 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning Loss Functions of Parametric Partial Differential Equations Using Physics-Informed Neural Networks
Nov 29, 2024



This paper proposes a new way to learn Physics-Informed Neural Network loss functions using Generalized Additive Models. We apply our method by meta-learning parametric partial differential equations, PDEs, on Burger's and 2D Heat Equations. The goal is to learn a new loss function for each parametric PDE using meta-learning. The derived loss function replaces the traditional data loss, allowing us to learn each parametric PDE more efficiently, improving the meta-learner's performance and convergence.
Physics-informed neural networks in the recreation of hydrodynamic simulations from dark matter
Mar 24, 2023Physics-informed neural networks have emerged as a coherent framework for building predictive models that combine statistical patterns with domain knowledge. The underlying notion is to enrich the optimization loss function with known relationships to constrain the space of possible solutions. Hydrodynamic simulations are a core constituent of modern cosmology, while the required computations are both expensive and time-consuming. At the same time, the comparatively fast simulation of dark matter requires fewer resources, which has led to the emergence of machine learning algorithms for baryon inpainting as an active area of research; here, recreating the scatter found in hydrodynamic simulations is an ongoing challenge. This paper presents the first application of physics-informed neural networks to baryon inpainting by combining advances in neural network architectures with physical constraints, injecting theory on baryon conversion efficiency into the model loss function. We also introduce a punitive prediction comparison based on the Kullback-Leibler divergence, which enforces scatter reproduction. By simultaneously extracting the complete set of baryonic properties for the Simba suite of cosmological simulations, our results demonstrate improved accuracy of baryonic predictions based on dark matter halo properties, successful recovery of the fundamental metallicity relation, and retrieve scatter that traces the target simulation's distribution.
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021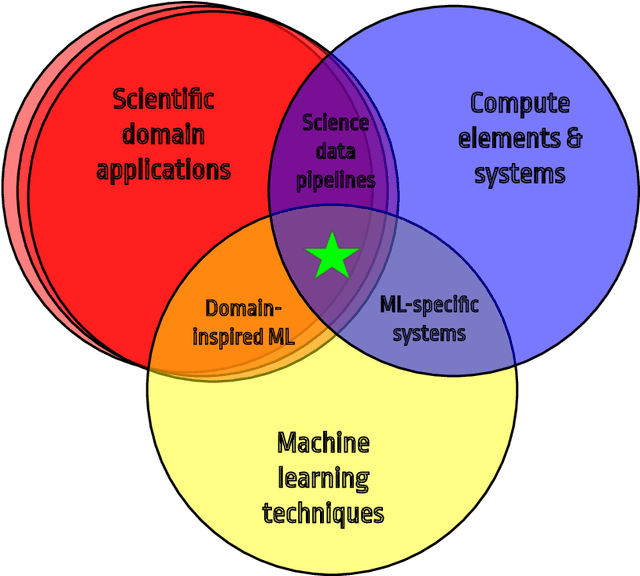
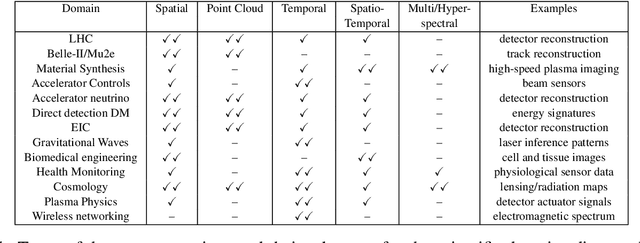
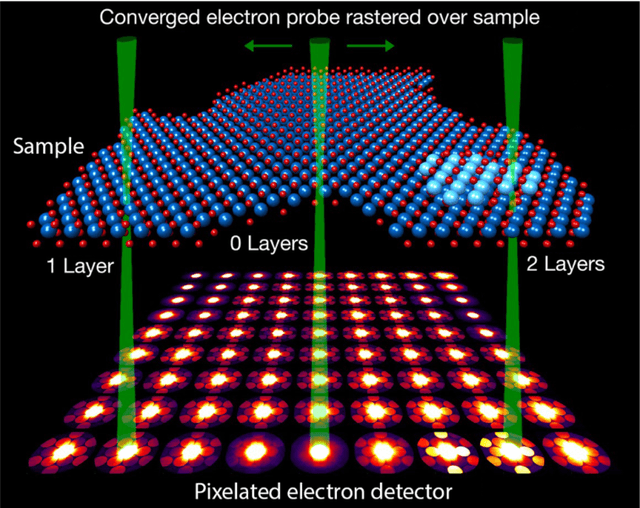
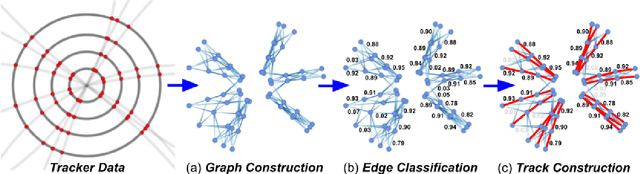
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Learning Abstract Task Representations
Jan 28, 2021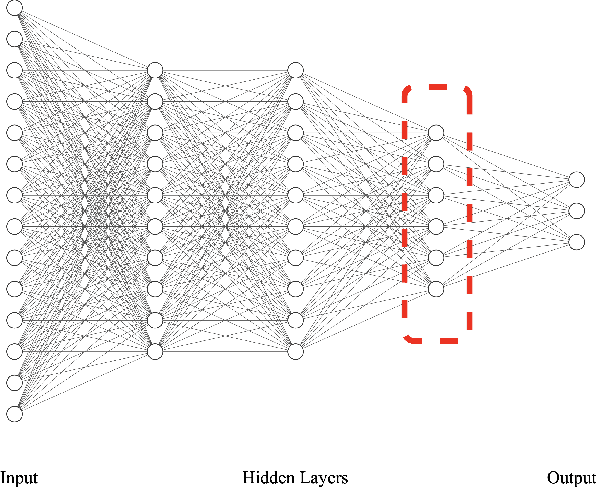
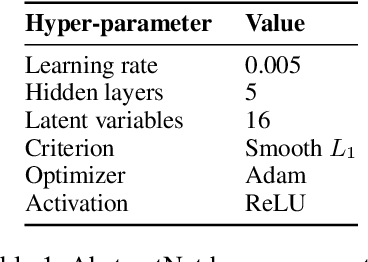
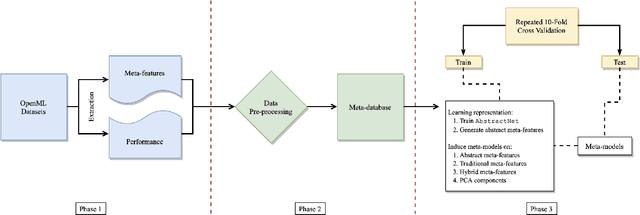

A proper form of data characterization can guide the process of learning-algorithm selection and model-performance estimation. The field of meta-learning has provided a rich body of work describing effective forms of data characterization using different families of meta-features (statistical, model-based, information-theoretic, topological, etc.). In this paper, we start with the abundant set of existing meta-features and propose a method to induce new abstract meta-features as latent variables in a deep neural network. We discuss the pitfalls of using traditional meta-features directly and argue for the importance of learning high-level task properties. We demonstrate our methodology using a deep neural network as a feature extractor. We demonstrate that 1) induced meta-models mapping abstract meta-features to generalization performance outperform other methods by ~18% on average, and 2) abstract meta-features attain high feature-relevance scores.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020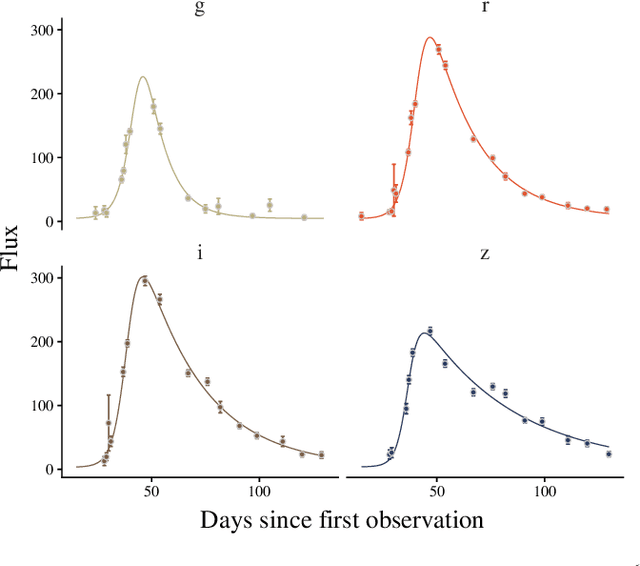
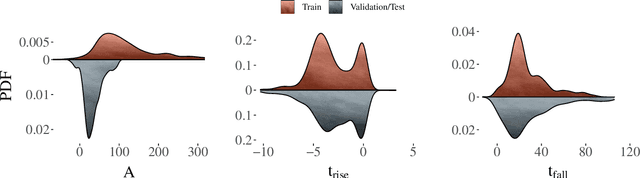
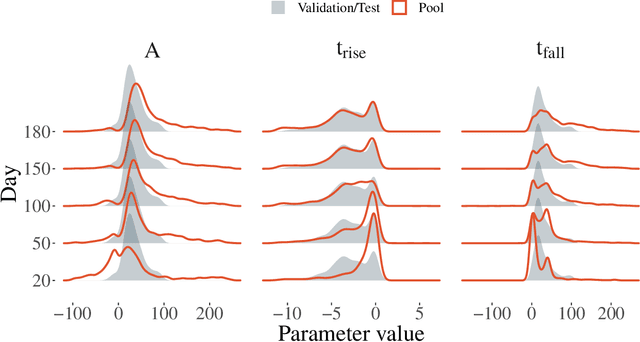
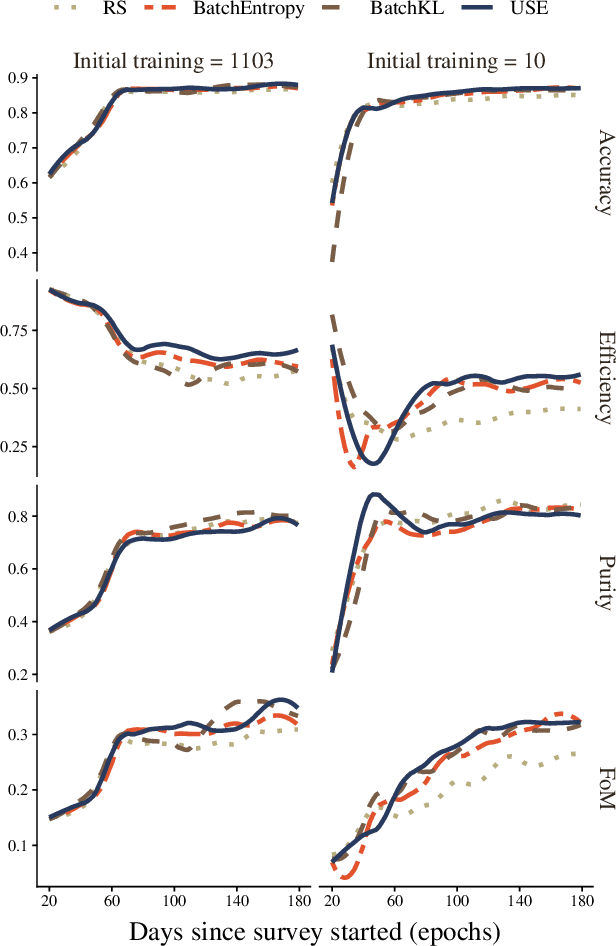
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
Algorithms and Statistical Models for Scientific Discovery in the Petabyte Era
Nov 05, 2019The field of astronomy has arrived at a turning point in terms of size and complexity of both datasets and scientific collaboration. Commensurately, algorithms and statistical models have begun to adapt --- e.g., via the onset of artificial intelligence --- which itself presents new challenges and opportunities for growth. This white paper aims to offer guidance and ideas for how we can evolve our technical and collaborative frameworks to promote efficient algorithmic development and take advantage of opportunities for scientific discovery in the petabyte era. We discuss challenges for discovery in large and complex data sets; challenges and requirements for the next stage of development of statistical methodologies and algorithmic tool sets; how we might change our paradigms of collaboration and education; and the ethical implications of scientists' contributions to widely applicable algorithms and computational modeling. We start with six distinct recommendations that are supported by the commentary following them. This white paper is related to a larger corpus of effort that has taken place within and around the Petabytes to Science Workshops (https://petabytestoscience.github.io/).
Transfer Learning in Astronomy: A New Machine-Learning Paradigm
Dec 20, 2018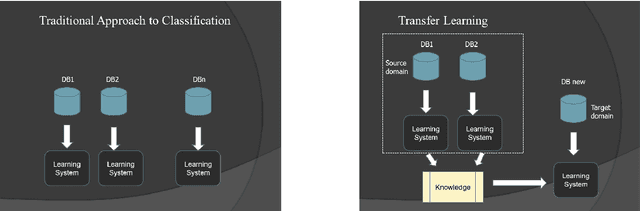
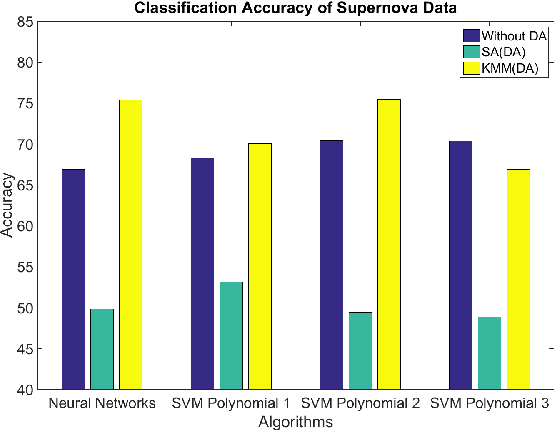
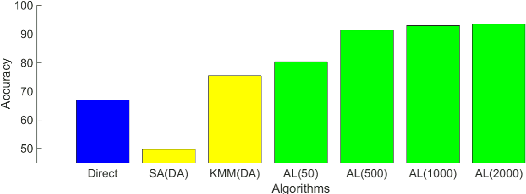
The widespread dissemination of machine learning tools in science, particularly in astronomy, has revealed the limitation of working with simple single-task scenarios in which any task in need of a predictive model is looked in isolation, and ignores the existence of other similar tasks. In contrast, a new generation of techniques is emerging where predictive models can take advantage of previous experience to leverage information from similar tasks. The new emerging area is referred to as transfer learning. In this paper, I briefly describe the motivation behind the use of transfer learning techniques, and explain how such techniques can be used to solve popular problems in astronomy. As an example, a prevalent problem in astronomy is to estimate the class of an object (e.g., Supernova Ia) using a generation of photometric light-curve datasets where data abounds, but class labels are scarce; such analysis can benefit from spectroscopic data where class labels are known with high confidence, but the data sample is small. Transfer learning provides a robust and practical solution to leverage information from one domain to improve the accuracy of a model built on a different domain. In the example above, transfer learning would look to overcome the difficulty in the compatibility of models between spectroscopic data and photometric data, since data properties such as size, class priors, and underlying distributions, are all expected to be significantly different.
A General Approach to Domain Adaptation with Applications in Astronomy
Dec 20, 2018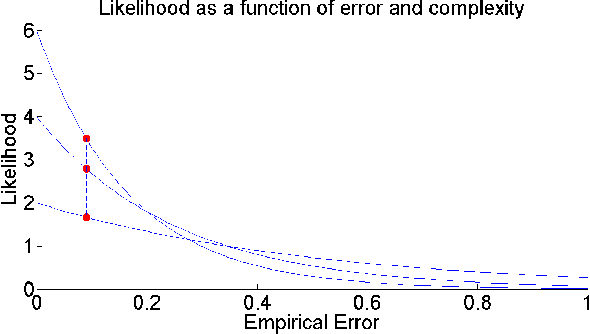
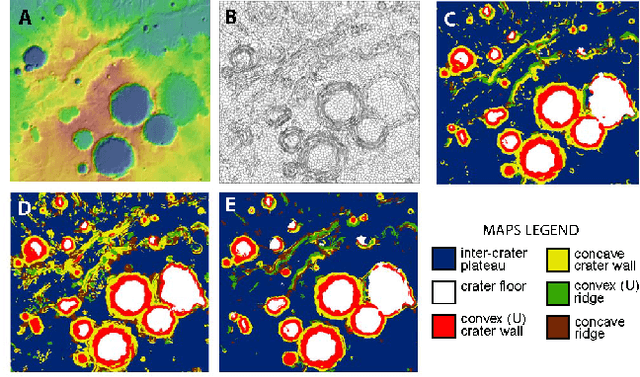
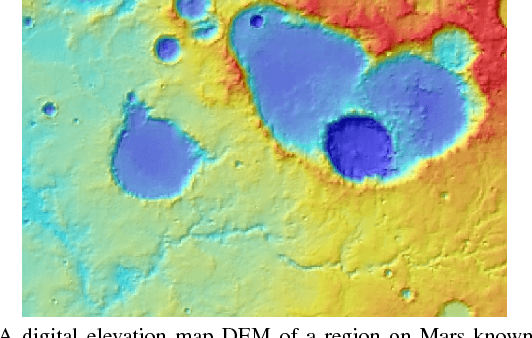
The ability to build a model on a source task and subsequently adapt such model on a new target task is a pervasive need in many astronomical applications. The problem is generally known as transfer learning in machine learning, where domain adaptation is a popular scenario. An example is to build a predictive model on spectroscopic data to identify Supernovae IA, while subsequently trying to adapt such model on photometric data. In this paper we propose a new general approach to domain adaptation that does not rely on the proximity of source and target distributions. Instead we simply assume a strong similarity in model complexity across domains, and use active learning to mitigate the dependency on source examples. Our work leads to a new formulation for the likelihood as a function of empirical error using a theoretical learning bound; the result is a novel mapping from generalization error to a likelihood estimation. Results using two real astronomical problems, Supernova Ia classification and identification of Mars landforms, show two main advantages with our approach: increased accuracy performance and substantial savings in computational cost.
Conceptual Domain Adaptation Using Deep Learning
Aug 16, 2018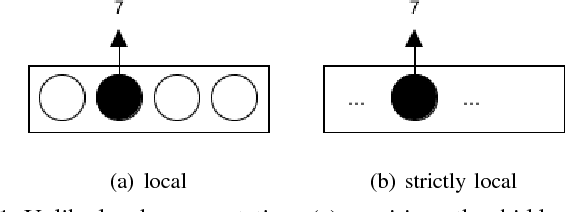

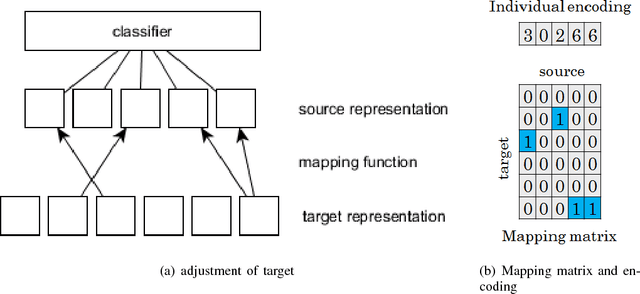
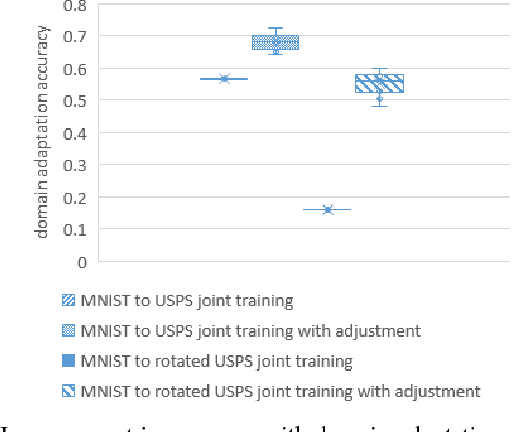
Deep learning has recently been shown to be instrumental in the problem of domain adaptation, where the goal is to learn a model on a target domain using a similar --but not identical-- source domain. The rationale for coupling both techniques is the possibility of extracting common concepts across domains. Considering (strictly) local representations, traditional deep learning assumes common concepts must be captured in the same hidden units. We contend that jointly training a model with source and target data using a single deep network is prone to failure when there is inherently lower-level representational discrepancy between the two domains; such discrepancy leads to a misalignment of corresponding concepts in separate hidden units. We introduce a search framework to correctly align high-level representations when training deep networks; such framework leads to the notion of conceptual --as opposed to representational-- domain adaptation.