 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Reversal Curse Mitigation in Masked Diffusion Models through Attention and Training Dynamics
Feb 02, 2026Autoregressive language models (ARMs) suffer from the reversal curse: after learning that "$A$ is $B$", they often fail on the reverse query "$B$ is $A$". Masked diffusion-based language models (MDMs) exhibit this failure in a much weaker form, but the underlying reason has remained unclear. A common explanation attributes this mitigation to the any-order training objective. However, observing "[MASK] is $B$" during training does not necessarily teach the model to handle the reverse prompt "$B$ is [MASK]". We show that the mitigation arises from architectural structure and its interaction with training. In a one-layer Transformer encoder, weight sharing couples the two directions by making forward and reverse attention scores positively correlated. In the same setting, we further show that the corresponding gradients are aligned, so minimizing the forward loss also reduces the reverse loss. Experiments on both controlled toy tasks and large-scale diffusion language models support these mechanisms, explaining why MDMs partially overcome a failure mode that persists in strong ARMs.
LLM-Based Offline Learning for Embodied Agents via Consistency-Guided Reward Ensemble
Nov 26, 2024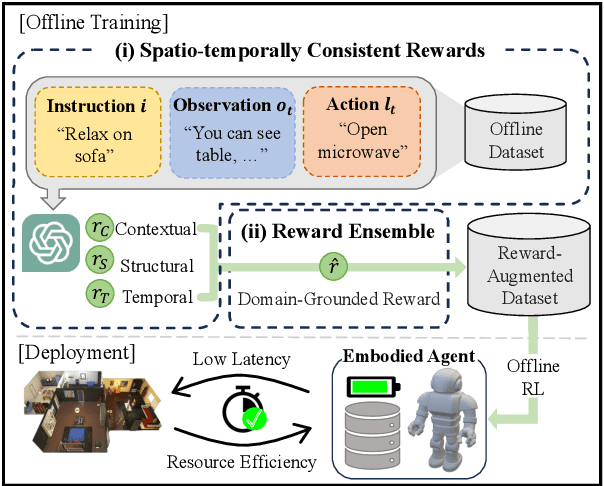
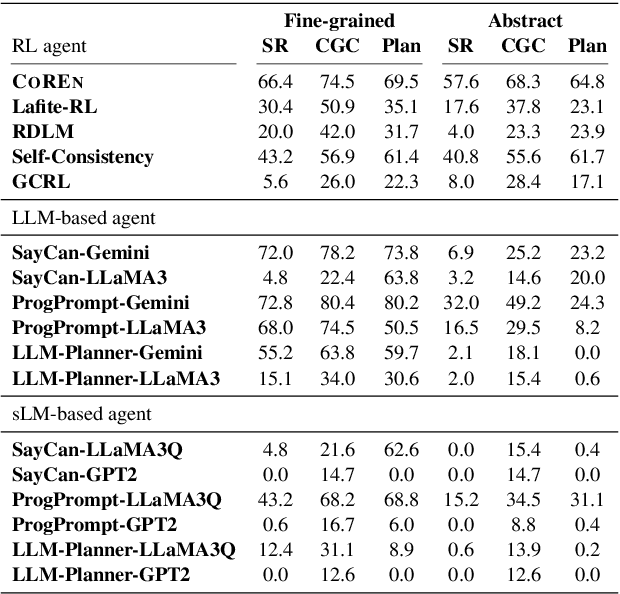
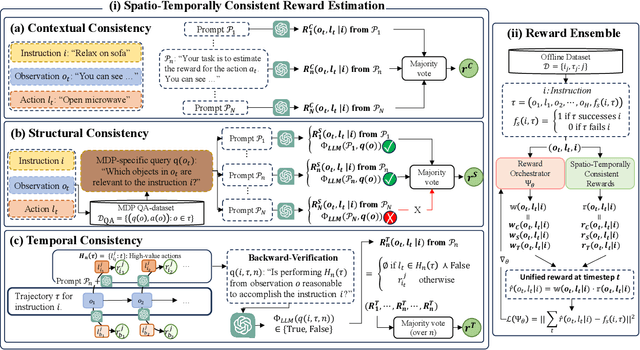
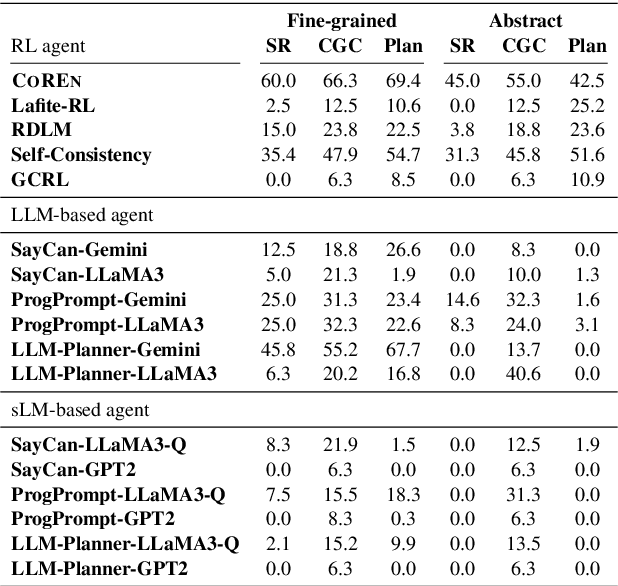
Employing large language models (LLMs) to enable embodied agents has become popular, yet it presents several limitations in practice. In this work, rather than using LLMs directly as agents, we explore their use as tools for embodied agent learning. Specifically, to train separate agents via offline reinforcement learning (RL), an LLM is used to provide dense reward feedback on individual actions in training datasets. In doing so, we present a consistency-guided reward ensemble framework (CoREN), designed for tackling difficulties in grounding LLM-generated estimates to the target environment domain. The framework employs an adaptive ensemble of spatio-temporally consistent rewards to derive domain-grounded rewards in the training datasets, thus enabling effective offline learning of embodied agents in different environment domains. Experiments with the VirtualHome benchmark demonstrate that CoREN significantly outperforms other offline RL agents, and it also achieves comparable performance to state-of-the-art LLM-based agents with 8B parameters, despite CoREN having only 117M parameters for the agent policy network and using LLMs only for training.
Semantic Skill Grounding for Embodied Instruction-Following in Cross-Domain Environments
Aug 02, 2024In embodied instruction-following (EIF), the integration of pretrained language models (LMs) as task planners emerges as a significant branch, where tasks are planned at the skill level by prompting LMs with pretrained skills and user instructions. However, grounding these pretrained skills in different domains remains challenging due to their intricate entanglement with the domain-specific knowledge. To address this challenge, we present a semantic skill grounding (SemGro) framework that leverages the hierarchical nature of semantic skills. SemGro recognizes the broad spectrum of these skills, ranging from short-horizon low-semantic skills that are universally applicable across domains to long-horizon rich-semantic skills that are highly specialized and tailored for particular domains. The framework employs an iterative skill decomposition approach, starting from the higher levels of semantic skill hierarchy and then moving downwards, so as to ground each planned skill to an executable level within the target domain. To do so, we use the reasoning capabilities of LMs for composing and decomposing semantic skills, as well as their multi-modal extension for assessing the skill feasibility in the target domain. Our experiments in the VirtualHome benchmark show the efficacy of SemGro in 300 cross-domain EIF scenarios.
One-shot Imitation in a Non-Stationary Environment via Multi-Modal Skill
Feb 13, 2024



One-shot imitation is to learn a new task from a single demonstration, yet it is a challenging problem to adopt it for complex tasks with the high domain diversity inherent in a non-stationary environment. To tackle the problem, we explore the compositionality of complex tasks, and present a novel skill-based imitation learning framework enabling one-shot imitation and zero-shot adaptation; from a single demonstration for a complex unseen task, a semantic skill sequence is inferred and then each skill in the sequence is converted into an action sequence optimized for environmental hidden dynamics that can vary over time. Specifically, we leverage a vision-language model to learn a semantic skill set from offline video datasets, where each skill is represented on the vision-language embedding space, and adapt meta-learning with dynamics inference to enable zero-shot skill adaptation. We evaluate our framework with various one-shot imitation scenarios for extended multi-stage Meta-world tasks, showing its superiority in learning complex tasks, generalizing to dynamics changes, and extending to different demonstration conditions and modalities, compared to other baselines.
SemTra: A Semantic Skill Translator for Cross-Domain Zero-Shot Policy Adaptation
Feb 12, 2024

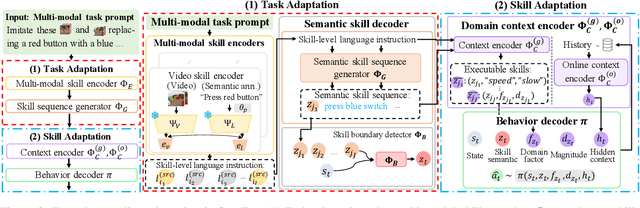

This work explores the zero-shot adaptation capability of semantic skills, semantically interpretable experts' behavior patterns, in cross-domain settings, where a user input in interleaved multi-modal snippets can prompt a new long-horizon task for different domains. In these cross-domain settings, we present a semantic skill translator framework SemTra which utilizes a set of multi-modal models to extract skills from the snippets, and leverages the reasoning capabilities of a pretrained language model to adapt these extracted skills to the target domain. The framework employs a two-level hierarchy for adaptation: task adaptation and skill adaptation. During task adaptation, seq-to-seq translation by the language model transforms the extracted skills into a semantic skill sequence, which is tailored to fit the cross-domain contexts. Skill adaptation focuses on optimizing each semantic skill for the target domain context, through parametric instantiations that are facilitated by language prompting and contrastive learning-based context inferences. This hierarchical adaptation empowers the framework to not only infer a complex task specification in one-shot from the interleaved multi-modal snippets, but also adapt it to new domains with zero-shot learning abilities. We evaluate our framework with Meta-World, Franka Kitchen, RLBench, and CARLA environments. The results clarify the framework's superiority in performing long-horizon tasks and adapting to different domains, showing its broad applicability in practical use cases, such as cognitive robots interpreting abstract instructions and autonomous vehicles operating under varied configurations.