 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Time Debiasing Concepts in Diffusion Models
Aug 19, 2025We propose DeCoDi, a debiasing procedure for text-to-image diffusion-based models that changes the inference procedure, does not significantly change image quality, has negligible compute overhead, and can be applied in any diffusion-based image generation model. DeCoDi changes the diffusion process to avoid latent dimension regions of biased concepts. While most deep learning debiasing methods require complex or compute-intensive interventions, our method is designed to change only the inference procedure. Therefore, it is more accessible to a wide range of practitioners. We show the effectiveness of the method by debiasing for gender, ethnicity, and age for the concepts of nurse, firefighter, and CEO. Two distinct human evaluators manually inspect 1,200 generated images. Their evaluation results provide evidence that our method is effective in mitigating biases based on gender, ethnicity, and age. We also show that an automatic bias evaluation performed by the GPT4o is not significantly statistically distinct from a human evaluation. Our evaluation shows promising results, with reliable levels of agreement between evaluators and more coverage of protected attributes. Our method has the potential to significantly improve the diversity of images it generates by diffusion-based text-to-image generative models.
Bayesian Attention Mechanism: A Probabilistic Framework for Positional Encoding and Context Length Extrapolation
May 28, 2025Transformer-based language models rely on positional encoding (PE) to handle token order and support context length extrapolation. However, existing PE methods lack theoretical clarity and rely on limited evaluation metrics to substantiate their extrapolation claims. We propose the Bayesian Attention Mechanism (BAM), a theoretical framework that formulates positional encoding as a prior within a probabilistic model. BAM unifies existing methods (e.g., NoPE and ALiBi) and motivates a new Generalized Gaussian positional prior that substantially improves long-context generalization. Empirically, BAM enables accurate information retrieval at $500\times$ the training context length, outperforming previous state-of-the-art context length generalization in long context retrieval accuracy while maintaining comparable perplexity and introducing minimal additional parameters.
Self-Supervised Adversarial Imitation Learning
Apr 21, 2023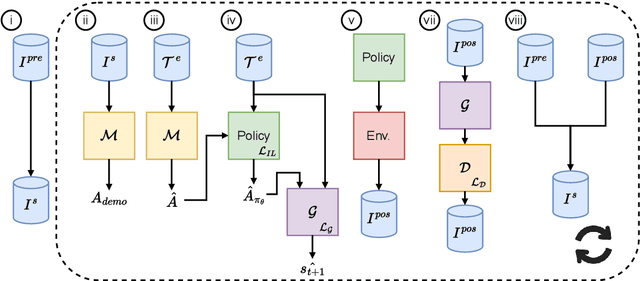
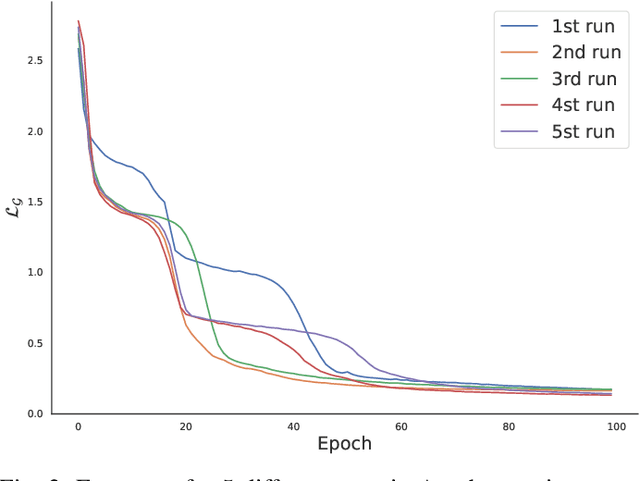
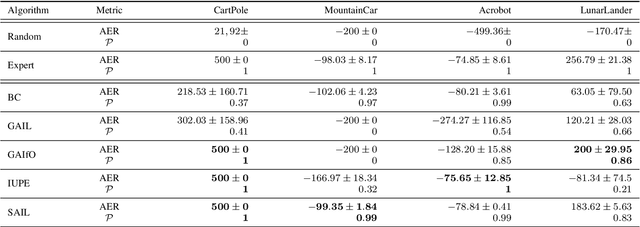
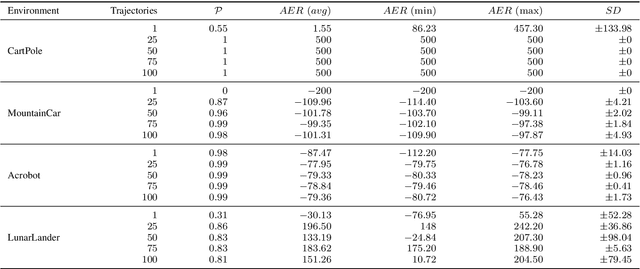
Behavioural cloning is an imitation learning technique that teaches an agent how to behave via expert demonstrations. Recent approaches use self-supervision of fully-observable unlabelled snapshots of the states to decode state pairs into actions. However, the iterative learning scheme employed by these techniques is prone to get trapped into bad local minima. Previous work uses goal-aware strategies to solve this issue. However, this requires manual intervention to verify whether an agent has reached its goal. We address this limitation by incorporating a discriminator into the original framework, offering two key advantages and directly solving a learning problem previous work had. First, it disposes of the manual intervention requirement. Second, it helps in learning by guiding function approximation based on the state transition of the expert's trajectories. Third, the discriminator solves a learning issue commonly present in the policy model, which is to sometimes perform a `no action' within the environment until the agent finally halts.
Debiasing Methods for Fairer Neural Models in Vision and Language Research: A Survey
Nov 10, 2022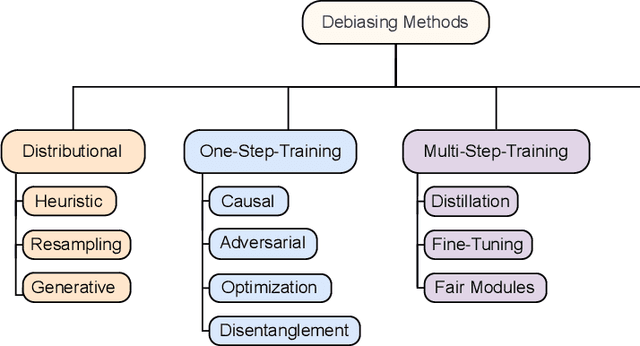
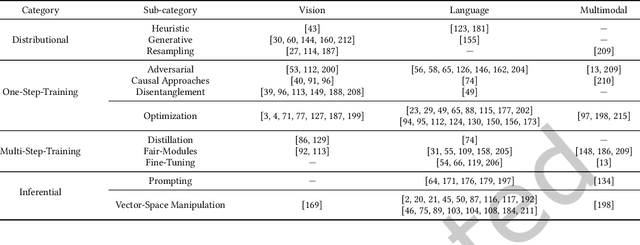

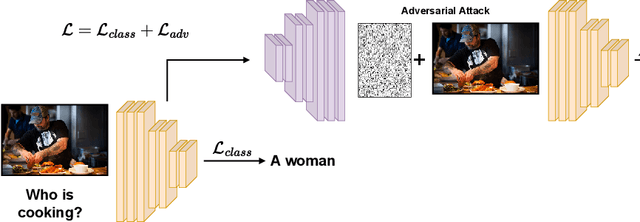
Despite being responsible for state-of-the-art results in several computer vision and natural language processing tasks, neural networks have faced harsh criticism due to some of their current shortcomings. One of them is that neural networks are correlation machines prone to model biases within the data instead of focusing on actual useful causal relationships. This problem is particularly serious in application domains affected by aspects such as race, gender, and age. To prevent models from incurring on unfair decision-making, the AI community has concentrated efforts in correcting algorithmic biases, giving rise to the research area now widely known as fairness in AI. In this survey paper, we provide an in-depth overview of the main debiasing methods for fairness-aware neural networks in the context of vision and language research. We propose a novel taxonomy to better organize the literature on debiasing methods for fairness, and we discuss the current challenges, trends, and important future work directions for the interested researcher and practitioner.
An Extensive Experimental Evaluation of Automated Machine Learning Methods for Recommending Classification Algorithms (Extended Version)
Sep 16, 2020

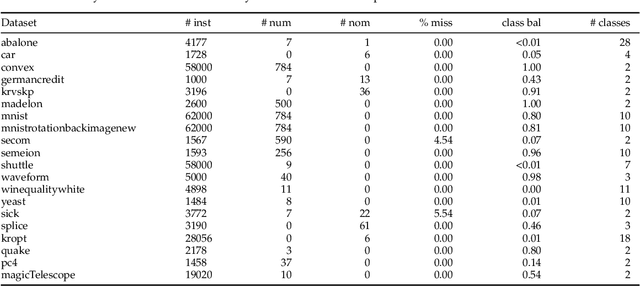
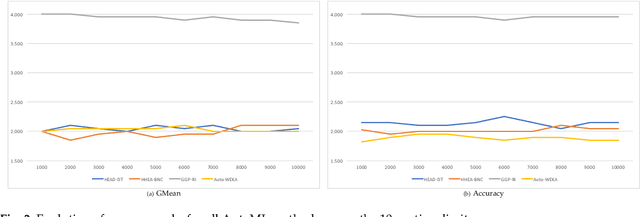
This paper presents an experimental comparison among four Automated Machine Learning (AutoML) methods for recommending the best classification algorithm for a given input dataset. Three of these methods are based on Evolutionary Algorithms (EAs), and the other is Auto-WEKA, a well-known AutoML method based on the Combined Algorithm Selection and Hyper-parameter optimisation (CASH) approach. The EA-based methods build classification algorithms from a single machine learning paradigm: either decision-tree induction, rule induction, or Bayesian network classification. Auto-WEKA combines algorithm selection and hyper-parameter optimisation to recommend classification algorithms from multiple paradigms. We performed controlled experiments where these four AutoML methods were given the same runtime limit for different values of this limit. In general, the difference in predictive accuracy of the three best AutoML methods was not statistically significant. However, the EA evolving decision-tree induction algorithms has the advantage of producing algorithms that generate interpretable classification models and that are more scalable to large datasets, by comparison with many algorithms from other learning paradigms that can be recommended by Auto-WEKA. We also observed that Auto-WEKA has shown meta-overfitting, a form of overfitting at the meta-learning level, rather than at the base-learning level.
Imitating Unknown Policies via Exploration
Aug 13, 2020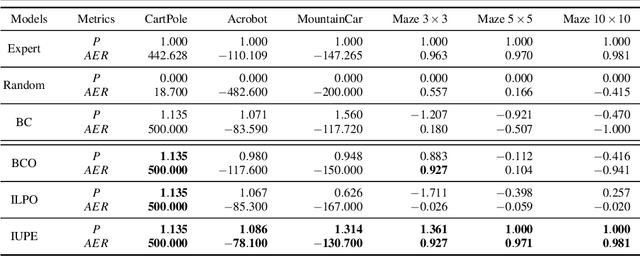
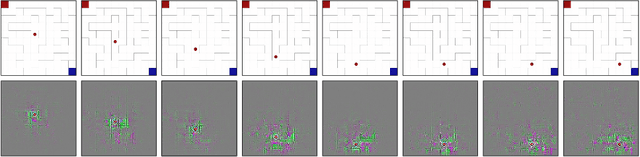

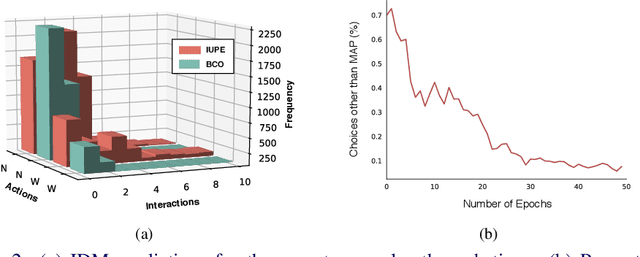
Behavioral cloning is an imitation learning technique that teaches an agent how to behave through expert demonstrations. Recent approaches use self-supervision of fully-observable unlabeled snapshots of the states to decode state-pairs into actions. However, the iterative learning scheme from these techniques are prone to getting stuck into bad local minima. We address these limitations incorporating a two-phase model into the original framework, which learns from unlabeled observations via exploration, substantially improving traditional behavioral cloning by exploiting (i) a sampling mechanism to prevent bad local minima, (ii) a sampling mechanism to improve exploration, and (iii) self-attention modules to capture global features. The resulting technique outperforms the previous state-of-the-art in four different environments by a large margin.
HAPRec: Hybrid Activity and Plan Recognizer
Apr 28, 2020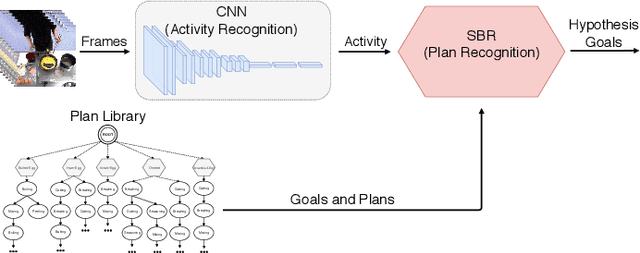
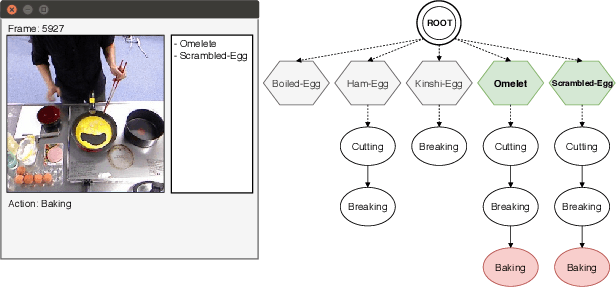
Computer-based assistants have recently attracted much interest due to its applicability to ambient assisted living. Such assistants have to detect and recognize the high-level activities and goals performed by the assisted human beings. In this work, we demonstrate activity recognition in an indoor environment in order to identify the goal towards which the subject of the video is pursuing. Our hybrid approach combines an action recognition module and a goal recognition algorithm to identify the ultimate goal of the subject in the video.
Component Analysis for Visual Question Answering Architectures
Feb 12, 2020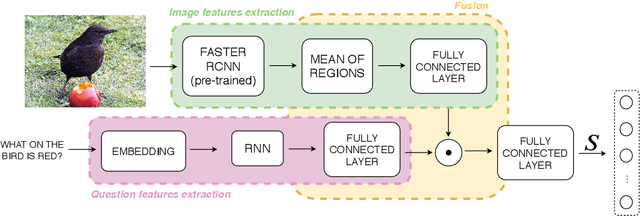
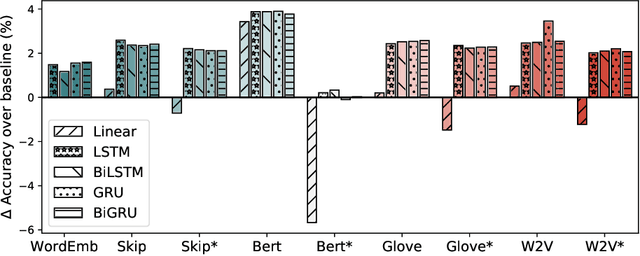
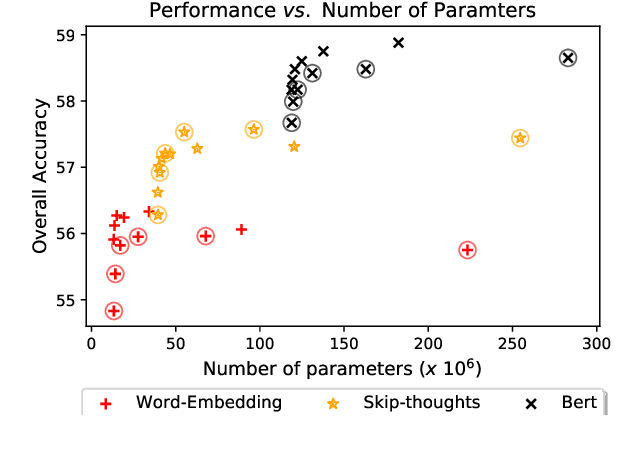
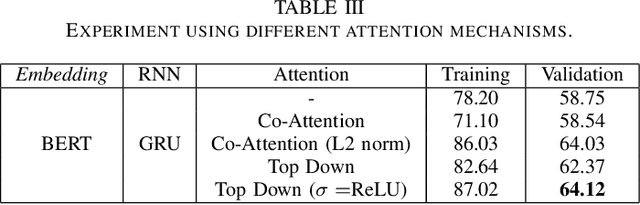
Recent research advances in Computer Vision and Natural Language Processing have introduced novel tasks that are paving the way for solving AI-complete problems. One of those tasks is called Visual Question Answering (VQA). A VQA system must take an image and a free-form, open-ended natural language question about the image, and produce a natural language answer as the output. Such a task has drawn great attention from the scientific community, which generated a plethora of approaches that aim to improve the VQA predictive accuracy. Most of them comprise three major components: (i) independent representation learning of images and questions; (ii) feature fusion so the model can use information from both sources to answer visual questions; and (iii) the generation of the correct answer in natural language. With so many approaches being recently introduced, it became unclear the real contribution of each component for the ultimate performance of the model. The main goal of this paper is to provide a comprehensive analysis regarding the impact of each component in VQA models. Our extensive set of experiments cover both visual and textual elements, as well as the combination of these representations in form of fusion and attention mechanisms. Our major contribution is to identify core components for training VQA models so as to maximize their predictive performance.
Can we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification
Sep 03, 2019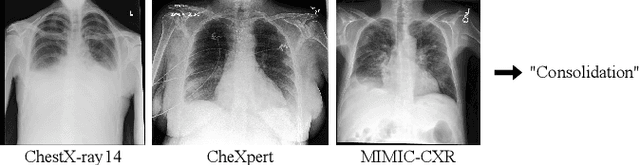

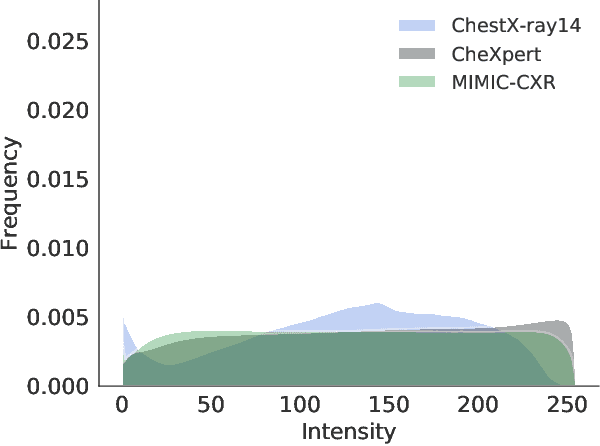
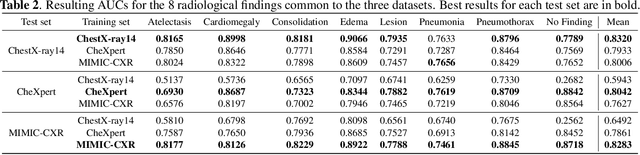
While deep learning models become more widespread, their ability to handle unseen data and generalize for any scenario is yet to be challenged. In medical imaging, there is a high heterogeneity of distributions among images based on the equipment that generate them and their parametrization. This heterogeneity triggers a common issue in machine learning called domain shift, which represents the difference between the training data distribution and the distribution of where a model is employed. A high domain shift tends to implicate in a poor performance from models. In this work, we evaluate the extent of domain shift on three of the largest datasets of chest radiographs. We show how training and testing with different datasets (e.g. training in ChestX-ray14 and testing in CheXpert) drastically affects model performance, posing a big question over the reliability of deep learning models.
Classifying Norm Conflicts using Learned Semantic Representations
May 13, 2019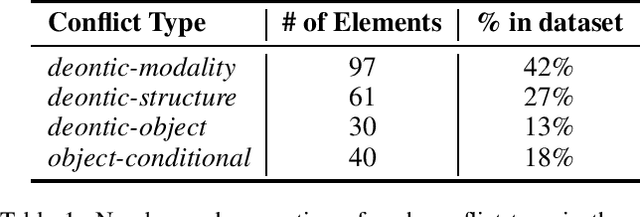
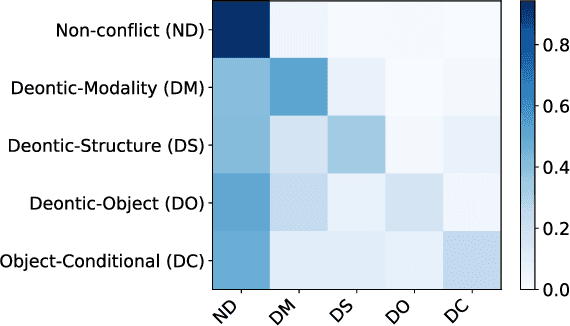
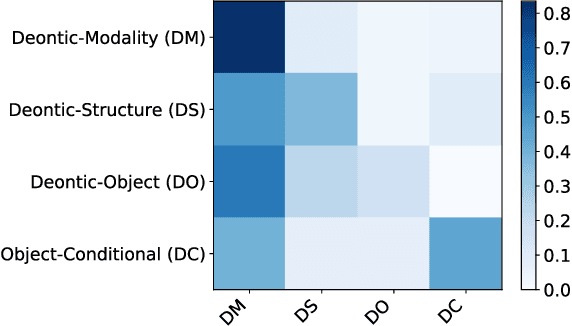
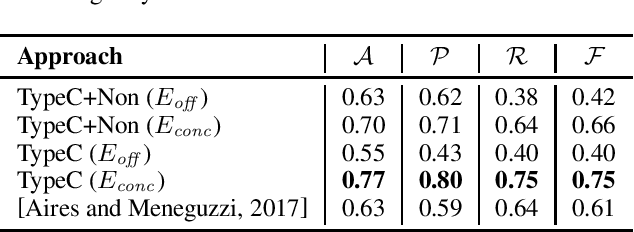
While most social norms are informal, they are often formalized by companies in contracts to regulate trades of goods and services. When poorly written, contracts may contain normative conflicts resulting from opposing deontic meanings or contradict specifications. As contracts tend to be long and contain many norms, manually identifying such conflicts requires human-effort, which is time-consuming and error-prone. Automating such task benefits contract makers increasing productivity and making conflict identification more reliable. To address this problem, we introduce an approach to detect and classify norm conflicts in contracts by converting them into latent representations that preserve both syntactic and semantic information and training a model to classify norm conflicts in four conflict types. Our results reach the new state of the art when compared to a previous approach.