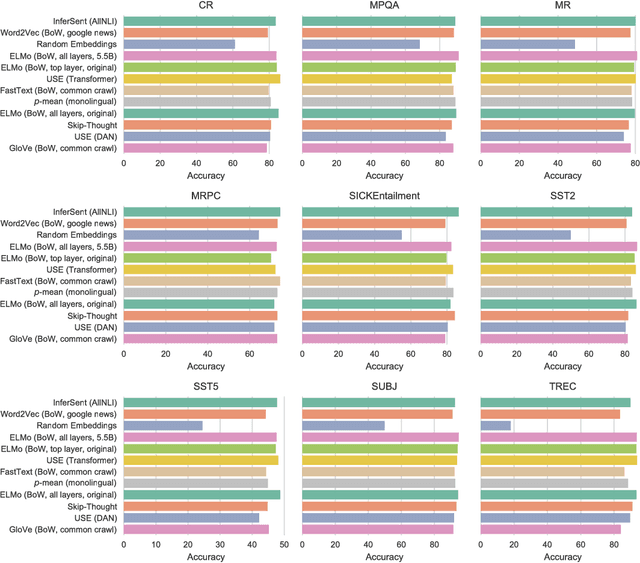
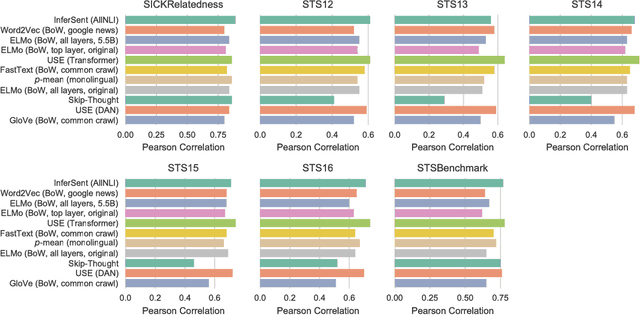
Despite the fast developmental pace of new sentence embedding methods, it is still challenging to find comprehensive evaluations of these different techniques. In the past years, we saw significant improvements in the field of sentence embeddings and especially towards the development of universal sentence encoders that could provide inductive transfer to a wide variety of downstream tasks. In this work, we perform a comprehensive evaluation of recent methods using a wide variety of downstream and linguistic feature probing tasks. We show that a simple approach using bag-of-words with a recently introduced language model for deep context-dependent word embeddings proved to yield better results in many tasks when compared to sentence encoders trained on entailment datasets. We also show, however, that we are still far away from a universal encoder that can perform consistently across several downstream tasks.
Towards ECDSA key derivation from deep embeddings for novel Blockchain applications
Nov 11, 2017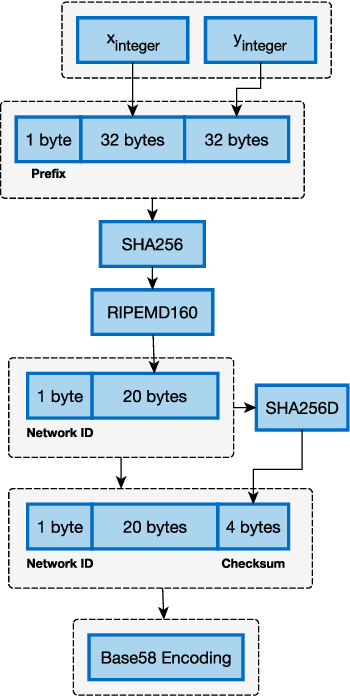
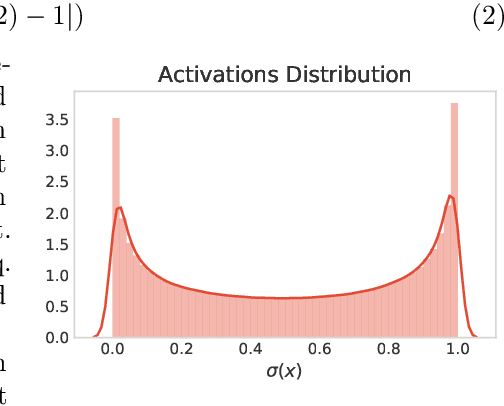
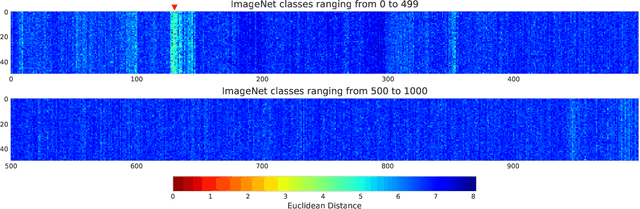
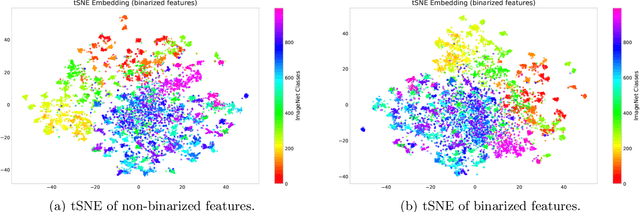
In this work, we propose a straightforward method to derive Elliptic Curve Digital Signature Algorithm (ECDSA) key pairs from embeddings created using Deep Learning and Metric Learning approaches. We also show that these keys allows the derivation of cryptocurrencies (such as Bitcoin) addresses that can be used to transfer and receive funds, allowing novel Blockchain-based applications that can be used to transfer funds or data directly to domains such as image, text, sound or any other domain where Deep Learning can extract high-quality embeddings; providing thus a novel integration between the properties of the Blockchain-based technologies such as trust minimization and decentralization together with the high-quality learned representations from Deep Learning techniques.