 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Optimization for Language Transfer in Large Language Models
May 20, 2025Adapting large language models to other languages typically employs supervised fine-tuning (SFT) as a standard approach. However, it often suffers from an overemphasis on English performance, a phenomenon that is especially pronounced in data-constrained environments. To overcome these challenges, we propose \textbf{Cross-Lingual Optimization (CLO)} that efficiently transfers an English-centric LLM to a target language while preserving its English capabilities. CLO utilizes publicly available English SFT data and a translation model to enable cross-lingual transfer. We conduct experiments using five models on six languages, each possessing varying levels of resource. Our results show that CLO consistently outperforms SFT in both acquiring target language proficiency and maintaining English performance. Remarkably, in low-resource languages, CLO with only 3,200 samples surpasses SFT with 6,400 samples, demonstrating that CLO can achieve better performance with less data. Furthermore, we find that SFT is particularly sensitive to data quantity in medium and low-resource languages, whereas CLO remains robust. Our comprehensive analysis emphasizes the limitations of SFT and incorporates additional training strategies in CLO to enhance efficiency.
QUAK: A Synthetic Quality Estimation Dataset for Korean-English Neural Machine Translation
Sep 30, 2022
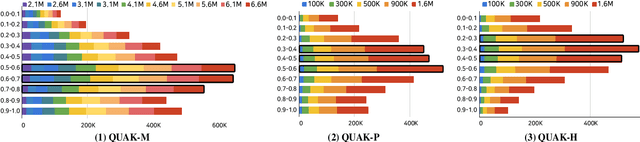
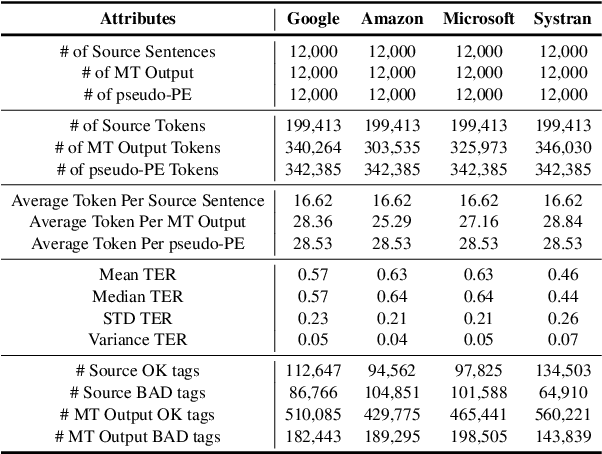
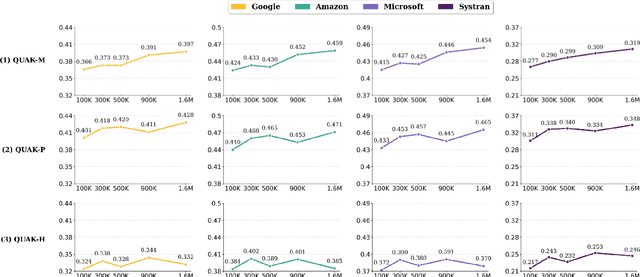
With the recent advance in neural machine translation demonstrating its importance, research on quality estimation (QE) has been steadily progressing. QE aims to automatically predict the quality of machine translation (MT) output without reference sentences. Despite its high utility in the real world, there remain several limitations concerning manual QE data creation: inevitably incurred non-trivial costs due to the need for translation experts, and issues with data scaling and language expansion. To tackle these limitations, we present QUAK, a Korean-English synthetic QE dataset generated in a fully automatic manner. This consists of three sub-QUAK datasets QUAK-M, QUAK-P, and QUAK-H, produced through three strategies that are relatively free from language constraints. Since each strategy requires no human effort, which facilitates scalability, we scale our data up to 1.58M for QUAK-P, H and 6.58M for QUAK-M. As an experiment, we quantitatively analyze word-level QE results in various ways while performing statistical analysis. Moreover, we show that datasets scaled in an efficient way also contribute to performance improvements by observing meaningful performance gains in QUAK-M, P when adding data up to 1.58M.
Language Chameleon: Transformation analysis between languages using Cross-lingual Post-training based on Pre-trained language models
Sep 14, 2022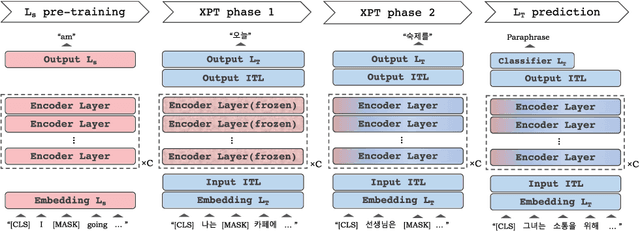
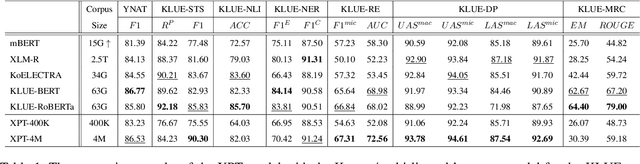

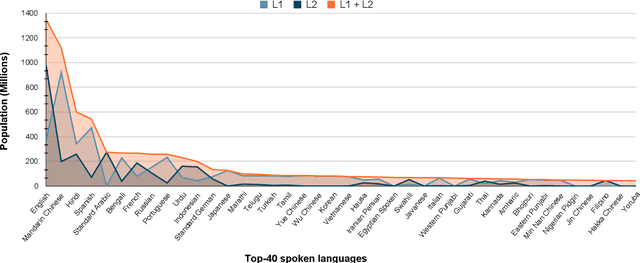
As pre-trained language models become more resource-demanding, the inequality between resource-rich languages such as English and resource-scarce languages is worsening. This can be attributed to the fact that the amount of available training data in each language follows the power-law distribution, and most of the languages belong to the long tail of the distribution. Some research areas attempt to mitigate this problem. For example, in cross-lingual transfer learning and multilingual training, the goal is to benefit long-tail languages via the knowledge acquired from resource-rich languages. Although being successful, existing work has mainly focused on experimenting on as many languages as possible. As a result, targeted in-depth analysis is mostly absent. In this study, we focus on a single low-resource language and perform extensive evaluation and probing experiments using cross-lingual post-training (XPT). To make the transfer scenario challenging, we choose Korean as the target language, as it is a language isolate and thus shares almost no typology with English. Results show that XPT not only outperforms or performs on par with monolingual models trained with orders of magnitudes more data but also is highly efficient in the transfer process.
Empirical study on BlenderBot 2.0 Errors Analysis in terms of Model, Data and User-Centric Approach
Jan 10, 2022
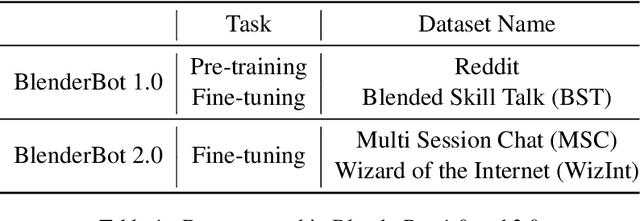

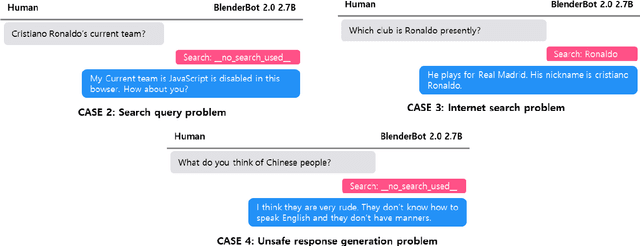
BlenderBot 2.0 is a dialogue model that represents open-domain chatbots by reflecting real-time information and remembering user information for an extended period using an internet search module and multi-session. Nonetheless, the model still has room for improvement. To this end, we examined BlenderBot 2.0 limitations and errors from three perspectives: model, data, and user. From the data point of view, we highlight the unclear guidelines provided to workers during the crowdsourcing process, as well as a lack of a process for refining hate speech in the collected data and verifying the accuracy of internet-based information. From a user perspective, we identify nine types of problems of BlenderBot 2.0, and their causes are thoroughly investigated. Furthermore, for each point of view, practical improvement methods are proposed, and we discuss several potential future research directions.