 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Amortization for Bayesian Optimal Experimental Design
Oct 07, 2022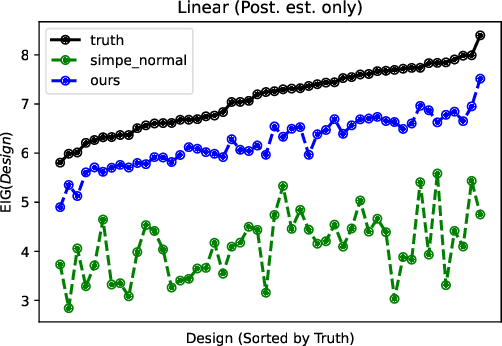
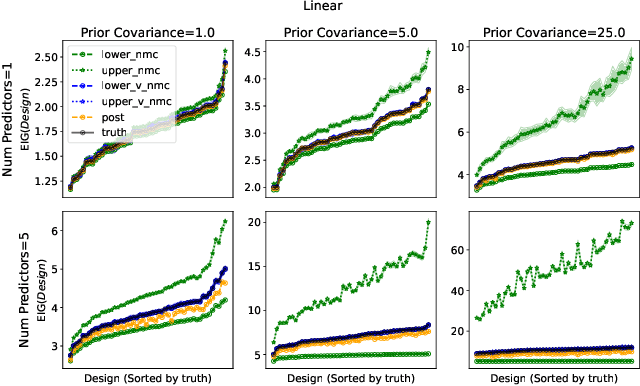
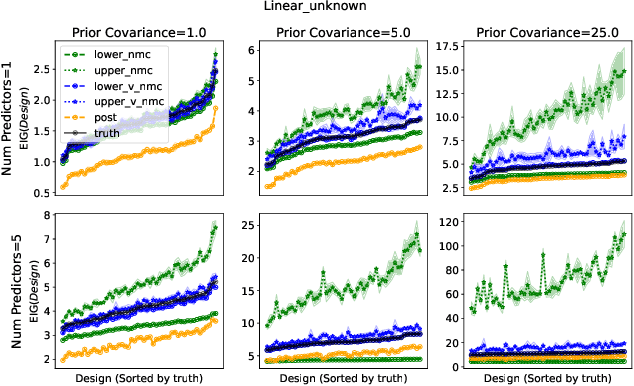
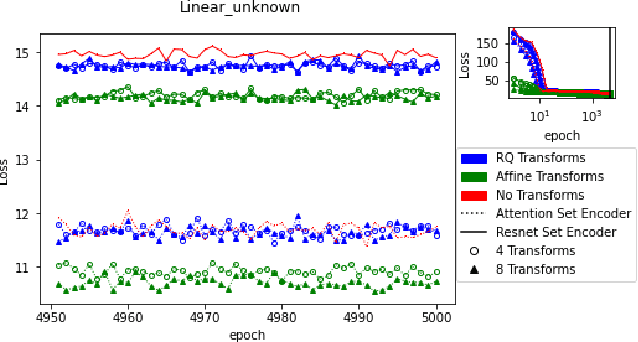
Bayesian optimal experimental design is a sub-field of statistics focused on developing methods to make efficient use of experimental resources. Any potential design is evaluated in terms of a utility function, such as the (theoretically well-justified) expected information gain (EIG); unfortunately however, under most circumstances the EIG is intractable to evaluate. In this work we build off of successful variational approaches, which optimize a parameterized variational model with respect to bounds on the EIG. Past work focused on learning a new variational model from scratch for each new design considered. Here we present a novel neural architecture that allows experimenters to optimize a single variational model that can estimate the EIG for potentially infinitely many designs. To further improve computational efficiency, we also propose to train the variational model on a significantly cheaper-to-evaluate lower bound, and show empirically that the resulting model provides an excellent guide for more accurate, but expensive to evaluate bounds on the EIG. We demonstrate the effectiveness of our technique on generalized linear models, a class of statistical models that is widely used in the analysis of controlled experiments. Experiments show that our method is able to greatly improve accuracy over existing approximation strategies, and achieve these results with far better sample efficiency.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020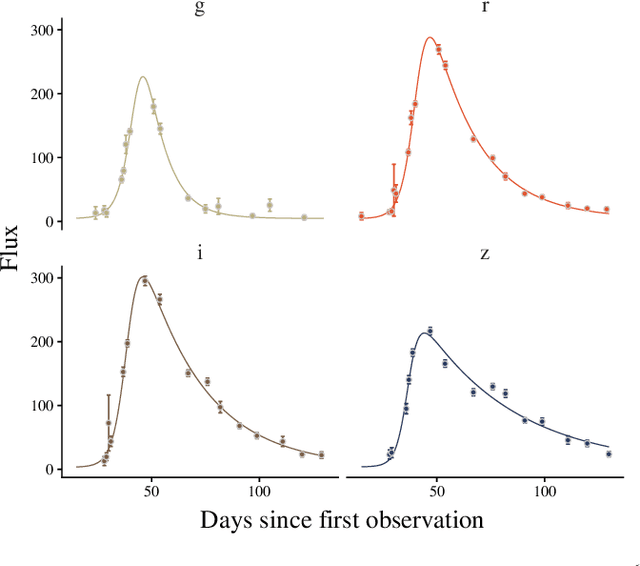
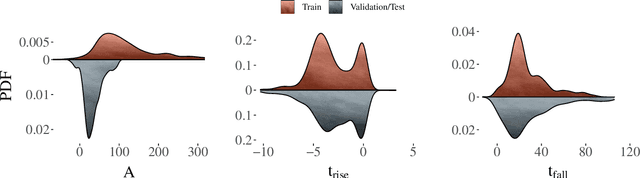
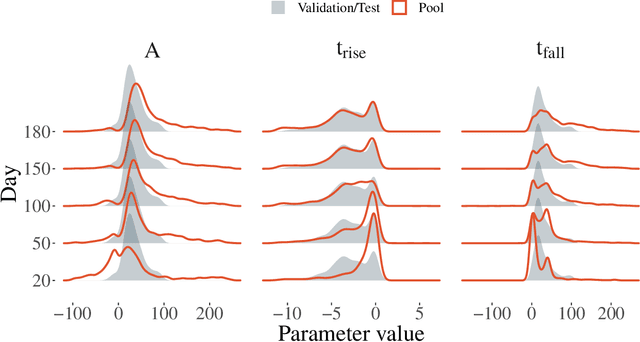
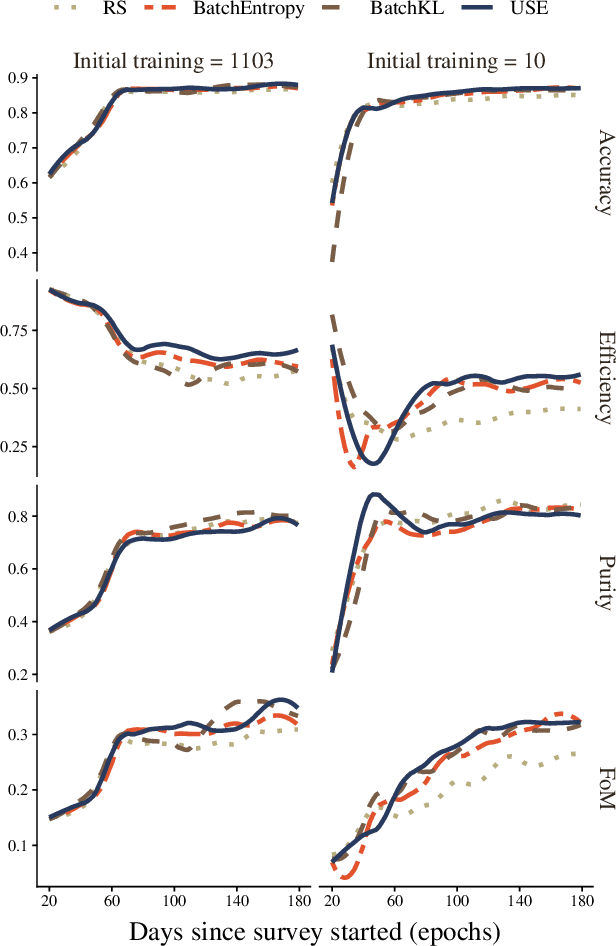
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.