 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Demo-to-Code via Neurosymbolic Counterfactual Reasoning
Mar 19, 2026Recent advances in Vision-Language Models (VLMs) have enabled video-instructed robotic programming, allowing agents to interpret video demonstrations and generate executable control code. We formulate video-instructed robotic programming as a cross-domain adaptation problem, where perceptual and physical differences between demonstration and deployment induce procedural mismatches. However, current VLMs lack the procedural understanding needed to reformulate causal dependencies and achieve task-compatible behavior under such domain shifts. We introduce NeSyCR, a neurosymbolic counterfactual reasoning framework that enables verifiable adaptation of task procedures, providing a reliable synthesis of code policies. NeSyCR abstracts video demonstrations into symbolic trajectories that capture the underlying task procedure. Given deployment observations, it derives counterfactual states that reveal cross-domain incompatibilities. By exploring the symbolic state space with verifiable checks, NeSyCR proposes procedural revisions that restore compatibility with the demonstrated procedure. NeSyCR achieves a 31.14% improvement in task success over the strongest baseline Statler, showing robust cross-domain adaptation across both simulated and real-world manipulation tasks.
Efficient Policy Adaptation with Contrastive Prompt Ensemble for Embodied Agents
Dec 16, 2024



For embodied reinforcement learning (RL) agents interacting with the environment, it is desirable to have rapid policy adaptation to unseen visual observations, but achieving zero-shot adaptation capability is considered as a challenging problem in the RL context. To address the problem, we present a novel contrastive prompt ensemble (ConPE) framework which utilizes a pretrained vision-language model and a set of visual prompts, thus enabling efficient policy learning and adaptation upon a wide range of environmental and physical changes encountered by embodied agents. Specifically, we devise a guided-attention-based ensemble approach with multiple visual prompts on the vision-language model to construct robust state representations. Each prompt is contrastively learned in terms of an individual domain factor that significantly affects the agent's egocentric perception and observation. For a given task, the attention-based ensemble and policy are jointly learned so that the resulting state representations not only generalize to various domains but are also optimized for learning the task. Through experiments, we show that ConPE outperforms other state-of-the-art algorithms for several embodied agent tasks including navigation in AI2THOR, manipulation in egocentric-Metaworld, and autonomous driving in CARLA, while also improving the sample efficiency of policy learning and adaptation.
Embodied CoT Distillation From LLM To Off-the-shelf Agents
Dec 16, 2024



We address the challenge of utilizing large language models (LLMs) for complex embodied tasks, in the environment where decision-making systems operate timely on capacity-limited, off-the-shelf devices. We present DeDer, a framework for decomposing and distilling the embodied reasoning capabilities from LLMs to efficient, small language model (sLM)-based policies. In DeDer, the decision-making process of LLM-based strategies is restructured into a hierarchy with a reasoning-policy and planning-policy. The reasoning-policy is distilled from the data that is generated through the embodied in-context learning and self-verification of an LLM, so it can produce effective rationales. The planning-policy, guided by the rationales, can render optimized plans efficiently. In turn, DeDer allows for adopting sLMs for both policies, deployed on off-the-shelf devices. Furthermore, to enhance the quality of intermediate rationales, specific to embodied tasks, we devise the embodied knowledge graph, and to generate multiple rationales timely through a single inference, we also use the contrastively prompted attention model. Our experiments with the ALFRED benchmark demonstrate that DeDer surpasses leading language planning and distillation approaches, indicating the applicability and efficiency of sLM-based embodied policies derived through DeDer.
Incremental Learning of Retrievable Skills For Efficient Continual Task Adaptation
Oct 30, 2024



Continual Imitation Learning (CiL) involves extracting and accumulating task knowledge from demonstrations across multiple stages and tasks to achieve a multi-task policy. With recent advancements in foundation models, there has been a growing interest in adapter-based CiL approaches, where adapters are established parameter-efficiently for tasks newly demonstrated. While these approaches isolate parameters for specific tasks and tend to mitigate catastrophic forgetting, they limit knowledge sharing among different demonstrations. We introduce IsCiL, an adapter-based CiL framework that addresses this limitation of knowledge sharing by incrementally learning shareable skills from different demonstrations, thus enabling sample-efficient task adaptation using the skills particularly in non-stationary CiL environments. In IsCiL, demonstrations are mapped into the state embedding space, where proper skills can be retrieved upon input states through prototype-based memory. These retrievable skills are incrementally learned on their corresponding adapters. Our CiL experiments with complex tasks in Franka-Kitchen and Meta-World demonstrate robust performance of IsCiL in both task adaptation and sample-efficiency. We also show a simple extension of IsCiL for task unlearning scenarios.
Trading-off Accuracy and Energy of Deep Inference on Embedded Systems: A Co-Design Approach
Jan 29, 2019
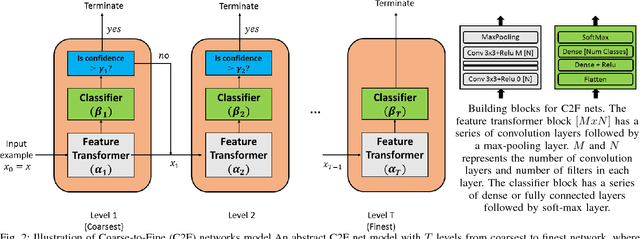
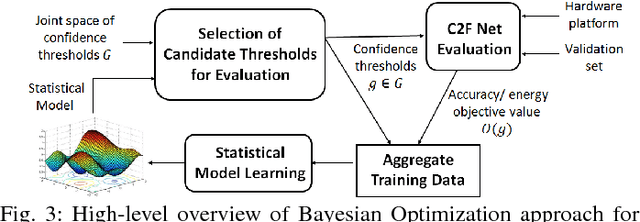
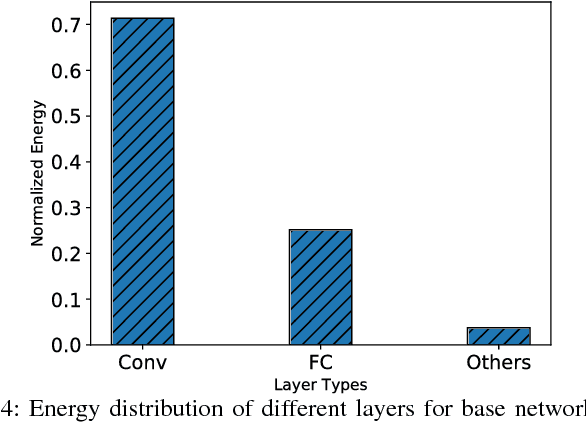
Deep neural networks have seen tremendous success for different modalities of data including images, videos, and speech. This success has led to their deployment in mobile and embedded systems for real-time applications. However, making repeated inferences using deep networks on embedded systems poses significant challenges due to constrained resources (e.g., energy and computing power). To address these challenges, we develop a principled co-design approach. Building on prior work, we develop a formalism referred to as Coarse-to-Fine Networks (C2F Nets) that allow us to employ classifiers of varying complexity to make predictions. We propose a principled optimization algorithm to automatically configure C2F Nets for a specified trade-off between accuracy and energy consumption for inference. The key idea is to select a classifier on-the-fly whose complexity is proportional to the hardness of the input example: simple classifiers for easy inputs and complex classifiers for hard inputs. We perform comprehensive experimental evaluation using four different C2F Net architectures on multiple real-world image classification tasks. Our results show that optimized C2F Net can reduce the Energy Delay Product (EDP) by 27 to 60 percent with no loss in accuracy when compared to the baseline solution, where all predictions are made using the most complex classifier in C2F Net.
* Published in IEEE Trans. on CAD of Integrated Circuits and Systems