 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Visual Integrated System for Tailored Automation in Math Problem Generation Using LLM
Nov 08, 2024



Generating accurate and consistent visual aids is a critical challenge in mathematics education, where visual representations like geometric shapes and functions play a pivotal role in enhancing student comprehension. This paper introduces a novel multi-agent framework that leverages Large Language Models (LLMs) to automate the creation of complex mathematical visualizations alongside coherent problem text. Our approach not only simplifies the generation of precise visual aids but also aligns these aids with the problem's core mathematical concepts, improving both problem creation and assessment. By integrating multiple agents, each responsible for distinct tasks such as numeric calculation, geometry validation, and visualization, our system delivers mathematically accurate and contextually relevant problems with visual aids. Evaluation across Geometry and Function problem types shows that our method significantly outperforms basic LLMs in terms of text coherence, consistency, relevance and similarity, while maintaining the essential geometrical and functional integrity of the original problems. Although some challenges remain in ensuring consistent visual outputs, our framework demonstrates the immense potential of LLMs in transforming the way educators generate and utilize visual aids in math education.
Post-hoc Utterance Refining Method by Entity Mining for Faithful Knowledge Grounded Conversations
Jun 16, 2024

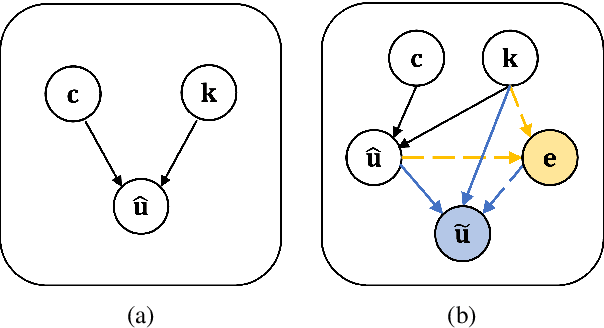
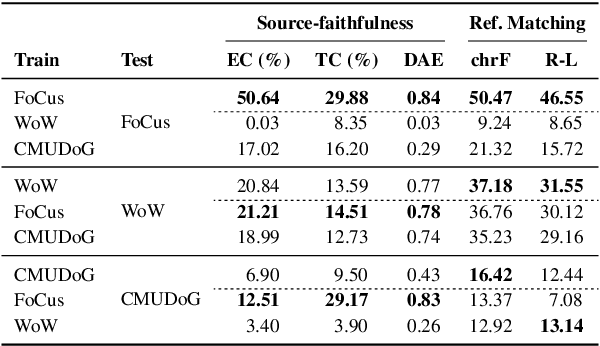
Despite the striking advances in recent language generation performance, model-generated responses have suffered from the chronic problem of hallucinations that are either untrue or unfaithful to a given source. Especially in the task of knowledge grounded conversation, the models are required to generate informative responses, but hallucinated utterances lead to miscommunication. In particular, entity-level hallucination that causes critical misinformation and undesirable conversation is one of the major concerns. To address this issue, we propose a post-hoc refinement method called REM. It aims to enhance the quality and faithfulness of hallucinated utterances by refining them based on the source knowledge. If the generated utterance has a low source-faithfulness score with the given knowledge, REM mines the key entities in the knowledge and implicitly uses them for refining the utterances. We verify that our method reduces entity hallucination in the utterance. Also, we show the adaptability and efficacy of REM with extensive experiments and generative results. Our code is available at https://github.com/YOONNAJANG/REM.
SemTra: A Semantic Skill Translator for Cross-Domain Zero-Shot Policy Adaptation
Feb 12, 2024

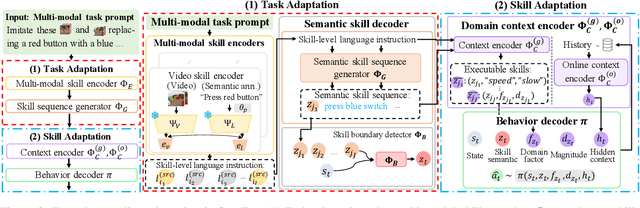

This work explores the zero-shot adaptation capability of semantic skills, semantically interpretable experts' behavior patterns, in cross-domain settings, where a user input in interleaved multi-modal snippets can prompt a new long-horizon task for different domains. In these cross-domain settings, we present a semantic skill translator framework SemTra which utilizes a set of multi-modal models to extract skills from the snippets, and leverages the reasoning capabilities of a pretrained language model to adapt these extracted skills to the target domain. The framework employs a two-level hierarchy for adaptation: task adaptation and skill adaptation. During task adaptation, seq-to-seq translation by the language model transforms the extracted skills into a semantic skill sequence, which is tailored to fit the cross-domain contexts. Skill adaptation focuses on optimizing each semantic skill for the target domain context, through parametric instantiations that are facilitated by language prompting and contrastive learning-based context inferences. This hierarchical adaptation empowers the framework to not only infer a complex task specification in one-shot from the interleaved multi-modal snippets, but also adapt it to new domains with zero-shot learning abilities. We evaluate our framework with Meta-World, Franka Kitchen, RLBench, and CARLA environments. The results clarify the framework's superiority in performing long-horizon tasks and adapting to different domains, showing its broad applicability in practical use cases, such as cognitive robots interpreting abstract instructions and autonomous vehicles operating under varied configurations.