 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstract Task Representations
Jan 28, 2021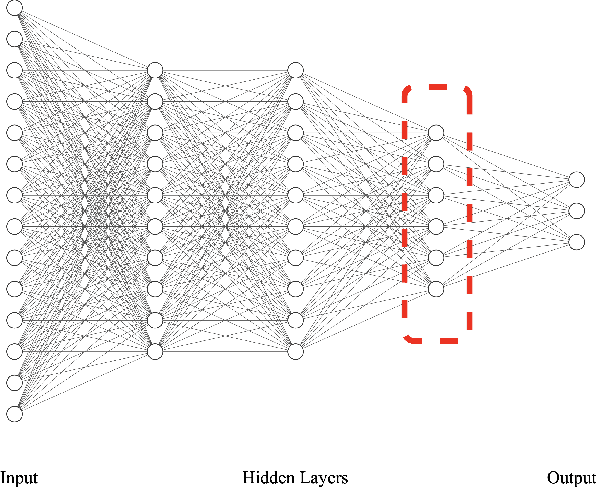
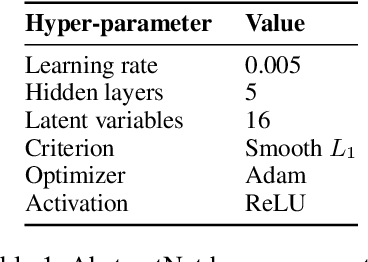
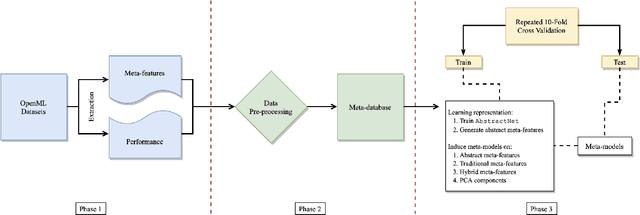

A proper form of data characterization can guide the process of learning-algorithm selection and model-performance estimation. The field of meta-learning has provided a rich body of work describing effective forms of data characterization using different families of meta-features (statistical, model-based, information-theoretic, topological, etc.). In this paper, we start with the abundant set of existing meta-features and propose a method to induce new abstract meta-features as latent variables in a deep neural network. We discuss the pitfalls of using traditional meta-features directly and argue for the importance of learning high-level task properties. We demonstrate our methodology using a deep neural network as a feature extractor. We demonstrate that 1) induced meta-models mapping abstract meta-features to generalization performance outperform other methods by ~18% on average, and 2) abstract meta-features attain high feature-relevance scores.
An Extensive Experimental Evaluation of Automated Machine Learning Methods for Recommending Classification Algorithms (Extended Version)
Sep 16, 2020

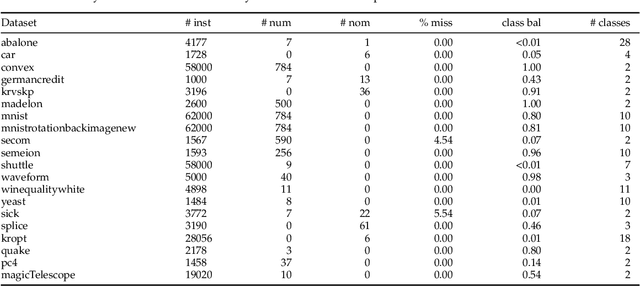
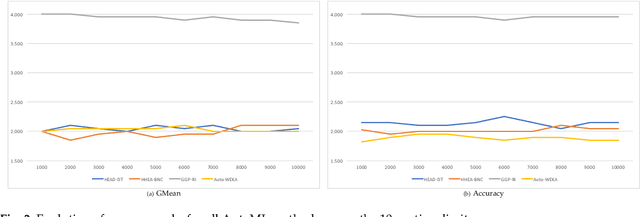
This paper presents an experimental comparison among four Automated Machine Learning (AutoML) methods for recommending the best classification algorithm for a given input dataset. Three of these methods are based on Evolutionary Algorithms (EAs), and the other is Auto-WEKA, a well-known AutoML method based on the Combined Algorithm Selection and Hyper-parameter optimisation (CASH) approach. The EA-based methods build classification algorithms from a single machine learning paradigm: either decision-tree induction, rule induction, or Bayesian network classification. Auto-WEKA combines algorithm selection and hyper-parameter optimisation to recommend classification algorithms from multiple paradigms. We performed controlled experiments where these four AutoML methods were given the same runtime limit for different values of this limit. In general, the difference in predictive accuracy of the three best AutoML methods was not statistically significant. However, the EA evolving decision-tree induction algorithms has the advantage of producing algorithms that generate interpretable classification models and that are more scalable to large datasets, by comparison with many algorithms from other learning paradigms that can be recommended by Auto-WEKA. We also observed that Auto-WEKA has shown meta-overfitting, a form of overfitting at the meta-learning level, rather than at the base-learning level.
OpenML Benchmarking Suites and the OpenML100
Aug 11, 2017
We advocate the use of curated, comprehensive benchmark suites of machine learning datasets, backed by standardized OpenML-based interfaces and complementary software toolkits written in Python, Java and R. Major distinguishing features of OpenML benchmark suites are (a) ease of use through standardized data formats, APIs, and existing client libraries; (b) machine-readable meta-information regarding the contents of the suite; and (c) online sharing of results, enabling large scale comparisons. As a first such suite, we propose the OpenML100, a machine learning benchmark suite of 100~classification datasets carefully curated from the thousands of datasets available on OpenML.org.