 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGORA: Orchestrated Argumentation for Causally Grounded LLM Reasoning and Decision Making
Jan 29, 2026Existing multi-expert LLM systems gather diverse perspectives but combine them through simple aggregation, obscuring which arguments drove the final decision. We introduce ARGORA, a framework that organizes multi-expert discussions into explicit argumentation graphs showing which arguments support or attack each other. By casting these graphs as causal models, ARGORA can systematically remove individual arguments and recompute outcomes, identifying which reasoning chains were necessary and whether decisions would change under targeted modifications. We further introduce a correction mechanism that aligns internal reasoning with external judgments when they disagree. Across diverse benchmarks and an open-ended use case, ARGORA achieves competitive accuracy and demonstrates corrective behavior: when experts initially disagree, the framework resolves disputes toward correct answers more often than it introduces new errors, while providing causal diagnostics of decisive arguments.
Personalizing Large Language Models using Retrieval Augmented Generation and Knowledge Graph
May 15, 2025The advent of large language models (LLMs) has allowed numerous applications, including the generation of queried responses, to be leveraged in chatbots and other conversational assistants. Being trained on a plethora of data, LLMs often undergo high levels of over-fitting, resulting in the generation of extra and incorrect data, thus causing hallucinations in output generation. One of the root causes of such problems is the lack of timely, factual, and personalized information fed to the LLM. In this paper, we propose an approach to address these problems by introducing retrieval augmented generation (RAG) using knowledge graphs (KGs) to assist the LLM in personalized response generation tailored to the users. KGs have the advantage of storing continuously updated factual information in a structured way. While our KGs can be used for a variety of frequently updated personal data, such as calendar, contact, and location data, we focus on calendar data in this paper. Our experimental results show that our approach works significantly better in understanding personal information and generating accurate responses compared to the baseline LLMs using personal data as text inputs, with a moderate reduction in response time.
CUE-M: Contextual Understanding and Enhanced Search with Multimodal Large Language Model
Nov 19, 2024
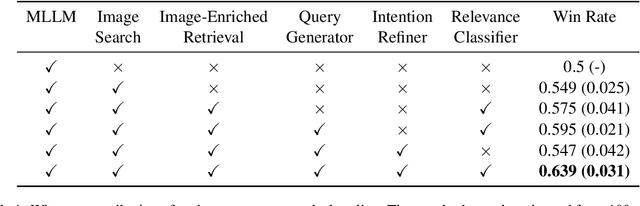
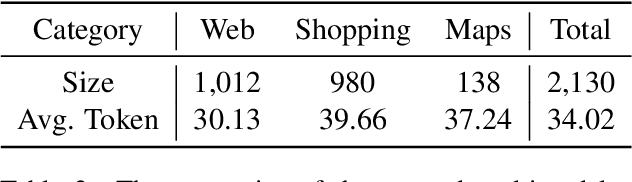
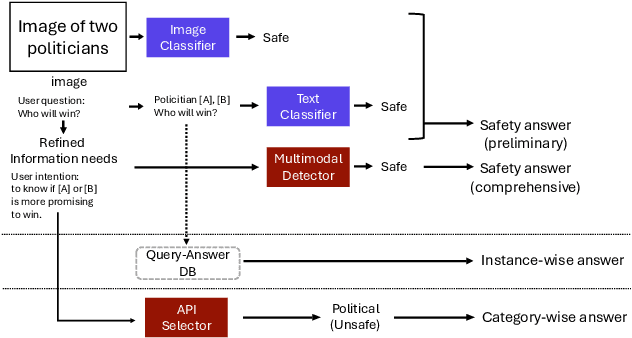
The integration of Retrieval-Augmented Generation (RAG) with Multimodal Large Language Models (MLLMs) has expanded the scope of multimodal query resolution. However, current systems struggle with intent understanding, information retrieval, and safety filtering, limiting their effectiveness. This paper introduces Contextual Understanding and Enhanced Search with MLLM (CUE-M), a novel multimodal search pipeline that addresses these challenges through a multi-stage framework comprising image context enrichment, intent refinement, contextual query generation, external API integration, and relevance-based filtering. CUE-M incorporates a robust safety framework combining image-based, text-based, and multimodal classifiers, dynamically adapting to instance- and category-specific risks. Evaluations on a multimodal Q&A dataset and a public safety benchmark demonstrate that CUE-M outperforms baselines in accuracy, knowledge integration, and safety, advancing the capabilities of multimodal retrieval systems.
Towards Reliable and Fluent Large Language Models: Incorporating Feedback Learning Loops in QA Systems
Sep 08, 2023Large language models (LLMs) have emerged as versatile tools in various daily applications. However, they are fraught with issues that undermine their utility and trustworthiness. These include the incorporation of erroneous references (citation), the generation of hallucinated information (correctness), and the inclusion of superfluous or omission of crucial details (fluency). To ameliorate these concerns, this study makes several key contributions. First, we build a dataset to train a critic model capable of evaluating the citation, correctness, and fluency of responses generated by LLMs in QA systems. Second, we propose an automated feedback mechanism that leverages the critic model to offer real-time feedback on heterogeneous aspects of generated text. Third, we introduce a feedback learning loop that uses this critic model to iteratively improve the performance of the LLM responsible for response generation. Experimental results demonstrate the efficacy of our approach, showing substantial improvements in citation and fluency metrics for ChatGPT, including a 4% precision increase in citation and an approximately 8% enhancement in the MAUVE metric for fluency, while maintaining high levels of correctness.
Analysis of Utterance Embeddings and Clustering Methods Related to Intent Induction for Task-Oriented Dialogue
Dec 06, 2022

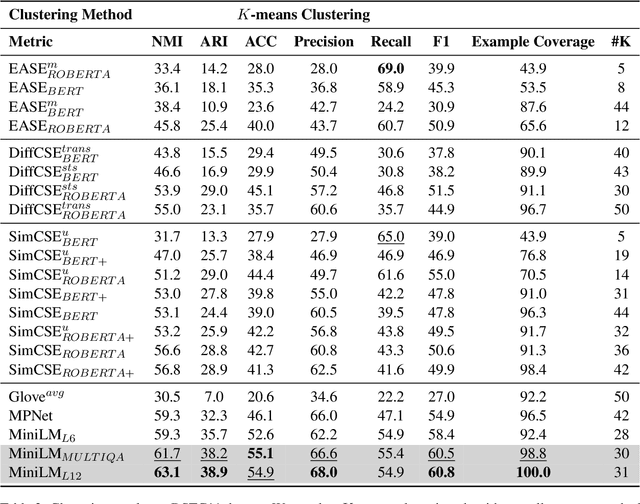

This paper investigates unsupervised approaches to overcome quintessential challenges in designing task-oriented dialog schema: assigning intent labels to each dialog turn (intent clustering) and generating a set of intents based on the intent clustering methods (intent induction). We postulate there are two salient factors for automatic induction of intents: (1) clustering algorithm for intent labeling and (2) user utterance embedding space. We compare existing off-the-shelf clustering models and embeddings based on DSTC11 evaluation. Our extensive experiments demonstrate that we sholud add two huge caveat that selection of utterance embedding and clustering method in intent induction task should be very careful. We also present that pretrained MiniLM with Agglomerative clustering shows significant improvement in NMI, ARI, F1, accuracy and example coverage in intent induction tasks. The source code for reimplementation will be available at Github.
Language Chameleon: Transformation analysis between languages using Cross-lingual Post-training based on Pre-trained language models
Sep 14, 2022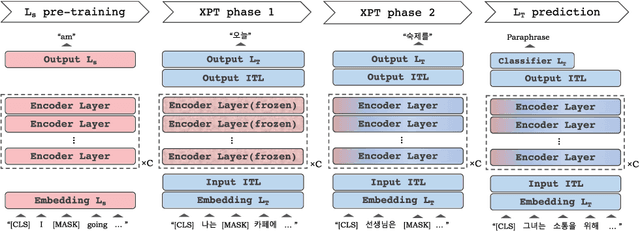
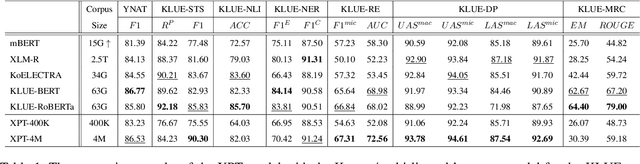

As pre-trained language models become more resource-demanding, the inequality between resource-rich languages such as English and resource-scarce languages is worsening. This can be attributed to the fact that the amount of available training data in each language follows the power-law distribution, and most of the languages belong to the long tail of the distribution. Some research areas attempt to mitigate this problem. For example, in cross-lingual transfer learning and multilingual training, the goal is to benefit long-tail languages via the knowledge acquired from resource-rich languages. Although being successful, existing work has mainly focused on experimenting on as many languages as possible. As a result, targeted in-depth analysis is mostly absent. In this study, we focus on a single low-resource language and perform extensive evaluation and probing experiments using cross-lingual post-training (XPT). To make the transfer scenario challenging, we choose Korean as the target language, as it is a language isolate and thus shares almost no typology with English. Results show that XPT not only outperforms or performs on par with monolingual models trained with orders of magnitudes more data but also is highly efficient in the transfer process.
Multimodal Frame-Scoring Transformer for Video Summarization
Jul 05, 2022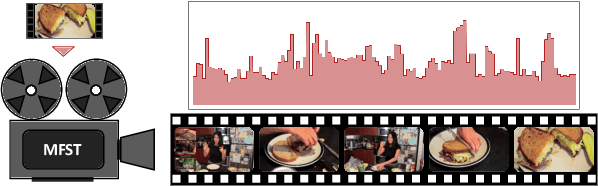
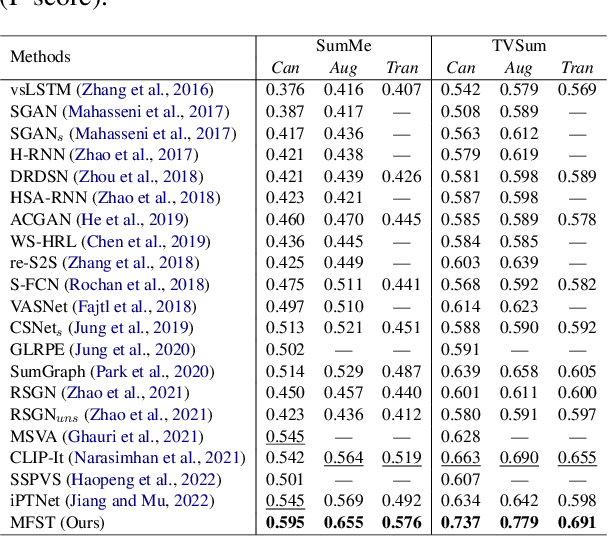
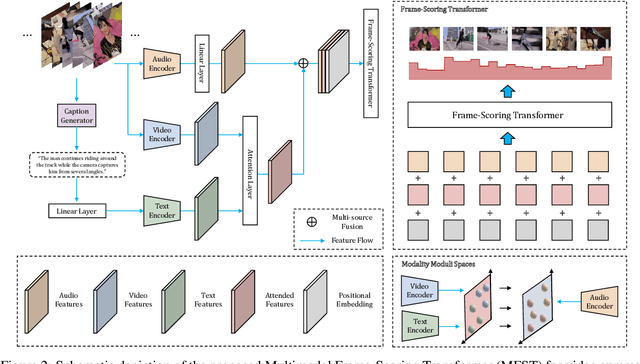
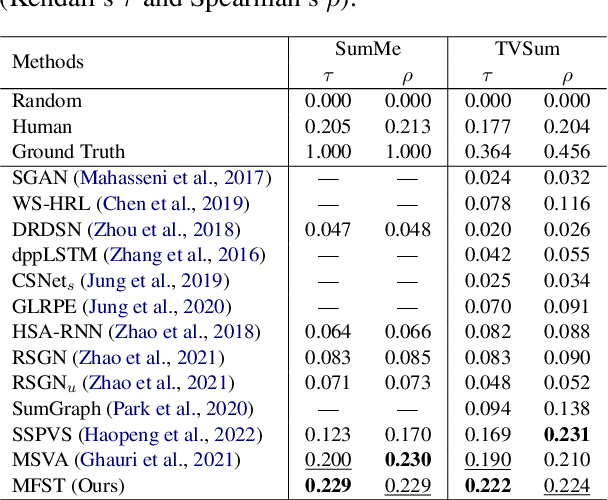
As the number of video content has mushroomed in recent years, automatic video summarization has come useful when we want to just peek at the content of the video. However, there are two underlying limitations in generic video summarization task. First, most previous approaches read in just visual features as input, leaving other modality features behind. Second, existing datasets for generic video summarization are relatively insufficient to train a caption generator and multimodal feature extractors. To address these two problems, this paper proposes the Multimodal Frame-Scoring Transformer (MFST) framework exploiting visual, text and audio features and scoring a video with respect to frames. Our MFST framework first extracts each modality features (visual-text-audio) using pretrained encoders. Then, MFST trains the multimodal frame-scoring transformer that uses video-text-audio representations as inputs and predicts frame-level scores. Our extensive experiments with previous models and ablation studies on TVSum and SumMe datasets demonstrate the effectiveness and superiority of our proposed method.
Do Response Selection Models Really Know What's Next? Utterance Manipulation Strategies for Multi-turn Response Selection
Sep 10, 2020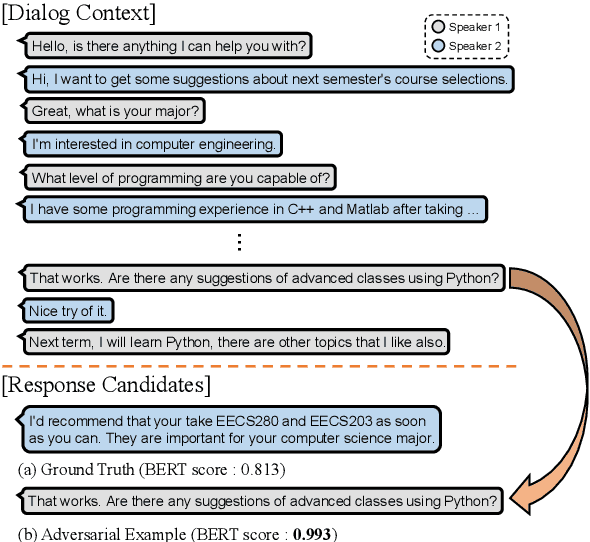

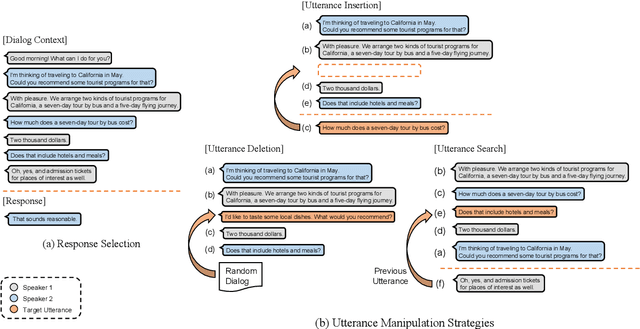
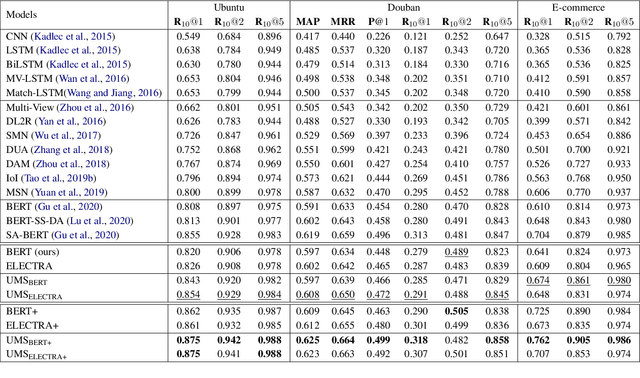
In this paper, we study the task of selecting optimal response given user and system utterance history in retrieval-based multi-turn dialog systems. Recently, pre-trained language models (e.g., BERT, RoBERTa, and ELECTRA) have shown significant improvements in various natural language processing tasks. This and similar response selection tasks can also be solved using such language models by formulating them as dialog-response binary classification tasks. Although existing works using this approach successfully obtained state-of-the-art results, we observe that language models trained in this manner tend to make predictions based on the relatedness of history and candidates, ignoring the sequential nature of multi-turn dialog systems. This suggests that the response selection task alone is insufficient in learning temporal dependencies between utterances. To this end, we propose utterance manipulation strategies (UMS) to address this problem. Specifically, UMS consist of several strategies (i.e., insertion, deletion, and search), which aid the response selection model towards maintaining dialog coherence. Further, UMS are self-supervised methods that do not require additional annotation and thus can be easily incorporated into existing approaches. Extensive evaluation across multiple languages and models shows that UMS are highly effective in teaching dialog consistency, which lead to models pushing the state-of-the-art with significant margins on multiple public benchmark datasets.
Variational Reward Estimator Bottleneck: Learning Robust Reward Estimator for Multi-Domain Task-Oriented Dialog
May 31, 2020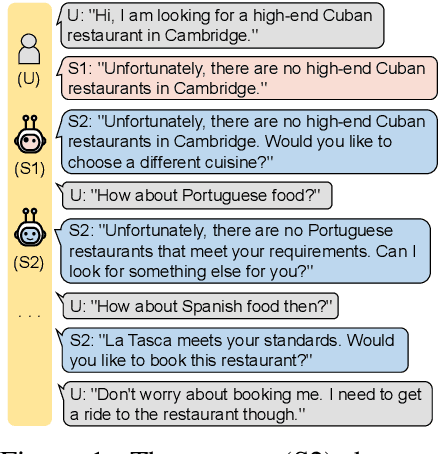
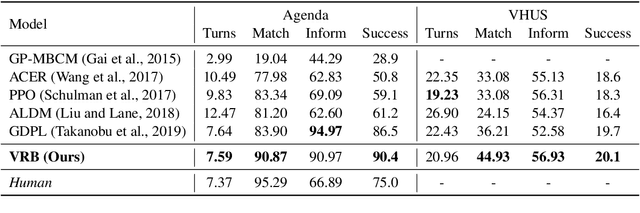
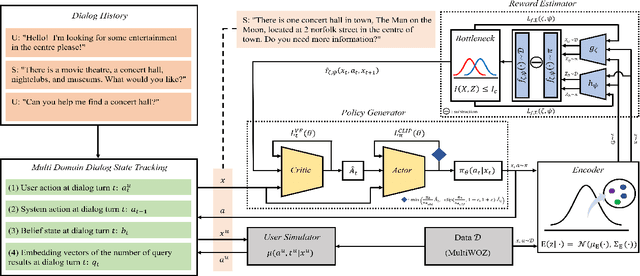
Despite its notable success in adversarial learning approaches to multi-domain task-oriented dialog system, training the dialog policy via adversarial inverse reinforcement learning often fails to balance the performance of the policy generator and reward estimator. During optimization, the reward estimator often overwhelms the policy generator and produces excessively uninformative gradients. We proposes the Variational Reward estimator Bottleneck (VRB), which is an effective regularization method that aims to constrain unproductive information flows between inputs and the reward estimator. The VRB focuses on capturing discriminative features, by exploiting information bottleneck on mutual information. Empirical results on a multi-domain task-oriented dialog dataset demonstrate that the VRB significantly outperforms previous methods.
Domain Adaptive Training BERT for Response Selection
Aug 13, 2019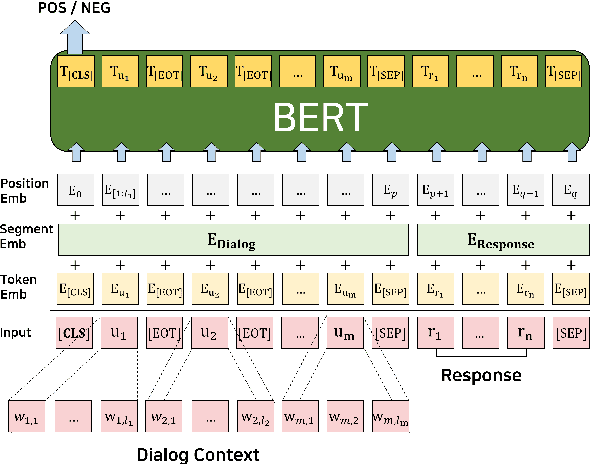
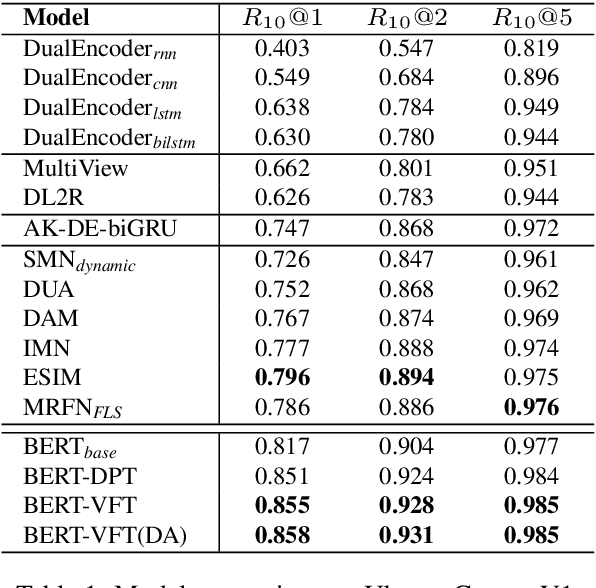
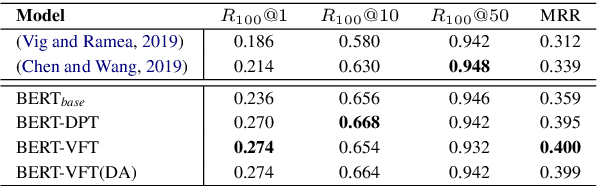
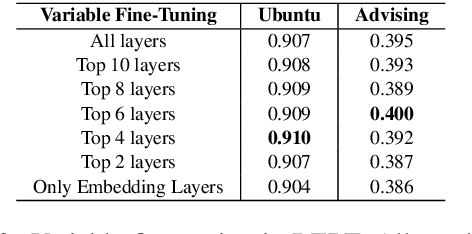
We focus on multi-turn response selection in a retrieval-based dialog system. In this paper, we utilize the powerful pre-trained language model Bi-directional Encoder Representations from Transformer (BERT) for a multi-turn dialog system and propose a highly effective post-training method on domain-specific corpus. Although BERT is easily adopted to various NLP tasks and outperforms previous baselines of each task, it still has limitations if a task corpus is too focused on a certain domain. Post-training on domain-specific corpus (e.g., Ubuntu Corpus) helps the model to train contextualized representations and words that do not appear in general corpus (e.g.,English Wikipedia). Experiment results show that our approach achieves new state-of-the-art on two response selection benchmark datasets (i.e.,Ubuntu Corpus V1, Advising Corpus) performance improvement by 5.9% and 6% on Recall@1.