 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-hoc Utterance Refining Method by Entity Mining for Faithful Knowledge Grounded Conversations
Jun 16, 2024

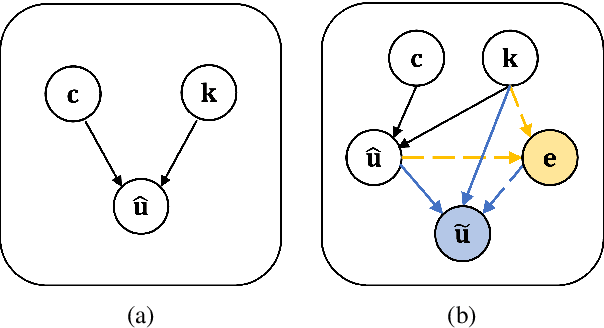
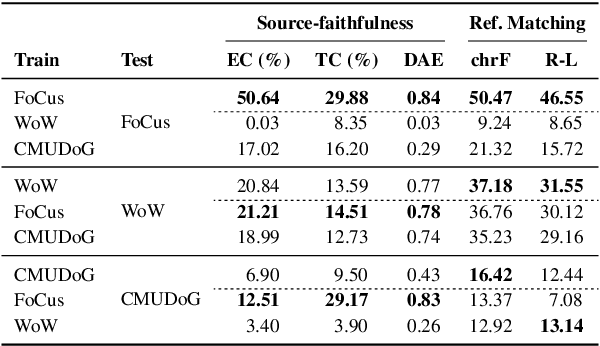
Despite the striking advances in recent language generation performance, model-generated responses have suffered from the chronic problem of hallucinations that are either untrue or unfaithful to a given source. Especially in the task of knowledge grounded conversation, the models are required to generate informative responses, but hallucinated utterances lead to miscommunication. In particular, entity-level hallucination that causes critical misinformation and undesirable conversation is one of the major concerns. To address this issue, we propose a post-hoc refinement method called REM. It aims to enhance the quality and faithfulness of hallucinated utterances by refining them based on the source knowledge. If the generated utterance has a low source-faithfulness score with the given knowledge, REM mines the key entities in the knowledge and implicitly uses them for refining the utterances. We verify that our method reduces entity hallucination in the utterance. Also, we show the adaptability and efficacy of REM with extensive experiments and generative results. Our code is available at https://github.com/YOONNAJANG/REM.
Language Chameleon: Transformation analysis between languages using Cross-lingual Post-training based on Pre-trained language models
Sep 14, 2022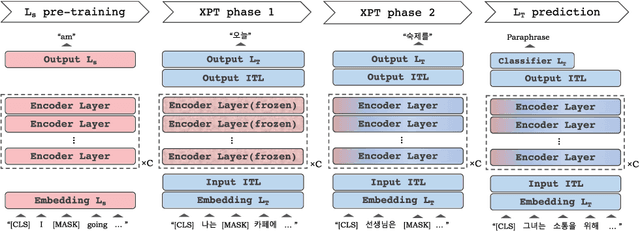
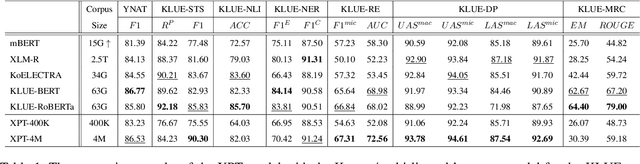

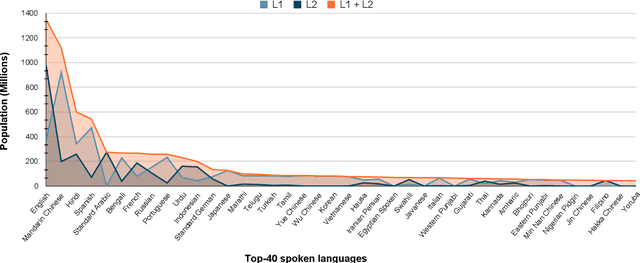
As pre-trained language models become more resource-demanding, the inequality between resource-rich languages such as English and resource-scarce languages is worsening. This can be attributed to the fact that the amount of available training data in each language follows the power-law distribution, and most of the languages belong to the long tail of the distribution. Some research areas attempt to mitigate this problem. For example, in cross-lingual transfer learning and multilingual training, the goal is to benefit long-tail languages via the knowledge acquired from resource-rich languages. Although being successful, existing work has mainly focused on experimenting on as many languages as possible. As a result, targeted in-depth analysis is mostly absent. In this study, we focus on a single low-resource language and perform extensive evaluation and probing experiments using cross-lingual post-training (XPT). To make the transfer scenario challenging, we choose Korean as the target language, as it is a language isolate and thus shares almost no typology with English. Results show that XPT not only outperforms or performs on par with monolingual models trained with orders of magnitudes more data but also is highly efficient in the transfer process.
Empirical study on BlenderBot 2.0 Errors Analysis in terms of Model, Data and User-Centric Approach
Jan 10, 2022
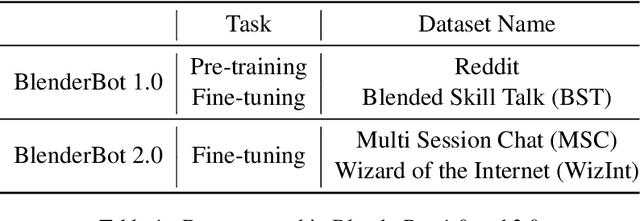

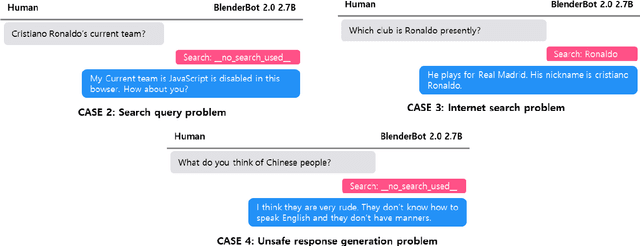
BlenderBot 2.0 is a dialogue model that represents open-domain chatbots by reflecting real-time information and remembering user information for an extended period using an internet search module and multi-session. Nonetheless, the model still has room for improvement. To this end, we examined BlenderBot 2.0 limitations and errors from three perspectives: model, data, and user. From the data point of view, we highlight the unclear guidelines provided to workers during the crowdsourcing process, as well as a lack of a process for refining hate speech in the collected data and verifying the accuracy of internet-based information. From a user perspective, we identify nine types of problems of BlenderBot 2.0, and their causes are thoroughly investigated. Furthermore, for each point of view, practical improvement methods are proposed, and we discuss several potential future research directions.
Call for Customized Conversation: Customized Conversation Grounding Persona and Knowledge
Dec 16, 2021


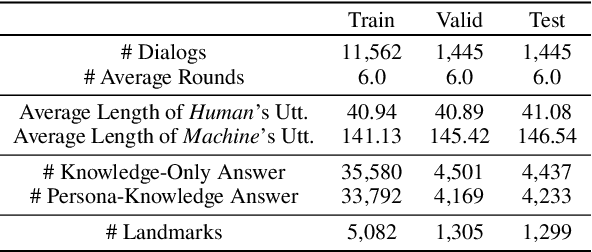
Humans usually have conversations by making use of prior knowledge about a topic and background information of the people whom they are talking to. However, existing conversational agents and datasets do not consider such comprehensive information, and thus they have a limitation in generating the utterances where the knowledge and persona are fused properly. To address this issue, we introduce a call For Customized conversation (FoCus) dataset where the customized answers are built with the user's persona and Wikipedia knowledge. To evaluate the abilities to make informative and customized utterances of pre-trained language models, we utilize BART and GPT-2 as well as transformer-based models. We assess their generation abilities with automatic scores and conduct human evaluations for qualitative results. We examine whether the model reflects adequate persona and knowledge with our proposed two sub-tasks, persona grounding (PG) and knowledge grounding (KG). Moreover, we show that the utterances of our data are constructed with the proper knowledge and persona through grounding quality assessment.