 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAESIL: Masked Autoencoder for Enhanced Self-supervised Medical Image Learning
Apr 01, 2026Training deep learning models for three-dimensional (3D) medical imaging, such as Computed Tomography (CT), is fundamentally challenged by the scarcity of labeled data. While pre-training on natural images is common, it results in a significant domain shift, limiting performance. Self-Supervised Learning (SSL) on unlabeled medical data has emerged as a powerful solution, but prominent frameworks often fail to exploit the inherent 3D nature of CT scans. These methods typically process 3D scans as a collection of independent 2D slices, an approach that fundamentally discards critical axial coherence and the 3D structural context. To address this limitation, we propose the autoencoder for enhanced self-supervised medical image learning(MAESIL), a novel self-supervised learning framework designed to capture 3D structural information efficiently. The core innovation is the 'superpatch', a 3D chunk-based input unit that balances 3D context preservation with computational efficiency. Our framework partitions the volume into superpatches and employs a 3D masked autoencoder strategy with a dual-masking strategy to learn comprehensive spatial representations. We validated our approach on three diverse large-scale public CT datasets. Our experimental results show that MAESIL demonstrates significant improvements over existing methods such as AE, VAE and VQ-VAE in key reconstruction metrics such as PSNR and SSIM. This establishes MAESIL as a robust and practical pre-training solution for 3D medical imaging tasks.
3D-LLDM: Label-Guided 3D Latent Diffusion Model for Improving High-Resolution Synthetic MR Imaging in Hepatic Structure Segmentation
Mar 25, 2026Deep learning and generative models are advancing rapidly, with synthetic data increasingly being integrated into training pipelines for downstream analysis tasks. However, in medical imaging, their adoption remains constrained by the scarcity of reliable annotated datasets. To address this limitation, we propose 3D-LLDM, a label-guided 3D latent diffusion model that generates high-quality synthetic magnetic resonance (MR) volumes with corresponding anatomical segmentation masks. Our approach uses hepatobiliary phase MR images enhanced with the Gd-EOB-DTPA contrast agent to derive structural masks for the liver, portal vein, hepatic vein, and hepatocellular carcinoma, which then guide volumetric synthesis through a ControlNet-based architecture. Trained on 720 real clinical hepatobiliary phase MR scans from Samsung Medical Center, 3D-LLDM achieves a Fréchet Inception Distance (FID) of 28.31, improving over GANs by 70.9% and over state-of-the-art diffusion baselines by 26.7%. When used for data augmentation, the synthetic volumes improve hepatocellular carcinoma segmentation by up to 11.153% Dice score across five CNN architectures.
DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs
Sep 27, 2023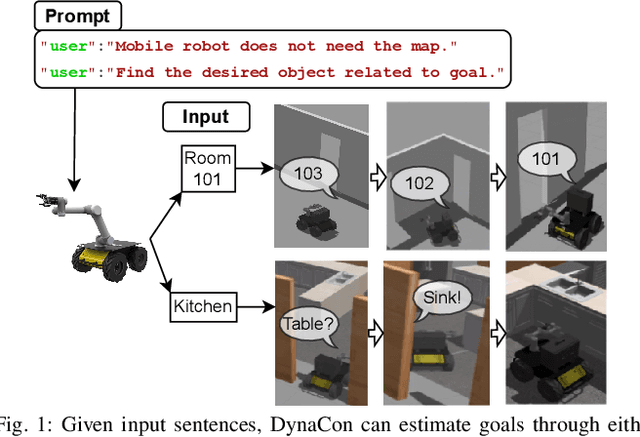
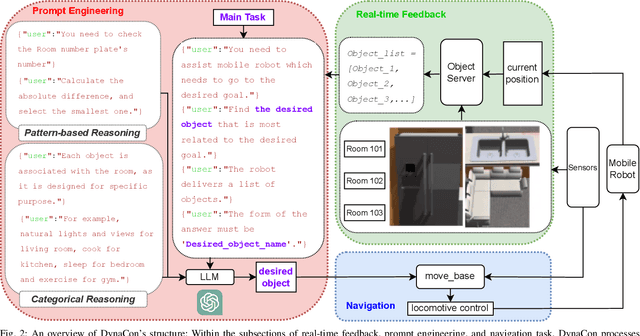
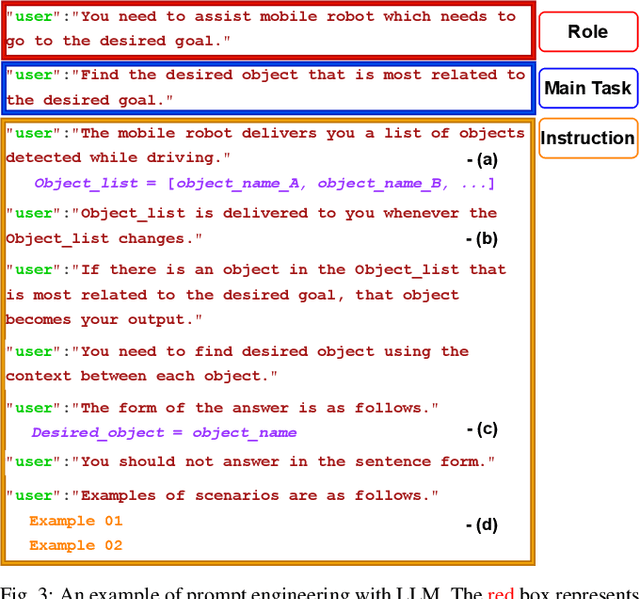
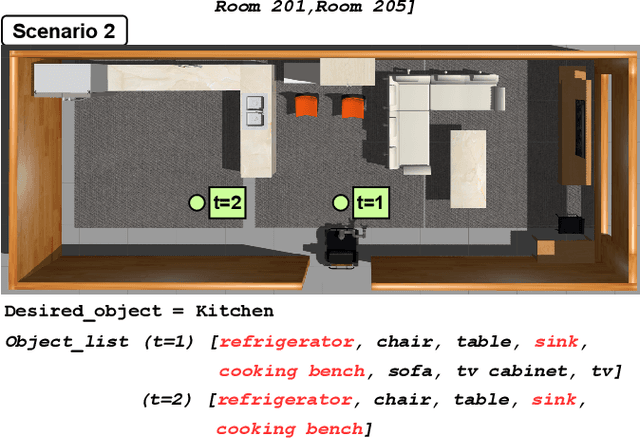
Mobile robots often rely on pre-existing maps for effective path planning and navigation. However, when these maps are unavailable, particularly in unfamiliar environments, a different approach become essential. This paper introduces DynaCon, a novel system designed to provide mobile robots with contextual awareness and dynamic adaptability during navigation, eliminating the reliance of traditional maps. DynaCon integrates real-time feedback with an object server, prompt engineering, and navigation modules. By harnessing the capabilities of Large Language Models (LLMs), DynaCon not only understands patterns within given numeric series but also excels at categorizing objects into matched spaces. This facilitates dynamic path planner imbued with contextual awareness. We validated the effectiveness of DynaCon through an experiment where a robot successfully navigated to its goal using reasoning. Source code and experiment videos for this work can be found at: https://sites.google.com/view/dynacon.
BIRP: Bitcoin Information Retrieval Prediction Model Based on Multimodal Pattern Matching
Aug 14, 2023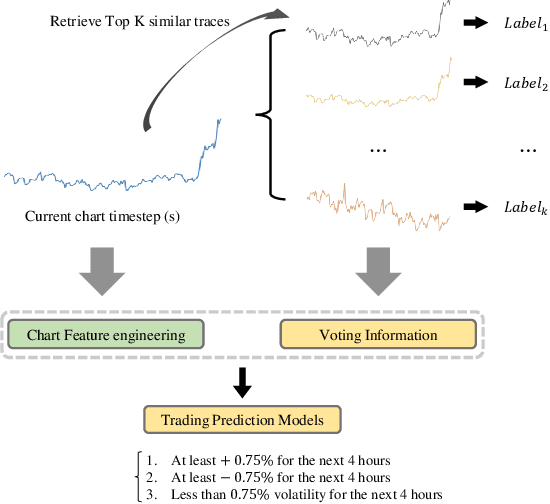
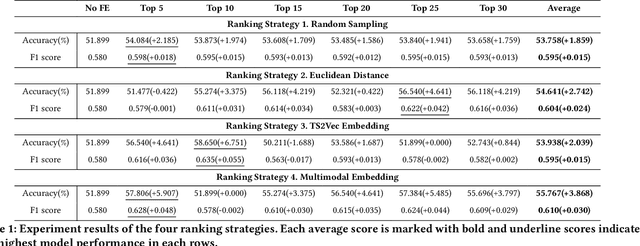
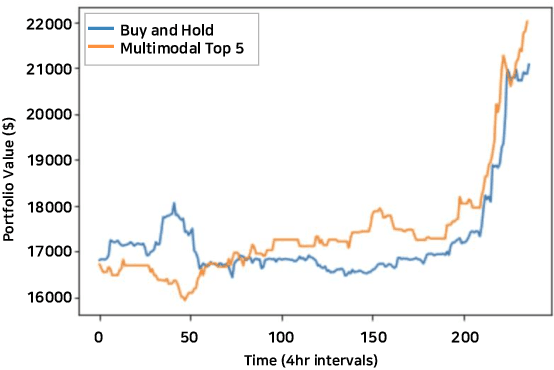
Financial time series have historically been assumed to be a martingale process under the Random Walk hypothesis. Instead of making investment decisions using the raw prices alone, various multimodal pattern matching algorithms have been developed to help detect subtly hidden repeatable patterns within the financial market. Many of the chart-based pattern matching tools only retrieve similar past chart (PC) patterns given the current chart (CC) pattern, and leaves the entire interpretive and predictive analysis, thus ultimately the final investment decision, to the investors. In this paper, we propose an approach of ranking similar PC movements given the CC information and show that exploiting this as additional features improves the directional prediction capacity of our model. We apply our ranking and directional prediction modeling methodologies on Bitcoin due to its highly volatile prices that make it challenging to predict its future movements.
QUAK: A Synthetic Quality Estimation Dataset for Korean-English Neural Machine Translation
Sep 30, 2022
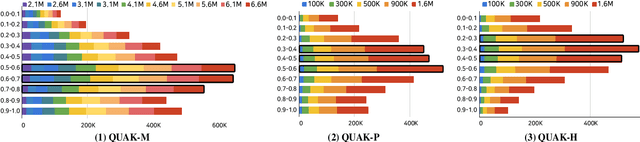
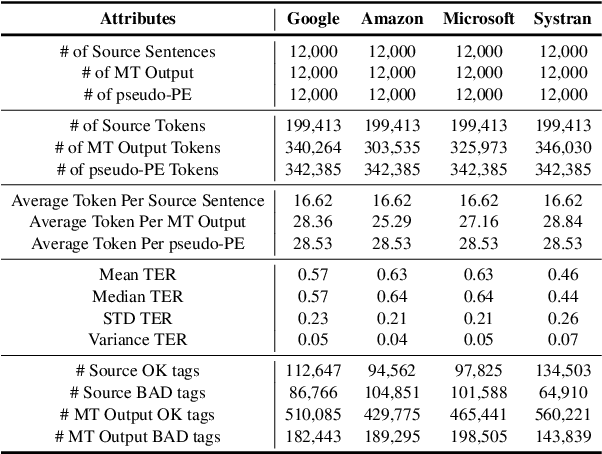
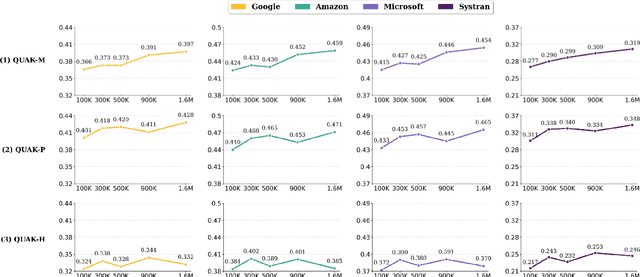
With the recent advance in neural machine translation demonstrating its importance, research on quality estimation (QE) has been steadily progressing. QE aims to automatically predict the quality of machine translation (MT) output without reference sentences. Despite its high utility in the real world, there remain several limitations concerning manual QE data creation: inevitably incurred non-trivial costs due to the need for translation experts, and issues with data scaling and language expansion. To tackle these limitations, we present QUAK, a Korean-English synthetic QE dataset generated in a fully automatic manner. This consists of three sub-QUAK datasets QUAK-M, QUAK-P, and QUAK-H, produced through three strategies that are relatively free from language constraints. Since each strategy requires no human effort, which facilitates scalability, we scale our data up to 1.58M for QUAK-P, H and 6.58M for QUAK-M. As an experiment, we quantitatively analyze word-level QE results in various ways while performing statistical analysis. Moreover, we show that datasets scaled in an efficient way also contribute to performance improvements by observing meaningful performance gains in QUAK-M, P when adding data up to 1.58M.