 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat ZTF Saw Where Rubin Looked: Anomaly Hunting in DR23
Jul 08, 2025We present results from the SNAD VIII Workshop, during which we conducted the first systematic anomaly search in the ZTF fields also observed by LSSTComCam during Rubin Scientific Pipeline commissioning. Using the PineForest active anomaly detection algorithm, we analysed four selected fields (two galactic and two extragalactic) and visually inspected 400 candidates. As a result, we discovered six previously uncatalogued variable stars, including RS~CVn, BY Draconis, ellipsoidal, and solar-type variables, and refined classifications and periods for six known objects. These results demonstrate the effectiveness of the SNAD anomaly detection pipeline and provide a preview of the discovery potential in the upcoming LSST data.
From Galaxy Zoo DECaLS to BASS/MzLS: detailed galaxy morphology classification with unsupervised domain adaption
Dec 20, 2024



The DESI Legacy Imaging Surveys (DESI-LIS) comprise three distinct surveys: the Dark Energy Camera Legacy Survey (DECaLS), the Beijing-Arizona Sky Survey (BASS), and the Mayall z-band Legacy Survey (MzLS). The citizen science project Galaxy Zoo DECaLS 5 (GZD-5) has provided extensive and detailed morphology labels for a sample of 253,287 galaxies within the DECaLS survey. This dataset has been foundational for numerous deep learning-based galaxy morphology classification studies. However, due to differences in signal-to-noise ratios and resolutions between the DECaLS images and those from BASS and MzLS (collectively referred to as BMz), a neural network trained on DECaLS images cannot be directly applied to BMz images due to distributional mismatch. In this study, we explore an unsupervised domain adaptation (UDA) method that fine-tunes a source domain model trained on DECaLS images with GZD-5 labels to BMz images, aiming to reduce bias in galaxy morphology classification within the BMz survey. Our source domain model, used as a starting point for UDA, achieves performance on the DECaLS galaxies' validation set comparable to the results of related works. For BMz galaxies, the fine-tuned target domain model significantly improves performance compared to the direct application of the source domain model, reaching a level comparable to that of the source domain. We also release a catalogue of detailed morphology classifications for 248,088 galaxies within the BMz survey, accompanied by usage recommendations.
Exploring the Universe with SNAD: Anomaly Detection in Astronomy
Oct 24, 2024SNAD is an international project with a primary focus on detecting astronomical anomalies within large-scale surveys, using active learning and other machine learning algorithms. The work carried out by SNAD not only contributes to the discovery and classification of various astronomical phenomena but also enhances our understanding and implementation of machine learning techniques within the field of astrophysics. This paper provides a review of the SNAD project and summarizes the advancements and achievements made by the team over several years.
* 14 pages, 4 figures
Multi-View Symbolic Regression
Feb 16, 2024



Symbolic regression (SR) searches for analytical expressions representing the relationship between a set of explanatory and response variables. Current SR methods assume a single dataset extracted from a single experiment. Nevertheless, frequently, the researcher is confronted with multiple sets of results obtained from experiments conducted with different setups. Traditional SR methods may fail to find the underlying expression since the parameters of each experiment can be different. In this work we present Multi-View Symbolic Regression (MvSR), which takes into account multiple datasets simultaneously, mimicking experimental environments, and outputs a general parametric solution. This approach fits the evaluated expression to each independent dataset and returns a parametric family of functions f(x; \theta) simultaneously capable of accurately fitting all datasets. We demonstrate the effectiveness of MvSR using data generated from known expressions, as well as real-world data from astronomy, chemistry and economy, for which an a priori analytical expression is not available. Results show that MvSR obtains the correct expression more frequently and is robust to hyperparameters change. In real-world data, it is able to grasp the group behaviour, recovering known expressions from the literature as well as promising alternatives, thus enabling the use SR to a large range of experimental scenarios.
From Images to Features: Unbiased Morphology Classification via Variational Auto-Encoders and Domain Adaptation
Mar 15, 2023We present a novel approach for the dimensionality reduction of galaxy images by leveraging a combination of variational auto-encoders (VAE) and domain adaptation (DA). We demonstrate the effectiveness of this approach using a sample of low redshift galaxies with detailed morphological type labels from the Galaxy-Zoo DECaLS project. We show that 40-dimensional latent variables can effectively reproduce most morphological features in galaxy images. To further validate the effectiveness of our approach, we utilised a classical random forest (RF) classifier on the 40-dimensional latent variables to make detailed morphology feature classifications. This approach performs similarly to a direct neural network application on galaxy images. We further enhance our model by tuning the VAE network via DA using galaxies in the overlapping footprint of DECaLS and BASS+MzLS, enabling the unbiased application of our model to galaxy images in both surveys. We observed that noise suppression during DA led to even better morphological feature extraction and classification performance. Overall, this combination of VAE and DA can be applied to achieve image dimensionality reduction, defect image identification, and morphology classification in large optical surveys.
Finding active galactic nuclei through Fink
Nov 20, 2022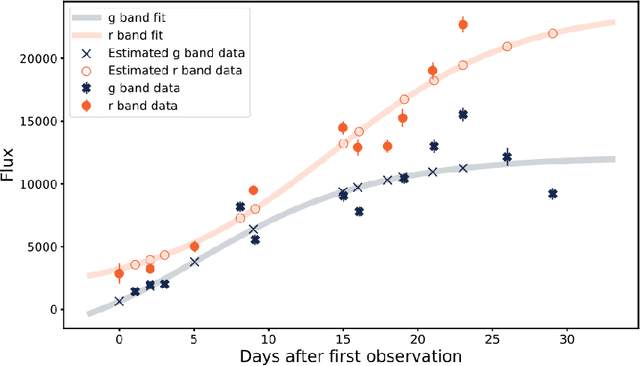
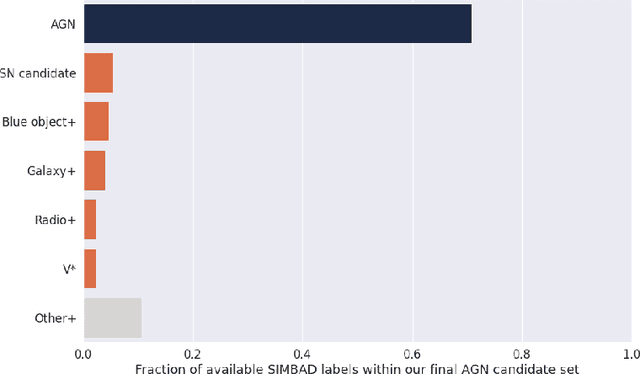
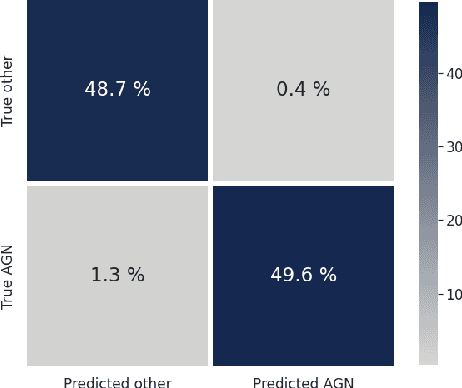
We present the Active Galactic Nuclei (AGN) classifier as currently implemented within the Fink broker. Features were built upon summary statistics of available photometric points, as well as color estimation enabled by symbolic regression. The learning stage includes an active learning loop, used to build an optimized training sample from labels reported in astronomical catalogs. Using this method to classify real alerts from the Zwicky Transient Facility (ZTF), we achieved 98.0% accuracy, 93.8% precision and 88.5% recall. We also describe the modifications necessary to enable processing data from the upcoming Vera C. Rubin Observatory Large Survey of Space and Time (LSST), and apply them to the training sample of the Extended LSST Astronomical Time-series Classification Challenge (ELAsTiCC). Results show that our designed feature space enables high performances of traditional machine learning algorithms in this binary classification task.
Fink: early supernovae Ia classification using active learning
Nov 22, 2021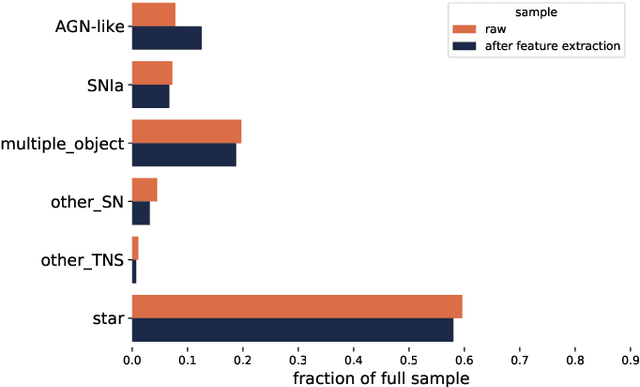
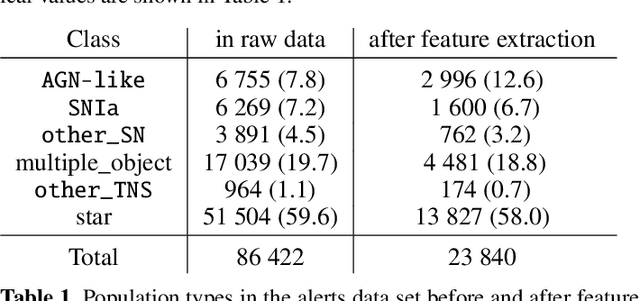
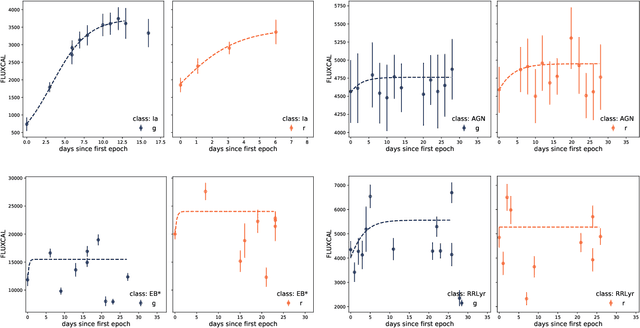

We describe how the Fink broker early supernova Ia classifier optimizes its ML classifications by employing an active learning (AL) strategy. We demonstrate the feasibility of implementation of such strategies in the current Zwicky Transient Facility (ZTF) public alert data stream. We compare the performance of two AL strategies: uncertainty sampling and random sampling. Our pipeline consists of 3 stages: feature extraction, classification and learning strategy. Starting from an initial sample of 10 alerts (5 SN Ia and 5 non-Ia), we let the algorithm identify which alert should be added to the training sample. The system is allowed to evolve through 300 iterations. Our data set consists of 23 840 alerts from the ZTF with confirmed classification via cross-match with SIMBAD database and the Transient name server (TNS), 1 600 of which were SNe Ia (1 021 unique objects). The data configuration, after the learning cycle was completed, consists of 310 alerts for training and 23 530 for testing. Averaging over 100 realizations, the classifier achieved 89% purity and 54% efficiency. From 01/November/2020 to 31/October/2021 Fink has applied its early supernova Ia module to the ZTF stream and communicated promising SN Ia candidates to the TNS. From the 535 spectroscopically classified Fink candidates, 459 (86%) were proven to be SNe Ia. Our results confirm the effectiveness of active learning strategies for guiding the construction of optimal training samples for astronomical classifiers. It demonstrates in real data that the performance of learning algorithms can be highly improved without the need of extra computational resources or overwhelmingly large training samples. This is, to our knowledge, the first application of AL to real alerts data.
Active learning with RESSPECT: Resource allocation for extragalactic astronomical transients
Oct 26, 2020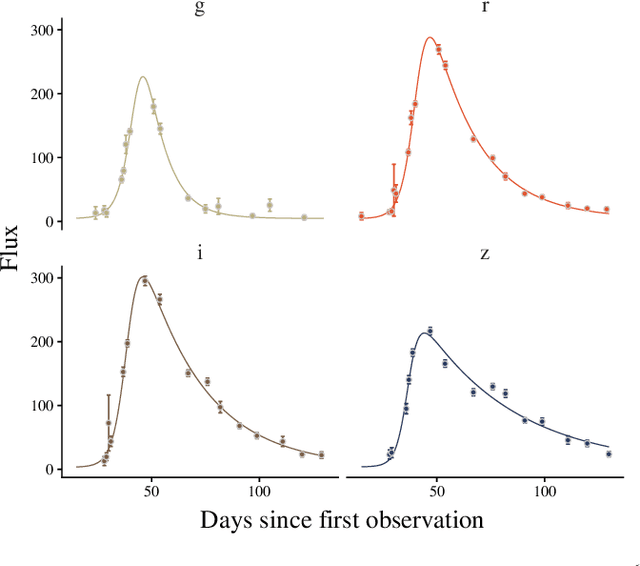
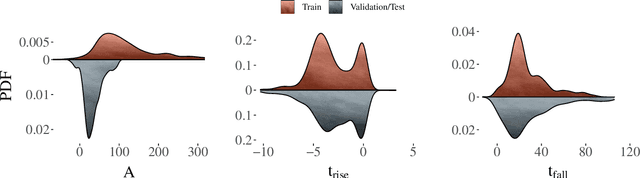
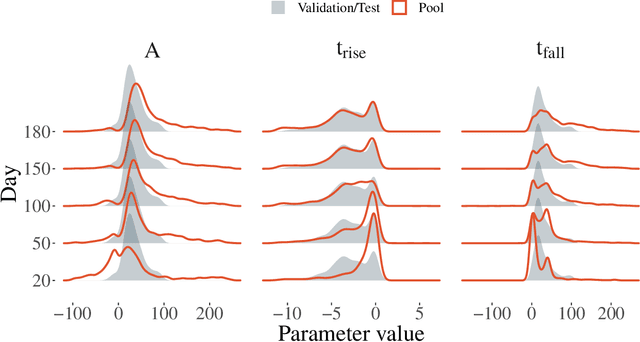
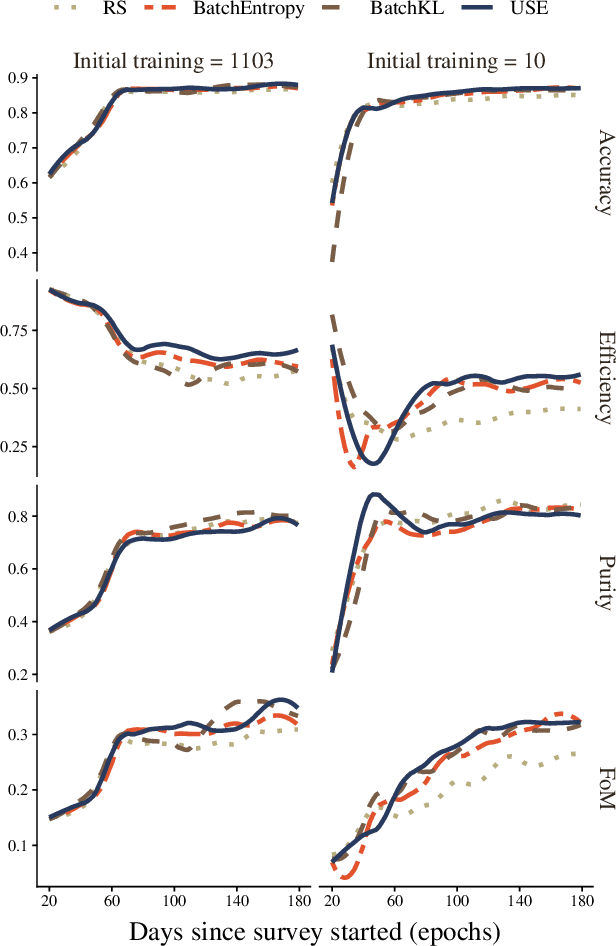
The recent increase in volume and complexity of available astronomical data has led to a wide use of supervised machine learning techniques. Active learning strategies have been proposed as an alternative to optimize the distribution of scarce labeling resources. However, due to the specific conditions in which labels can be acquired, fundamental assumptions, such as sample representativeness and labeling cost stability cannot be fulfilled. The Recommendation System for Spectroscopic follow-up (RESSPECT) project aims to enable the construction of optimized training samples for the Rubin Observatory Legacy Survey of Space and Time (LSST), taking into account a realistic description of the astronomical data environment. In this work, we test the robustness of active learning techniques in a realistic simulated astronomical data scenario. Our experiment takes into account the evolution of training and pool samples, different costs per object, and two different sources of budget. Results show that traditional active learning strategies significantly outperform random sampling. Nevertheless, more complex batch strategies are not able to significantly overcome simple uncertainty sampling techniques. Our findings illustrate three important points: 1) active learning strategies are a powerful tool to optimize the label-acquisition task in astronomy, 2) for upcoming large surveys like LSST, such techniques allow us to tailor the construction of the training sample for the first day of the survey, and 3) the peculiar data environment related to the detection of astronomical transients is a fertile ground that calls for the development of tailored machine learning algorithms.
Active Anomaly Detection for time-domain discoveries
Sep 29, 2019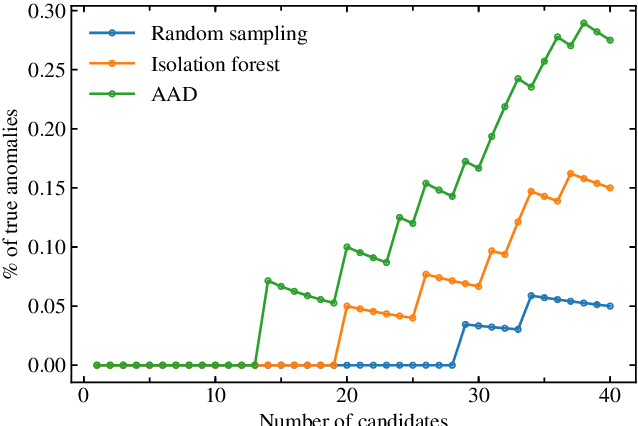
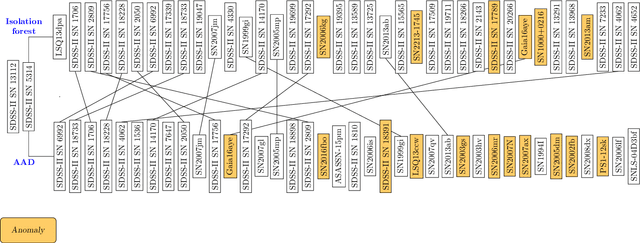
We present the first application of adaptive machine learning to the identification of anomalies in a data set of non-periodic astronomical light curves. The method follows an active learning strategy where highly informative objects are selected to be labelled. This new information is subsequently used to improve the machine learning model, allowing its accuracy to evolve with the addition of every new classification. For the case of anomaly detection, the algorithm aims to maximize the number of real anomalies presented to the expert by slightly modifying the decision boundary of a traditional isolation forest in each iteration. As a proof of concept, we apply the Active Anomaly Discovery (AAD) algorithm to light curves from the Open Supernova Catalog and compare its results to those of a static Isolation Forest (IF). For both methods, we visually inspected objects within 2% highest anomaly scores. We show that AAD was able to identify 80% more true anomalies than IF. This result is the first evidence that AAD algorithms can play a central role in the search for new physics in the era of large scale sky surveys.
Machine Learning and the future of Supernova Cosmology
Aug 06, 2019Machine Learning methods will play a fundamental role in our ability to optimize the science output from the next generation of large scale surveys. Given the peculiarities of astronomical data, it is crucial that algorithms are adapted to the data situation at hand. In this comment, I review the recent efforts towards the development of automatic systems to identify and classify supernova with the goal of enabling their use as cosmological standard candles.