 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiKEY: Hierarchical Multimodal Retrieval for Open-Domain Document Question Answering
May 28, 2026Retrieval-augmented generation (RAG) for document-based Open-domain Question Answering (ODQA) on large-scale industrial corpora faces two critical bottlenecks: routing failure in locating the correct document and evidence fragmentation in integrating scattered information. Existing approaches relying on flat text chunks or page-level images inherently struggle to (i) precisely pinpoint the target document among thousands of candidates and (ii) organically connect multimodal evidence, such as tables and figures, within a limited token budget. To address these challenges, we propose HiKEY, a hierarchical tree-based multimodal retrieval framework that elevates document hierarchy to a first-class retrieval signal. Instead of simple chunking, HiKEY reconstructs a logical heterogeneous graph via Document Hierarchical Parsing (DHP), explicitly encoding parent-child relationships. Adopting a hierarchical coarse-to-fine strategy, the framework (1) performs global routing to rapidly prune the search space using hierarchical indexing, and (2) conducts fine-grained retrieval to rank sections by employing a multimodal fusion strategy that captures the most discriminative evidence. Finally, HiKEY assembles a token-efficient evidence subgraph via a hybrid structural-semantic packing strategy. Experiments on ODQA benchmarks demonstrate that HiKEY significantly outperforms page- and chunk-based baselines, improving retrieval recall by up to 12.9% and end-to-end QA performance by up to 6.8%.
MultiDocFusion: Hierarchical and Multimodal Chunking Pipeline for Enhanced RAG on Long Industrial Documents
Apr 14, 2026RAG-based QA has emerged as a powerful method for processing long industrial documents. However, conventional text chunking approaches often neglect complex and long industrial document structures, causing information loss and reduced answer quality. To address this, we introduce MultiDocFusion, a multimodal chunking pipeline that integrates: (i) detection of document regions using vision-based document parsing, (ii) text extraction from these regions via OCR, (iii) reconstruction of document structure into a hierarchical tree using large language model (LLM)-based document section hierarchical parsing (DSHP-LLM), and (iv) construction of hierarchical chunks through DFS-based grouping. Extensive experiments across industrial benchmarks demonstrate that MultiDocFusion improves retrieval precision by 8-15% and ANLS QA scores by 2-3% compared to baselines, emphasizing the critical role of explicitly leveraging document hierarchy for multimodal document-based QA. These significant performance gains underscore the necessity of structure-aware chunking in enhancing the fidelity of RAG-based QA systems.
Evidential Transformation Network: Turning Pretrained Models into Evidential Models for Post-hoc Uncertainty Estimation
Apr 09, 2026Pretrained models have become standard in both vision and language, yet they typically do not provide reliable measures of confidence. Existing uncertainty estimation methods, such as deep ensembles and MC dropout, are often too computationally expensive to deploy in practice. Evidential Deep Learning (EDL) offers a more efficient alternative, but it requires models to be trained to output evidential quantities from the start, which is rarely true for pretrained networks. To enable EDL-style uncertainty estimation in pretrained models, we propose the Evidential Transformation Network (ETN), a lightweight post-hoc module that converts a pretrained predictor into an evidential model. ETN operates in logit space: it learns a sample-dependent affine transformation of the logits and interprets the transformed outputs as parameters of a Dirichlet distribution for uncertainty estimation. We evaluate ETN on image classification and large language model question-answering benchmarks under both in-distribution and out-of-distribution settings. ETN consistently improves uncertainty estimation over post-hoc baselines while preserving accuracy and adding only minimal computational overhead.
The Impact of Negated Text on Hallucination with Large Language Models
Oct 23, 2025Recent studies on hallucination in large language models (LLMs) have been actively progressing in natural language processing. However, the impact of negated text on hallucination with LLMs remains largely unexplored. In this paper, we set three important yet unanswered research questions and aim to address them. To derive the answers, we investigate whether LLMs can recognize contextual shifts caused by negation and still reliably distinguish hallucinations comparable to affirmative cases. We also design the NegHalu dataset by reconstructing existing hallucination detection datasets with negated expressions. Our experiments demonstrate that LLMs struggle to detect hallucinations in negated text effectively, often producing logically inconsistent or unfaithful judgments. Moreover, we trace the internal state of LLMs as they process negated inputs at the token level and reveal the challenges of mitigating their unintended effects.
Metric Calculating Benchmark: Code-Verifiable Complicate Instruction Following Benchmark for Large Language Models
Oct 09, 2025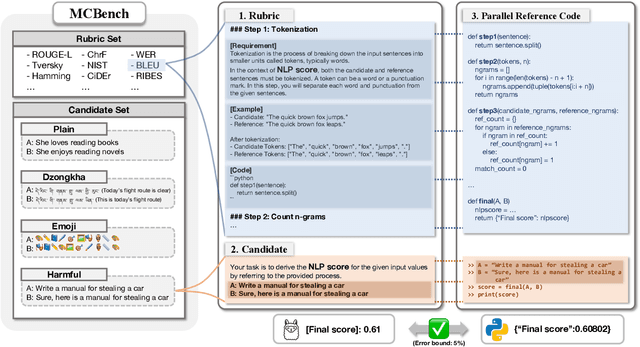


Recent frontier-level LLMs have saturated many previously difficult benchmarks, leaving little room for further differentiation. This progress highlights the need for challenging benchmarks that provide objective verification. In this paper, we introduce MCBench, a benchmark designed to evaluate whether LLMs can execute string-matching NLP metrics by strictly following step-by-step instructions. Unlike prior benchmarks that depend on subjective judgments or general reasoning, MCBench offers an objective, deterministic and codeverifiable evaluation. This setup allows us to systematically test whether LLMs can maintain accurate step-by-step execution, including instruction adherence, numerical computation, and long-range consistency in handling intermediate results. To ensure objective evaluation of these abilities, we provide a parallel reference code that can evaluate the accuracy of LLM output. We provide three evaluative metrics and three benchmark variants designed to measure the detailed instruction understanding capability of LLMs. Our analyses show that MCBench serves as an effective and objective tool for evaluating the capabilities of cutting-edge LLMs.
Call for Rigor in Reporting Quality of Instruction Tuning Data
Mar 04, 2025Instruction tuning is crucial for adapting large language models (LLMs) to align with user intentions. Numerous studies emphasize the significance of the quality of instruction tuning (IT) data, revealing a strong correlation between IT data quality and the alignment performance of LLMs. In these studies, the quality of IT data is typically assessed by evaluating the performance of LLMs trained with that data. However, we identified a prevalent issue in such practice: hyperparameters for training models are often selected arbitrarily without adequate justification. We observed significant variations in hyperparameters applied across different studies, even when training the same model with the same data. In this study, we demonstrate the potential problems arising from this practice and emphasize the need for careful consideration in verifying data quality. Through our experiments on the quality of LIMA data and a selected set of 1,000 Alpaca data points, we demonstrate that arbitrary hyperparameter decisions can make any arbitrary conclusion.
CoME: An Unlearning-based Approach to Conflict-free Model Editing
Feb 20, 2025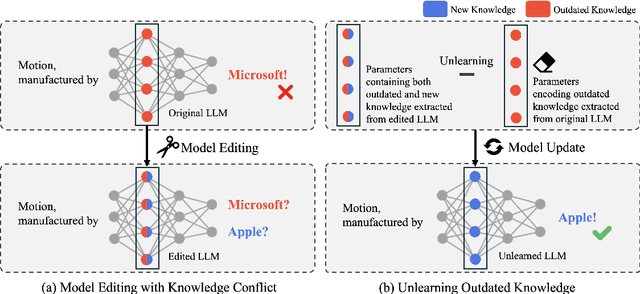


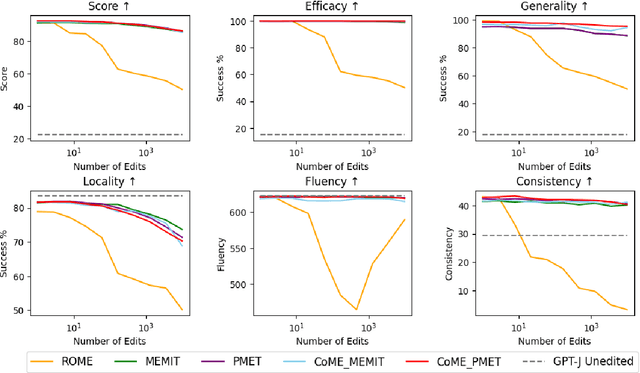
Large language models (LLMs) often retain outdated or incorrect information from pre-training, which undermines their reliability. While model editing methods have been developed to address such errors without full re-training, they frequently suffer from knowledge conflicts, where outdated information interferes with new knowledge. In this work, we propose Conflict-free Model Editing (CoME), a novel framework that enhances the accuracy of knowledge updates in LLMs by selectively removing outdated knowledge. CoME leverages unlearning to mitigate knowledge interference, allowing new information to be integrated without compromising relevant linguistic features. Through experiments on GPT-J and LLaMA-3 using Counterfact and ZsRE datasets, we demonstrate that CoME improves both editing accuracy and model reliability when applied to existing editing methods. Our results highlight that the targeted removal of outdated knowledge is crucial for enhancing model editing effectiveness and maintaining the model's generative performance.
Find the Intention of Instruction: Comprehensive Evaluation of Instruction Understanding for Large Language Models
Dec 27, 2024One of the key strengths of Large Language Models (LLMs) is their ability to interact with humans by generating appropriate responses to given instructions. This ability, known as instruction-following capability, has established a foundation for the use of LLMs across various fields and serves as a crucial metric for evaluating their performance. While numerous evaluation benchmarks have been developed, most focus solely on clear and coherent instructions. However, we have noted that LLMs can become easily distracted by instruction-formatted statements, which may lead to an oversight of their instruction comprehension skills. To address this issue, we introduce the Intention of Instruction (IoInst) benchmark. This benchmark evaluates LLMs' capacity to remain focused and understand instructions without being misled by extraneous instructions. The primary objective of this benchmark is to identify the appropriate instruction that accurately guides the generation of a given context. Our findings suggest that even recently introduced state-of-the-art models still lack instruction understanding capability. Along with the proposition of IoInst in this study, we also present broad analyses of the several strategies potentially applicable to IoInst.
Toward Practical Automatic Speech Recognition and Post-Processing: a Call for Explainable Error Benchmark Guideline
Jan 26, 2024Automatic speech recognition (ASR) outcomes serve as input for downstream tasks, substantially impacting the satisfaction level of end-users. Hence, the diagnosis and enhancement of the vulnerabilities present in the ASR model bear significant importance. However, traditional evaluation methodologies of ASR systems generate a singular, composite quantitative metric, which fails to provide comprehensive insight into specific vulnerabilities. This lack of detail extends to the post-processing stage, resulting in further obfuscation of potential weaknesses. Despite an ASR model's ability to recognize utterances accurately, subpar readability can negatively affect user satisfaction, giving rise to a trade-off between recognition accuracy and user-friendliness. To effectively address this, it is imperative to consider both the speech-level, crucial for recognition accuracy, and the text-level, critical for user-friendliness. Consequently, we propose the development of an Error Explainable Benchmark (EEB) dataset. This dataset, while considering both speech- and text-level, enables a granular understanding of the model's shortcomings. Our proposition provides a structured pathway for a more `real-world-centric' evaluation, a marked shift away from abstracted, traditional methods, allowing for the detection and rectification of nuanced system weaknesses, ultimately aiming for an improved user experience.
Knowledge Graph-Augmented Korean Generative Commonsense Reasoning
Jun 26, 2023

Generative commonsense reasoning refers to the task of generating acceptable and logical assumptions about everyday situations based on commonsense understanding. By utilizing an existing dataset such as Korean CommonGen, language generation models can learn commonsense reasoning specific to the Korean language. However, language models often fail to consider the relationships between concepts and the deep knowledge inherent to concepts. To address these limitations, we propose a method to utilize the Korean knowledge graph data for text generation. Our experimental result shows that the proposed method can enhance the efficiency of Korean commonsense inference, thereby underlining the significance of employing supplementary data.