 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Search Framework for Multi-Objective Bayesian Optimization
Apr 12, 2022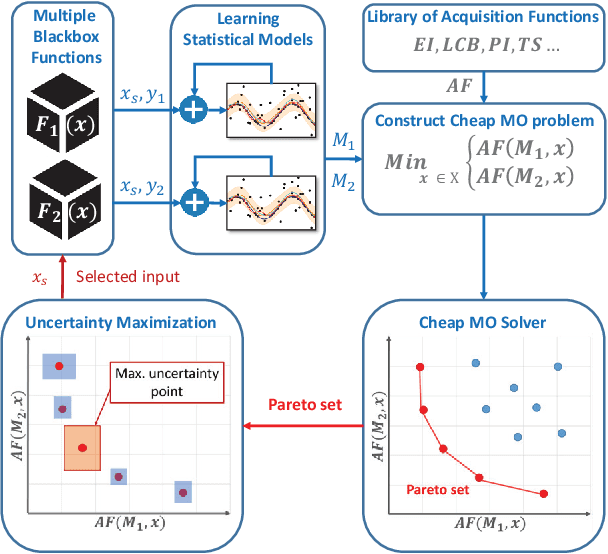
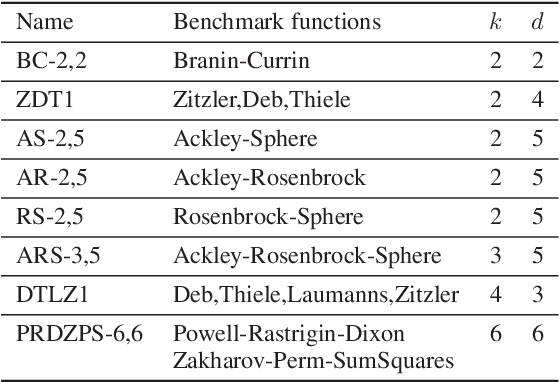
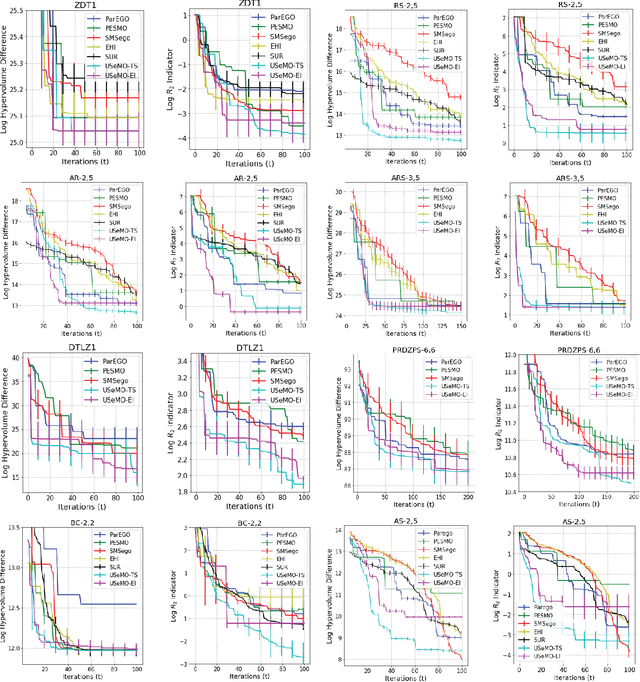
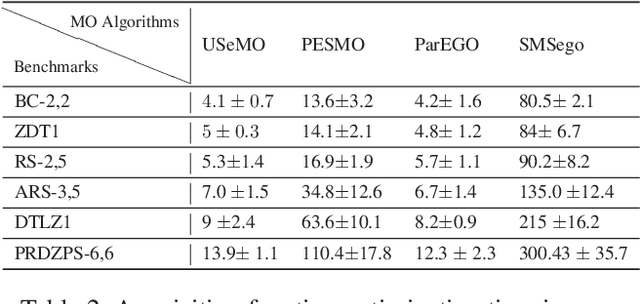
We consider the problem of multi-objective (MO) blackbox optimization using expensive function evaluations, where the goal is to approximate the true Pareto set of solutions while minimizing the number of function evaluations. For example, in hardware design optimization, we need to find the designs that trade-off performance, energy, and area overhead using expensive simulations. We propose a novel uncertainty-aware search framework referred to as USeMO to efficiently select the sequence of inputs for evaluation to solve this problem. The selection method of USeMO consists of solving a cheap MO optimization problem via surrogate models of the true functions to identify the most promising candidates and picking the best candidate based on a measure of uncertainty. We also provide theoretical analysis to characterize the efficacy of our approach. Our experiments on several synthetic and six diverse real-world benchmark problems show that USeMO consistently outperforms the state-of-the-art algorithms.
* Added link to code and missing appendix. arXiv admin note: substantial text overlap with arXiv:2008.07029
SETGAN: Scale and Energy Trade-off GANs for Image Applications on Mobile Platforms
Mar 23, 2021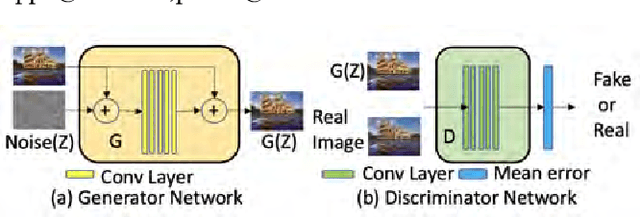

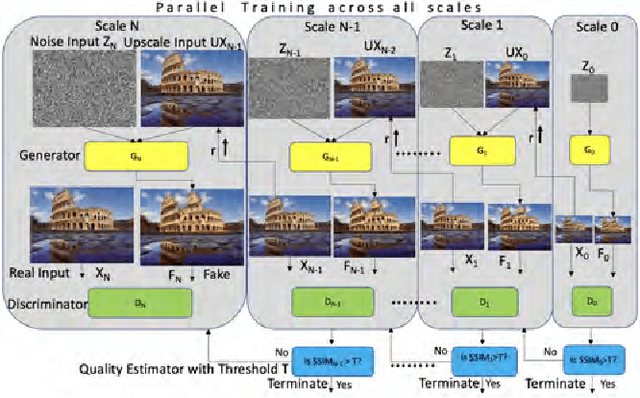
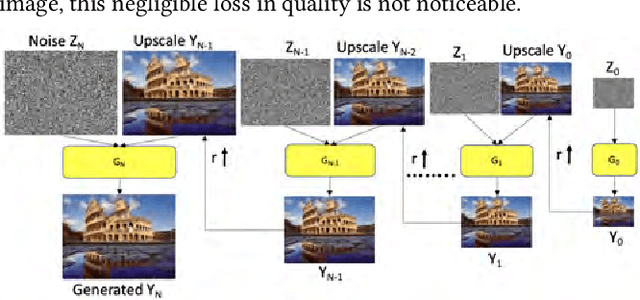
We consider the task of photo-realistic unconditional image generation (generate high quality, diverse samples that carry the same visual content as the image) on mobile platforms using Generative Adversarial Networks (GANs). In this paper, we propose a novel approach to trade-off image generation accuracy of a GAN for the energy consumed (compute) at run-time called Scale-Energy Tradeoff GAN (SETGAN). GANs usually take a long time to train and consume a huge memory hence making it difficult to run on edge devices. The key idea behind SETGAN for an image generation task is for a given input image, we train a GAN on a remote server and use the trained model on edge devices. We use SinGAN, a single image unconditional generative model, that contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. During the training process, we determine the optimal number of scales for a given input image and the energy constraint from the target edge device. Results show that with SETGAN's unique client-server-based architecture, we were able to achieve a 56% gain in energy for a loss of 3% to 12% SSIM accuracy. Also, with the parallel multi-scale training, we obtain around 4x gain in training time on the server.
Trading-off Accuracy and Energy of Deep Inference on Embedded Systems: A Co-Design Approach
Jan 29, 2019
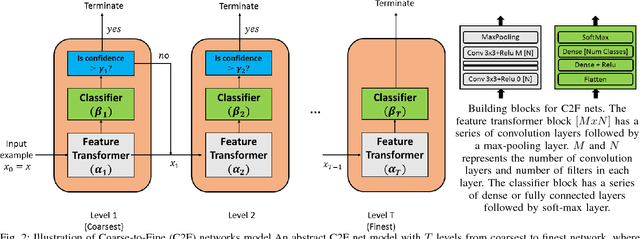
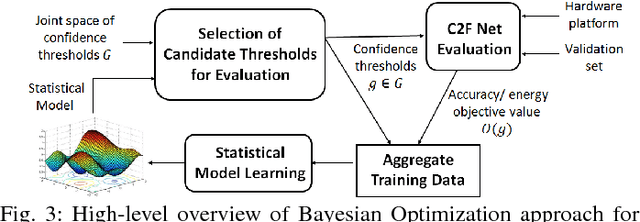
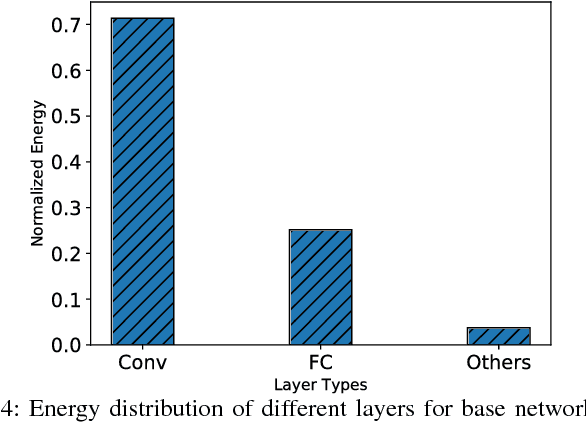
Deep neural networks have seen tremendous success for different modalities of data including images, videos, and speech. This success has led to their deployment in mobile and embedded systems for real-time applications. However, making repeated inferences using deep networks on embedded systems poses significant challenges due to constrained resources (e.g., energy and computing power). To address these challenges, we develop a principled co-design approach. Building on prior work, we develop a formalism referred to as Coarse-to-Fine Networks (C2F Nets) that allow us to employ classifiers of varying complexity to make predictions. We propose a principled optimization algorithm to automatically configure C2F Nets for a specified trade-off between accuracy and energy consumption for inference. The key idea is to select a classifier on-the-fly whose complexity is proportional to the hardness of the input example: simple classifiers for easy inputs and complex classifiers for hard inputs. We perform comprehensive experimental evaluation using four different C2F Net architectures on multiple real-world image classification tasks. Our results show that optimized C2F Net can reduce the Energy Delay Product (EDP) by 27 to 60 percent with no loss in accuracy when compared to the baseline solution, where all predictions are made using the most complex classifier in C2F Net.
* Published in IEEE Trans. on CAD of Integrated Circuits and Systems
Active Anomaly Detection via Ensembles: Insights, Algorithms, and Interpretability
Jan 23, 2019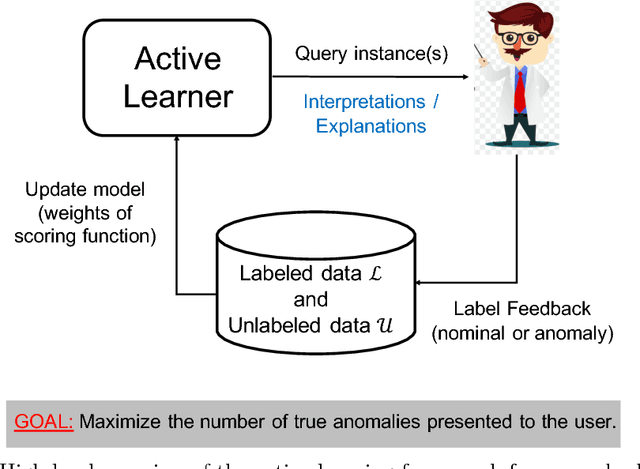
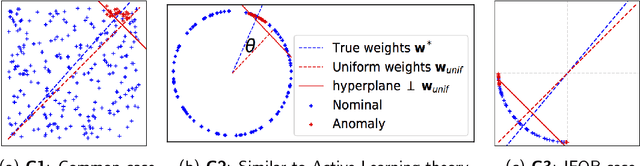
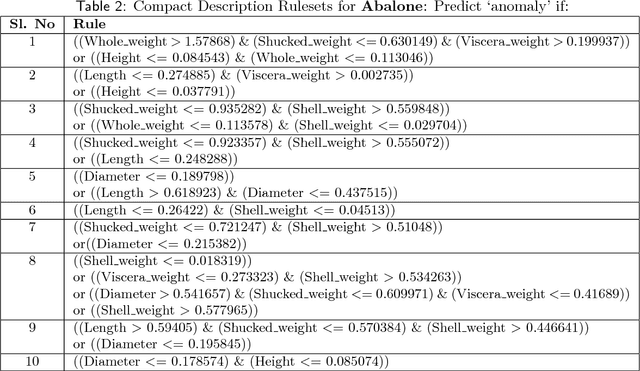
Anomaly detection (AD) task corresponds to identifying the true anomalies from a given set of data instances. AD algorithms score the data instances and produce a ranked list of candidate anomalies, which are then analyzed by a human to discover the true anomalies. However, this process can be laborious for the human analyst when the number of false-positives is very high. Therefore, in many real-world AD applications including computer security and fraud prevention, the anomaly detector must be configurable by the human analyst to minimize the effort on false positives. In this paper, we study the problem of active learning to automatically tune ensemble of anomaly detectors to maximize the number of true anomalies discovered. We make four main contributions towards this goal. First, we present an important insight that explains the practical successes of AD ensembles and how ensembles are naturally suited for active learning. Second, we present several algorithms for active learning with tree-based AD ensembles. These algorithms help us to improve the diversity of discovered anomalies, generate rule sets for improved interpretability of anomalous instances, and adapt to streaming data settings in a principled manner. Third, we present a novel algorithm called GLocalized Anomaly Detection (GLAD) for active learning with generic AD ensembles. GLAD allows end-users to retain the use of simple and understandable global anomaly detectors by automatically learning their local relevance to specific data instances using label feedback. Fourth, we present extensive experiments to evaluate our insights and algorithms. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.
Active Anomaly Detection via Ensembles
Sep 17, 2018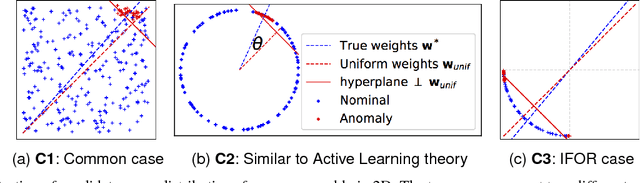
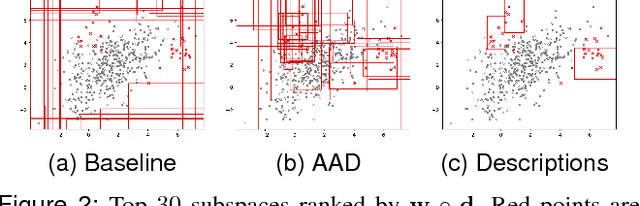
In critical applications of anomaly detection including computer security and fraud prevention, the anomaly detector must be configurable by the analyst to minimize the effort on false positives. One important way to configure the anomaly detector is by providing true labels for a few instances. We study the problem of label-efficient active learning to automatically tune anomaly detection ensembles and make four main contributions. First, we present an important insight into how anomaly detector ensembles are naturally suited for active learning. This insight allows us to relate the greedy querying strategy to uncertainty sampling, with implications for label-efficiency. Second, we present a novel formalism called compact description to describe the discovered anomalies and show that it can also be employed to improve the diversity of the instances presented to the analyst without loss in the anomaly discovery rate. Third, we present a novel data drift detection algorithm that not only detects the drift robustly, but also allows us to take corrective actions to adapt the detector in a principled manner. Fourth, we present extensive experiments to evaluate our insights and algorithms in both batch and streaming settings. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.