 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Anomaly Detection for time-domain discoveries
Sep 29, 2019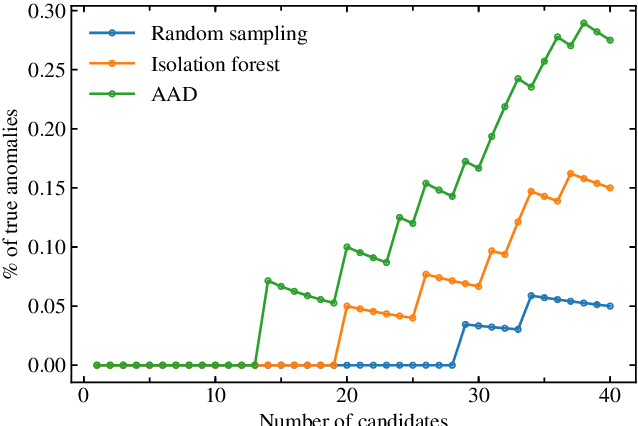
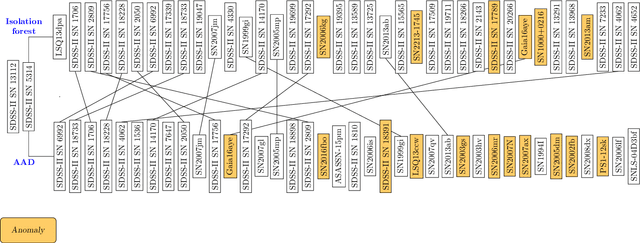
We present the first application of adaptive machine learning to the identification of anomalies in a data set of non-periodic astronomical light curves. The method follows an active learning strategy where highly informative objects are selected to be labelled. This new information is subsequently used to improve the machine learning model, allowing its accuracy to evolve with the addition of every new classification. For the case of anomaly detection, the algorithm aims to maximize the number of real anomalies presented to the expert by slightly modifying the decision boundary of a traditional isolation forest in each iteration. As a proof of concept, we apply the Active Anomaly Discovery (AAD) algorithm to light curves from the Open Supernova Catalog and compare its results to those of a static Isolation Forest (IF). For both methods, we visually inspected objects within 2% highest anomaly scores. We show that AAD was able to identify 80% more true anomalies than IF. This result is the first evidence that AAD algorithms can play a central role in the search for new physics in the era of large scale sky surveys.
Active Anomaly Detection via Ensembles: Insights, Algorithms, and Interpretability
Jan 23, 2019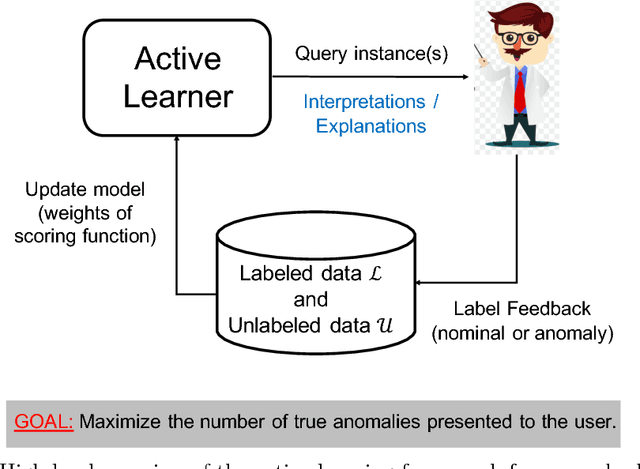
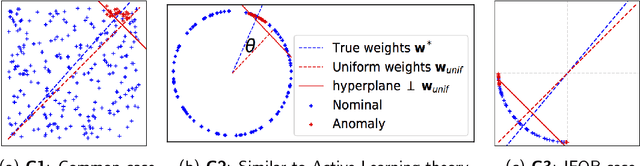
Anomaly detection (AD) task corresponds to identifying the true anomalies from a given set of data instances. AD algorithms score the data instances and produce a ranked list of candidate anomalies, which are then analyzed by a human to discover the true anomalies. However, this process can be laborious for the human analyst when the number of false-positives is very high. Therefore, in many real-world AD applications including computer security and fraud prevention, the anomaly detector must be configurable by the human analyst to minimize the effort on false positives. In this paper, we study the problem of active learning to automatically tune ensemble of anomaly detectors to maximize the number of true anomalies discovered. We make four main contributions towards this goal. First, we present an important insight that explains the practical successes of AD ensembles and how ensembles are naturally suited for active learning. Second, we present several algorithms for active learning with tree-based AD ensembles. These algorithms help us to improve the diversity of discovered anomalies, generate rule sets for improved interpretability of anomalous instances, and adapt to streaming data settings in a principled manner. Third, we present a novel algorithm called GLocalized Anomaly Detection (GLAD) for active learning with generic AD ensembles. GLAD allows end-users to retain the use of simple and understandable global anomaly detectors by automatically learning their local relevance to specific data instances using label feedback. Fourth, we present extensive experiments to evaluate our insights and algorithms. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.
GLAD: GLocalized Anomaly Detection via Active Feature Space Suppression
Oct 12, 2018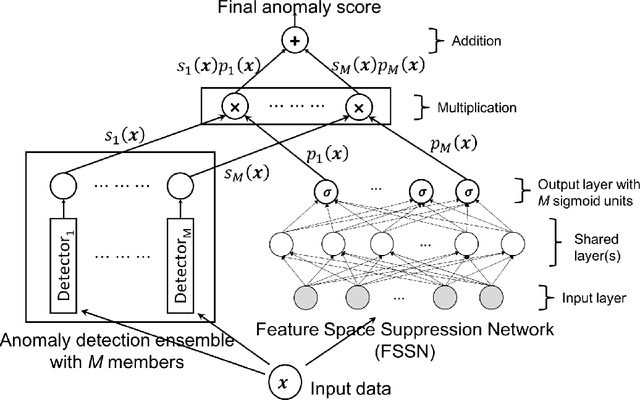
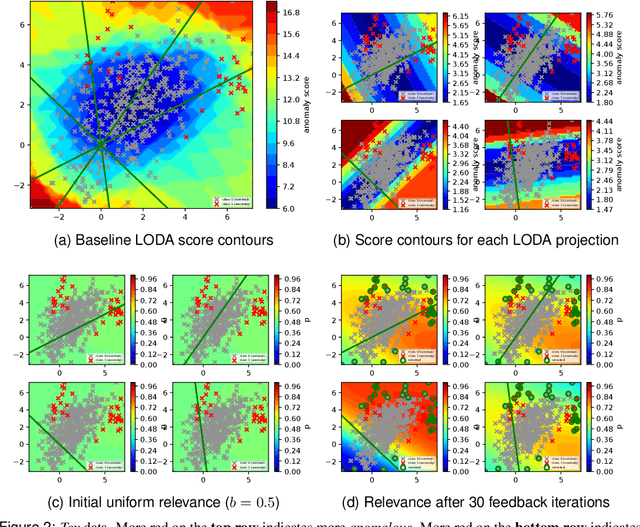
We propose an algorithm called GLAD (GLocalized Anomaly Detection) that allows end-users to retain the use of simple and understandable global anomaly detectors by automatically learning their local relevance to specific data instances using label feedback. The key idea is to place a uniform prior on the relevance of each member of the anomaly detection ensemble over the input feature space via a neural network trained on unlabeled instances, and tune the weights of the neural network to adjust the local relevance of each ensemble member using all labeled instances. Our experiments on synthetic and real-world data show the effectiveness of GLAD in learning the local relevance of ensemble members and discovering anomalies via label feedback.
Active Anomaly Detection via Ensembles
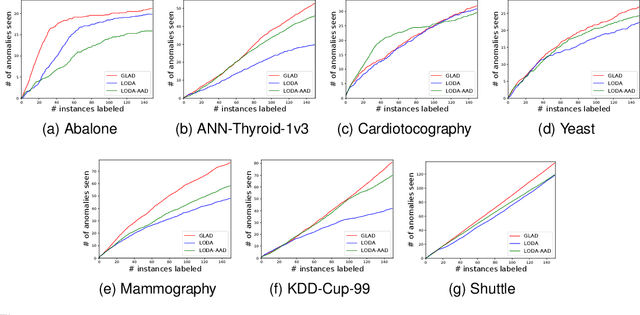
Sep 17, 2018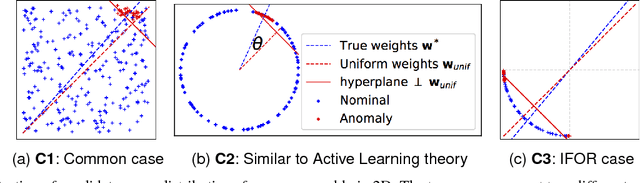
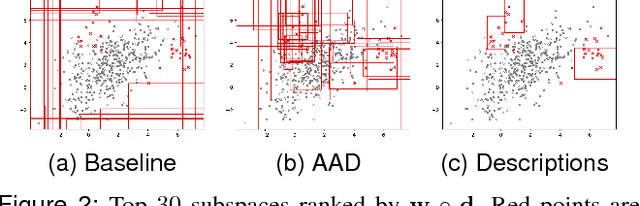
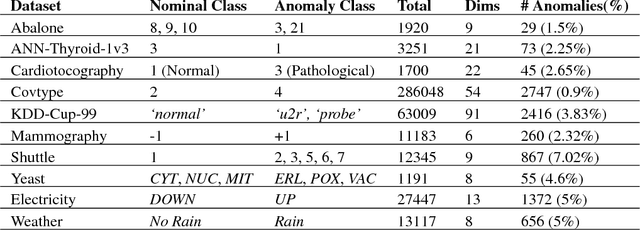
In critical applications of anomaly detection including computer security and fraud prevention, the anomaly detector must be configurable by the analyst to minimize the effort on false positives. One important way to configure the anomaly detector is by providing true labels for a few instances. We study the problem of label-efficient active learning to automatically tune anomaly detection ensembles and make four main contributions. First, we present an important insight into how anomaly detector ensembles are naturally suited for active learning. This insight allows us to relate the greedy querying strategy to uncertainty sampling, with implications for label-efficiency. Second, we present a novel formalism called compact description to describe the discovered anomalies and show that it can also be employed to improve the diversity of the instances presented to the analyst without loss in the anomaly discovery rate. Third, we present a novel data drift detection algorithm that not only detects the drift robustly, but also allows us to take corrective actions to adapt the detector in a principled manner. Fourth, we present extensive experiments to evaluate our insights and algorithms in both batch and streaming settings. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.
Incorporating Feedback into Tree-based Anomaly Detection
Aug 30, 2017
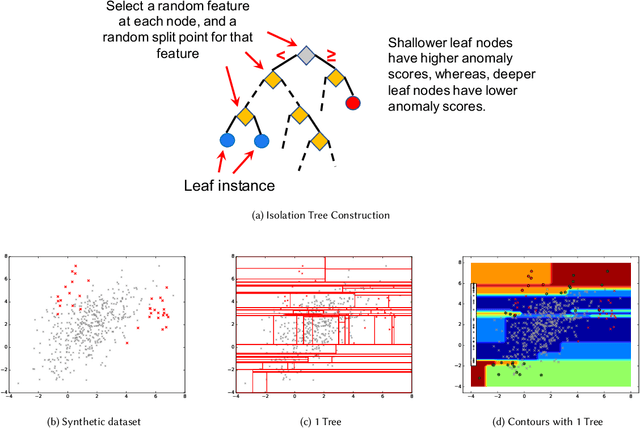
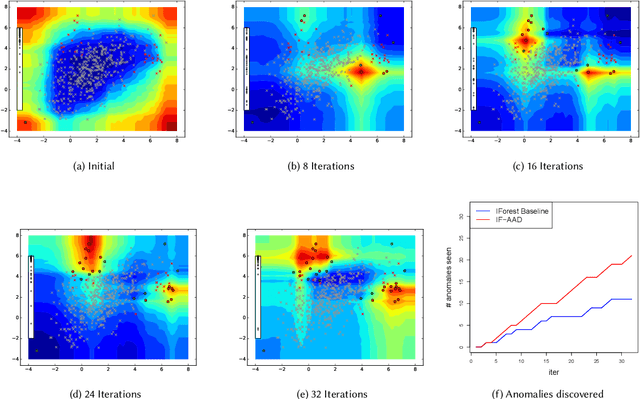
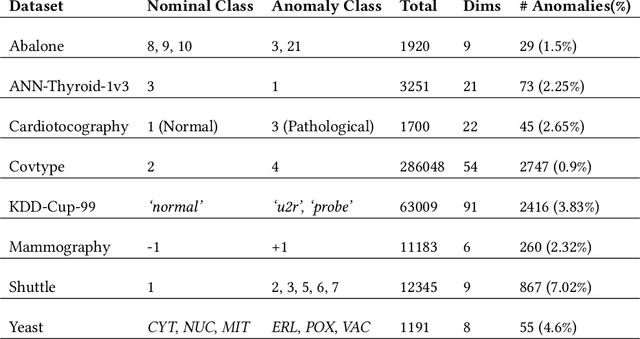
Anomaly detectors are often used to produce a ranked list of statistical anomalies, which are examined by human analysts in order to extract the actual anomalies of interest. Unfortunately, in realworld applications, this process can be exceedingly difficult for the analyst since a large fraction of high-ranking anomalies are false positives and not interesting from the application perspective. In this paper, we aim to make the analyst's job easier by allowing for analyst feedback during the investigation process. Ideally, the feedback influences the ranking of the anomaly detector in a way that reduces the number of false positives that must be examined before discovering the anomalies of interest. In particular, we introduce a novel technique for incorporating simple binary feedback into tree-based anomaly detectors. We focus on the Isolation Forest algorithm as a representative tree-based anomaly detector, and show that we can significantly improve its performance by incorporating feedback, when compared with the baseline algorithm that does not incorporate feedback. Our technique is simple and scales well as the size of the data increases, which makes it suitable for interactive discovery of anomalies in large datasets.
A Meta-Analysis of the Anomaly Detection Problem
Aug 26, 2016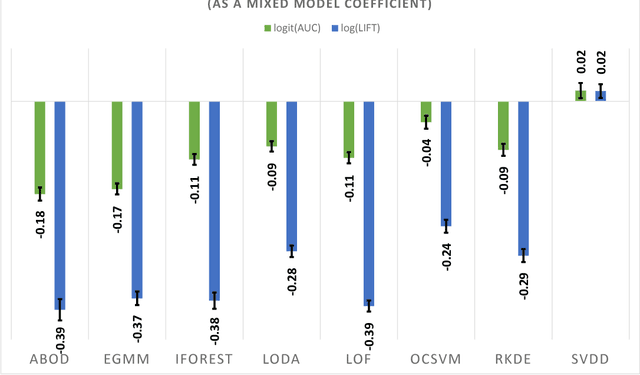
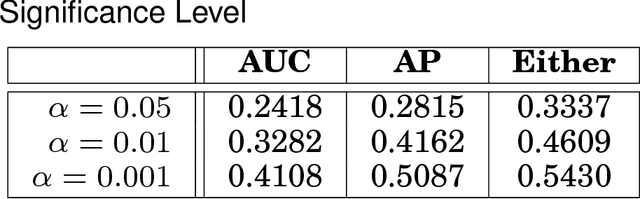
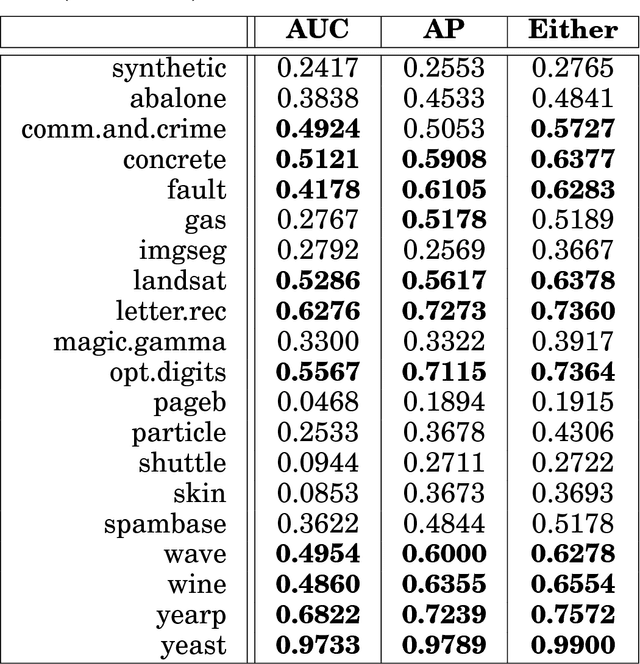
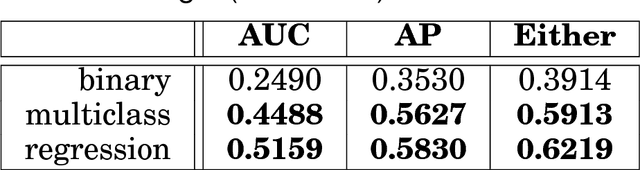
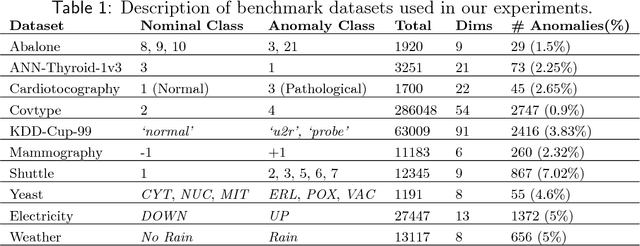
This article provides a thorough meta-analysis of the anomaly detection problem. To accomplish this we first identify approaches to benchmarking anomaly detection algorithms across the literature and produce a large corpus of anomaly detection benchmarks that vary in their construction across several dimensions we deem important to real-world applications: (a) point difficulty, (b) relative frequency of anomalies, (c) clusteredness of anomalies, and (d) relevance of features. We apply a representative set of anomaly detection algorithms to this corpus, yielding a very large collection of experimental results. We analyze these results to understand many phenomena observed in previous work. First we observe the effects of experimental design on experimental results. Second, results are evaluated with two metrics, ROC Area Under the Curve and Average Precision. We employ statistical hypothesis testing to demonstrate the value (or lack thereof) of our benchmarks. We then offer several approaches to summarizing our experimental results, drawing several conclusions about the impact of our methodology as well as the strengths and weaknesses of some algorithms. Last, we compare results against a trivial solution as an alternate means of normalizing the reported performance of algorithms. The intended contributions of this article are many; in addition to providing a large publicly-available corpus of anomaly detection benchmarks, we provide an ontology for describing anomaly detection contexts, a methodology for controlling various aspects of benchmark creation, guidelines for future experimental design and a discussion of the many potential pitfalls of trying to measure success in this field.