 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstract Task Representations
Jan 28, 2021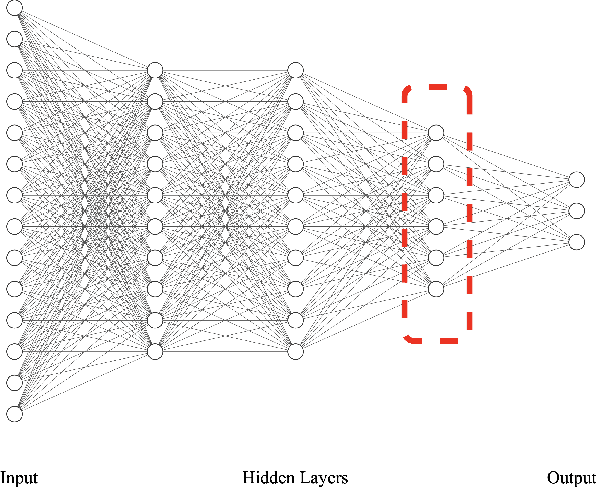
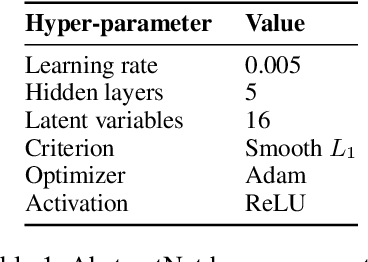
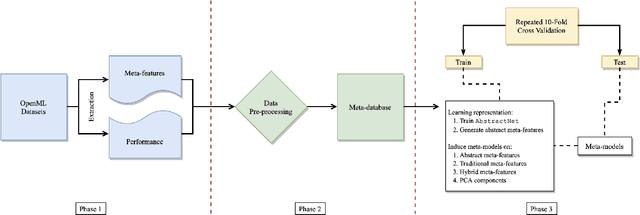

A proper form of data characterization can guide the process of learning-algorithm selection and model-performance estimation. The field of meta-learning has provided a rich body of work describing effective forms of data characterization using different families of meta-features (statistical, model-based, information-theoretic, topological, etc.). In this paper, we start with the abundant set of existing meta-features and propose a method to induce new abstract meta-features as latent variables in a deep neural network. We discuss the pitfalls of using traditional meta-features directly and argue for the importance of learning high-level task properties. We demonstrate our methodology using a deep neural network as a feature extractor. We demonstrate that 1) induced meta-models mapping abstract meta-features to generalization performance outperform other methods by ~18% on average, and 2) abstract meta-features attain high feature-relevance scores.
A General Approach to Domain Adaptation with Applications in Astronomy
Dec 20, 2018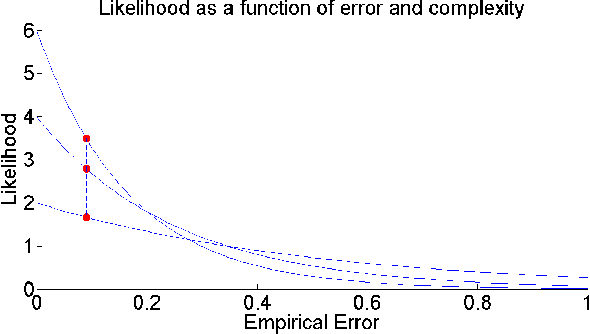
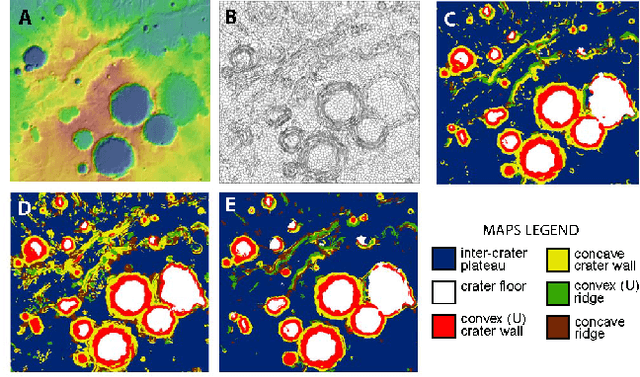
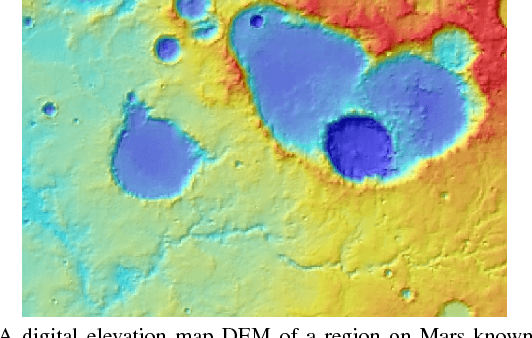
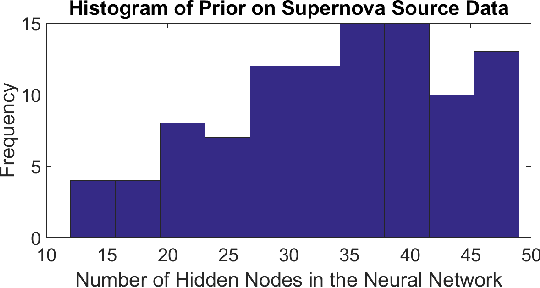
The ability to build a model on a source task and subsequently adapt such model on a new target task is a pervasive need in many astronomical applications. The problem is generally known as transfer learning in machine learning, where domain adaptation is a popular scenario. An example is to build a predictive model on spectroscopic data to identify Supernovae IA, while subsequently trying to adapt such model on photometric data. In this paper we propose a new general approach to domain adaptation that does not rely on the proximity of source and target distributions. Instead we simply assume a strong similarity in model complexity across domains, and use active learning to mitigate the dependency on source examples. Our work leads to a new formulation for the likelihood as a function of empirical error using a theoretical learning bound; the result is a novel mapping from generalization error to a likelihood estimation. Results using two real astronomical problems, Supernova Ia classification and identification of Mars landforms, show two main advantages with our approach: increased accuracy performance and substantial savings in computational cost.