 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Demo-to-Code via Neurosymbolic Counterfactual Reasoning
Mar 19, 2026Recent advances in Vision-Language Models (VLMs) have enabled video-instructed robotic programming, allowing agents to interpret video demonstrations and generate executable control code. We formulate video-instructed robotic programming as a cross-domain adaptation problem, where perceptual and physical differences between demonstration and deployment induce procedural mismatches. However, current VLMs lack the procedural understanding needed to reformulate causal dependencies and achieve task-compatible behavior under such domain shifts. We introduce NeSyCR, a neurosymbolic counterfactual reasoning framework that enables verifiable adaptation of task procedures, providing a reliable synthesis of code policies. NeSyCR abstracts video demonstrations into symbolic trajectories that capture the underlying task procedure. Given deployment observations, it derives counterfactual states that reveal cross-domain incompatibilities. By exploring the symbolic state space with verifiable checks, NeSyCR proposes procedural revisions that restore compatibility with the demonstrated procedure. NeSyCR achieves a 31.14% improvement in task success over the strongest baseline Statler, showing robust cross-domain adaptation across both simulated and real-world manipulation tasks.
Test-Time Mixture of World Models for Embodied Agents in Dynamic Environments
Jan 30, 2026Language model (LM)-based embodied agents are increasingly deployed in real-world settings. Yet, their adaptability remains limited in dynamic environments, where constructing accurate and flexible world models is crucial for effective reasoning and decision-making. To address this challenge, we extend the Mixture-of-Experts (MoE) paradigm to embodied agents. While conventional MoE architectures modularize knowledge into expert components with pre-trained routing, they remain rigid once deployed, making them less effective for adapting to unseen domains in dynamic environments. We therefore propose Test-time Mixture of World Models (TMoW), a framework that enhances adaptability to unseen and evolving domains. TMoW updates its routing function over world models at test time, unlike conventional MoE where the function remains fixed, enabling agents to recombine existing models and integrate new ones for continual adaptation. It achieves this through (i) multi-granular prototype-based routing, which adapts mixtures across object- to scene-level similarities, (ii) test-time refinement that aligns unseen domain features with prototypes during inference, and (iii) distilled mixture-based augmentation, which efficiently constructs new models from few-shot data and existing prototypes. We evaluate TMoW on VirtualHome, ALFWorld, and RLBench benchmarks, demonstrating strong performance in both zero-shot adaptation and few-shot expansion scenarios, and showing that it enables embodied agents to operate effectively in dynamic environments.
Exploratory Retrieval-Augmented Planning For Continual Embodied Instruction Following
Sep 10, 2025This study presents an Exploratory Retrieval-Augmented Planning (ExRAP) framework, designed to tackle continual instruction following tasks of embodied agents in dynamic, non-stationary environments. The framework enhances Large Language Models' (LLMs) embodied reasoning capabilities by efficiently exploring the physical environment and establishing the environmental context memory, thereby effectively grounding the task planning process in time-varying environment contexts. In ExRAP, given multiple continual instruction following tasks, each instruction is decomposed into queries on the environmental context memory and task executions conditioned on the query results. To efficiently handle these multiple tasks that are performed continuously and simultaneously, we implement an exploration-integrated task planning scheme by incorporating the {information-based exploration} into the LLM-based planning process. Combined with memory-augmented query evaluation, this integrated scheme not only allows for a better balance between the validity of the environmental context memory and the load of environment exploration, but also improves overall task performance. Furthermore, we devise a {temporal consistency refinement} scheme for query evaluation to address the inherent decay of knowledge in the memory. Through experiments with VirtualHome, ALFRED, and CARLA, our approach demonstrates robustness against a variety of embodied instruction following scenarios involving different instruction scales and types, and non-stationarity degrees, and it consistently outperforms other state-of-the-art LLM-based task planning approaches in terms of both goal success rate and execution efficiency.
* 21 pages. NeurIPS 2024
World Model Implanting for Test-time Adaptation of Embodied Agents
Sep 04, 2025In embodied AI, a persistent challenge is enabling agents to robustly adapt to novel domains without requiring extensive data collection or retraining. To address this, we present a world model implanting framework (WorMI) that combines the reasoning capabilities of large language models (LLMs) with independently learned, domain-specific world models through test-time composition. By allowing seamless implantation and removal of the world models, the embodied agent's policy achieves and maintains cross-domain adaptability. In the WorMI framework, we employ a prototype-based world model retrieval approach, utilizing efficient trajectory-based abstract representation matching, to incorporate relevant models into test-time composition. We also develop a world-wise compound attention method that not only integrates the knowledge from the retrieved world models but also aligns their intermediate representations with the reasoning model's representation within the agent's policy. This framework design effectively fuses domain-specific knowledge from multiple world models, ensuring robust adaptation to unseen domains. We evaluate our WorMI on the VirtualHome and ALFWorld benchmarks, demonstrating superior zero-shot and few-shot performance compared to several LLM-based approaches across a range of unseen domains. These results highlight the frameworks potential for scalable, real-world deployment in embodied agent scenarios where adaptability and data efficiency are essential.
Embodied CoT Distillation From LLM To Off-the-shelf Agents
Dec 16, 2024



We address the challenge of utilizing large language models (LLMs) for complex embodied tasks, in the environment where decision-making systems operate timely on capacity-limited, off-the-shelf devices. We present DeDer, a framework for decomposing and distilling the embodied reasoning capabilities from LLMs to efficient, small language model (sLM)-based policies. In DeDer, the decision-making process of LLM-based strategies is restructured into a hierarchy with a reasoning-policy and planning-policy. The reasoning-policy is distilled from the data that is generated through the embodied in-context learning and self-verification of an LLM, so it can produce effective rationales. The planning-policy, guided by the rationales, can render optimized plans efficiently. In turn, DeDer allows for adopting sLMs for both policies, deployed on off-the-shelf devices. Furthermore, to enhance the quality of intermediate rationales, specific to embodied tasks, we devise the embodied knowledge graph, and to generate multiple rationales timely through a single inference, we also use the contrastively prompted attention model. Our experiments with the ALFRED benchmark demonstrate that DeDer surpasses leading language planning and distillation approaches, indicating the applicability and efficiency of sLM-based embodied policies derived through DeDer.
Efficient Policy Adaptation with Contrastive Prompt Ensemble for Embodied Agents
Dec 16, 2024



For embodied reinforcement learning (RL) agents interacting with the environment, it is desirable to have rapid policy adaptation to unseen visual observations, but achieving zero-shot adaptation capability is considered as a challenging problem in the RL context. To address the problem, we present a novel contrastive prompt ensemble (ConPE) framework which utilizes a pretrained vision-language model and a set of visual prompts, thus enabling efficient policy learning and adaptation upon a wide range of environmental and physical changes encountered by embodied agents. Specifically, we devise a guided-attention-based ensemble approach with multiple visual prompts on the vision-language model to construct robust state representations. Each prompt is contrastively learned in terms of an individual domain factor that significantly affects the agent's egocentric perception and observation. For a given task, the attention-based ensemble and policy are jointly learned so that the resulting state representations not only generalize to various domains but are also optimized for learning the task. Through experiments, we show that ConPE outperforms other state-of-the-art algorithms for several embodied agent tasks including navigation in AI2THOR, manipulation in egocentric-Metaworld, and autonomous driving in CARLA, while also improving the sample efficiency of policy learning and adaptation.
LLM-Based Offline Learning for Embodied Agents via Consistency-Guided Reward Ensemble
Nov 26, 2024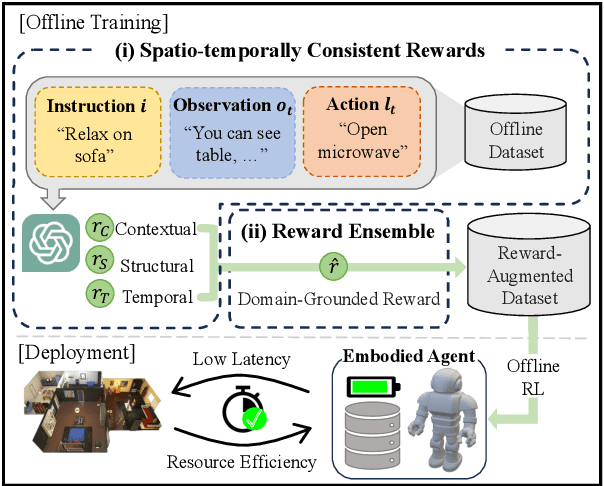
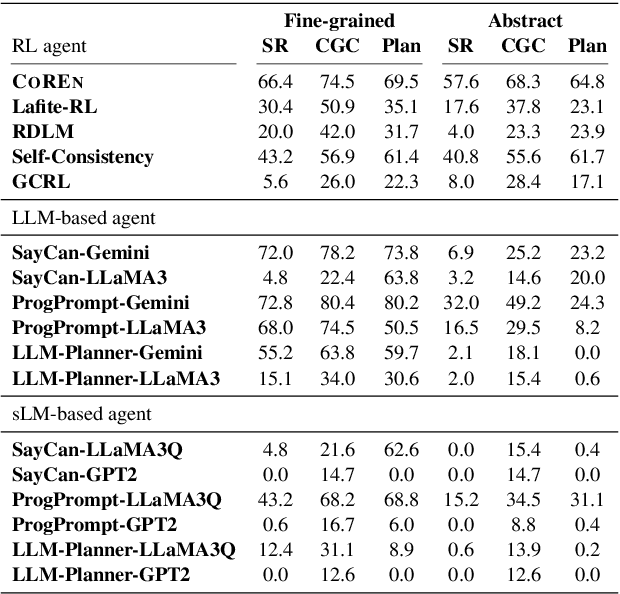
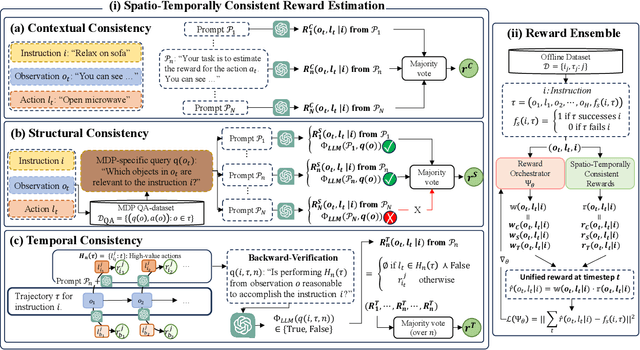
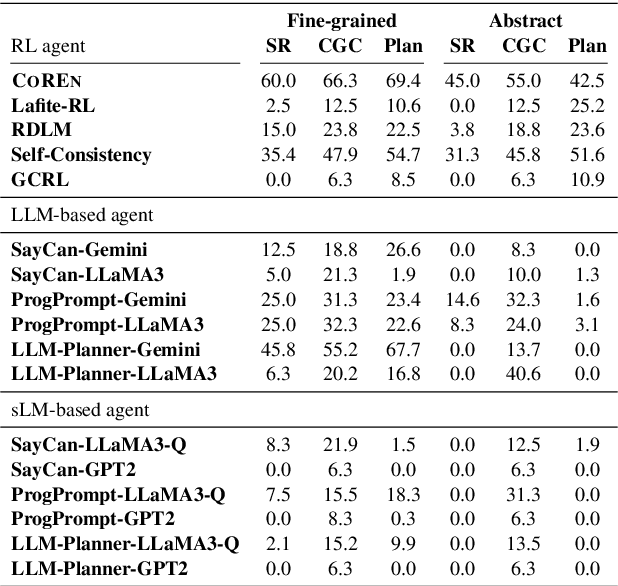
Employing large language models (LLMs) to enable embodied agents has become popular, yet it presents several limitations in practice. In this work, rather than using LLMs directly as agents, we explore their use as tools for embodied agent learning. Specifically, to train separate agents via offline reinforcement learning (RL), an LLM is used to provide dense reward feedback on individual actions in training datasets. In doing so, we present a consistency-guided reward ensemble framework (CoREN), designed for tackling difficulties in grounding LLM-generated estimates to the target environment domain. The framework employs an adaptive ensemble of spatio-temporally consistent rewards to derive domain-grounded rewards in the training datasets, thus enabling effective offline learning of embodied agents in different environment domains. Experiments with the VirtualHome benchmark demonstrate that CoREN significantly outperforms other offline RL agents, and it also achieves comparable performance to state-of-the-art LLM-based agents with 8B parameters, despite CoREN having only 117M parameters for the agent policy network and using LLMs only for training.
Incremental Learning of Retrievable Skills For Efficient Continual Task Adaptation
Oct 30, 2024



Continual Imitation Learning (CiL) involves extracting and accumulating task knowledge from demonstrations across multiple stages and tasks to achieve a multi-task policy. With recent advancements in foundation models, there has been a growing interest in adapter-based CiL approaches, where adapters are established parameter-efficiently for tasks newly demonstrated. While these approaches isolate parameters for specific tasks and tend to mitigate catastrophic forgetting, they limit knowledge sharing among different demonstrations. We introduce IsCiL, an adapter-based CiL framework that addresses this limitation of knowledge sharing by incrementally learning shareable skills from different demonstrations, thus enabling sample-efficient task adaptation using the skills particularly in non-stationary CiL environments. In IsCiL, demonstrations are mapped into the state embedding space, where proper skills can be retrieved upon input states through prototype-based memory. These retrievable skills are incrementally learned on their corresponding adapters. Our CiL experiments with complex tasks in Franka-Kitchen and Meta-World demonstrate robust performance of IsCiL in both task adaptation and sample-efficiency. We also show a simple extension of IsCiL for task unlearning scenarios.
Skills Regularized Task Decomposition for Multi-task Offline Reinforcement Learning
Aug 28, 2024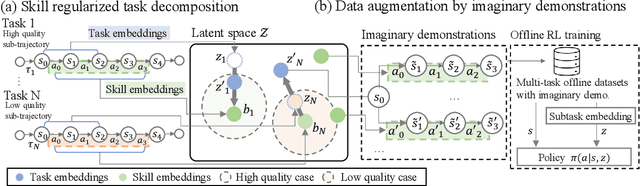
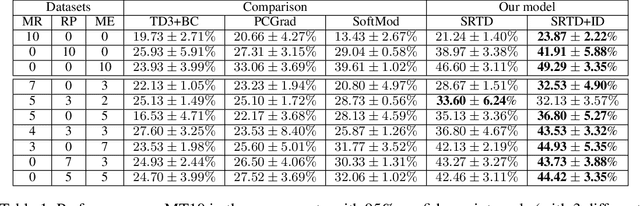
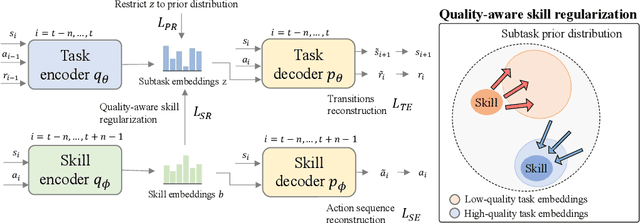
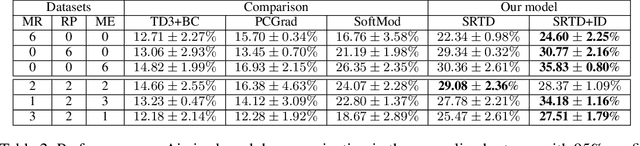
Reinforcement learning (RL) with diverse offline datasets can have the advantage of leveraging the relation of multiple tasks and the common skills learned across those tasks, hence allowing us to deal with real-world complex problems efficiently in a data-driven way. In offline RL where only offline data is used and online interaction with the environment is restricted, it is yet difficult to achieve the optimal policy for multiple tasks, especially when the data quality varies for the tasks. In this paper, we present a skill-based multi-task RL technique on heterogeneous datasets that are generated by behavior policies of different quality. To learn the shareable knowledge across those datasets effectively, we employ a task decomposition method for which common skills are jointly learned and used as guidance to reformulate a task in shared and achievable subtasks. In this joint learning, we use Wasserstein auto-encoder (WAE) to represent both skills and tasks on the same latent space and use the quality-weighted loss as a regularization term to induce tasks to be decomposed into subtasks that are more consistent with high-quality skills than others. To improve the performance of offline RL agents learned on the latent space, we also augment datasets with imaginary trajectories relevant to high-quality skills for each task. Through experiments, we show that our multi-task offline RL approach is robust to the mixed configurations of different-quality datasets and it outperforms other state-of-the-art algorithms for several robotic manipulation tasks and drone navigation tasks.
Pareto Inverse Reinforcement Learning for Diverse Expert Policy Generation
Aug 22, 2024Data-driven offline reinforcement learning and imitation learning approaches have been gaining popularity in addressing sequential decision-making problems. Yet, these approaches rarely consider learning Pareto-optimal policies from a limited pool of expert datasets. This becomes particularly marked due to practical limitations in obtaining comprehensive datasets for all preferences, where multiple conflicting objectives exist and each expert might hold a unique optimization preference for these objectives. In this paper, we adapt inverse reinforcement learning (IRL) by using reward distance estimates for regularizing the discriminator. This enables progressive generation of a set of policies that accommodate diverse preferences on the multiple objectives, while using only two distinct datasets, each associated with a different expert preference. In doing so, we present a Pareto IRL framework (ParIRL) that establishes a Pareto policy set from these limited datasets. In the framework, the Pareto policy set is then distilled into a single, preference-conditioned diffusion model, thus allowing users to immediately specify which expert's patterns they prefer. Through experiments, we show that ParIRL outperforms other IRL algorithms for various multi-objective control tasks, achieving the dense approximation of the Pareto frontier. We also demonstrate the applicability of ParIRL with autonomous driving in CARLA.