 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning
Mar 10, 2025



Robotics researchers increasingly leverage large language models (LLM) in robotics systems, using them as interfaces to receive task commands, generate task plans, form team coalitions, and allocate tasks among multi-robot and human agents. However, despite their benefits, the growing adoption of LLM in robotics has raised several safety concerns, particularly regarding executing malicious or unsafe natural language prompts. In addition, ensuring that task plans, team formation, and task allocation outputs from LLMs are adequately examined, refined, or rejected is crucial for maintaining system integrity. In this paper, we introduce SafePlan, a multi-component framework that combines formal logic and chain-of-thought reasoners for enhancing the safety of LLM-based robotics systems. Using the components of SafePlan, including Prompt Sanity COT Reasoner and Invariant, Precondition, and Postcondition COT reasoners, we examined the safety of natural language task prompts, task plans, and task allocation outputs generated by LLM-based robotic systems as means of investigating and enhancing system safety profile. Our results show that SafePlan outperforms baseline models by leading to 90.5% reduction in harmful task prompt acceptance while still maintaining reasonable acceptance of safe tasks.
REBEL: Rule-based and Experience-enhanced Learning with LLMs for Initial Task Allocation in Multi-Human Multi-Robot Teams
Sep 24, 2024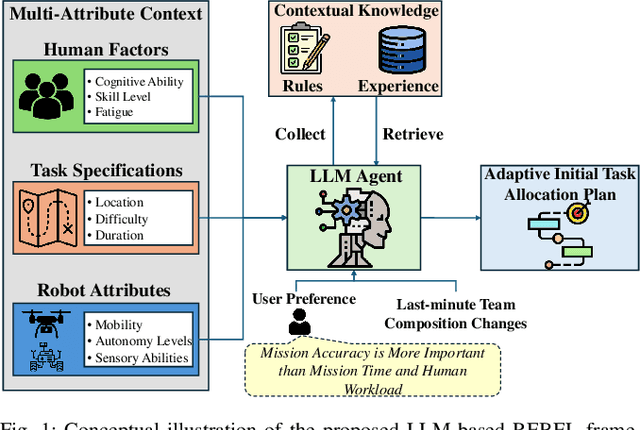
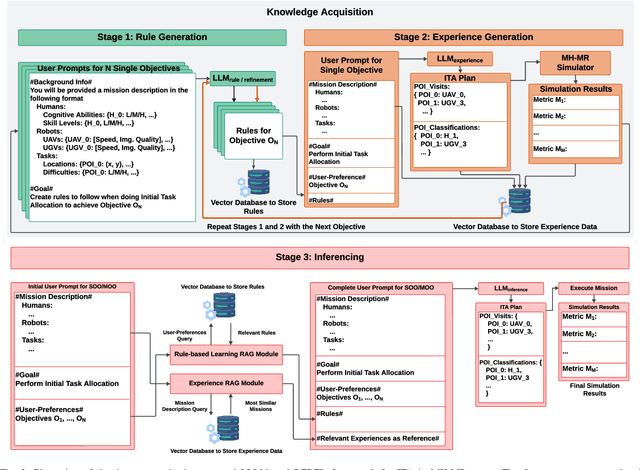
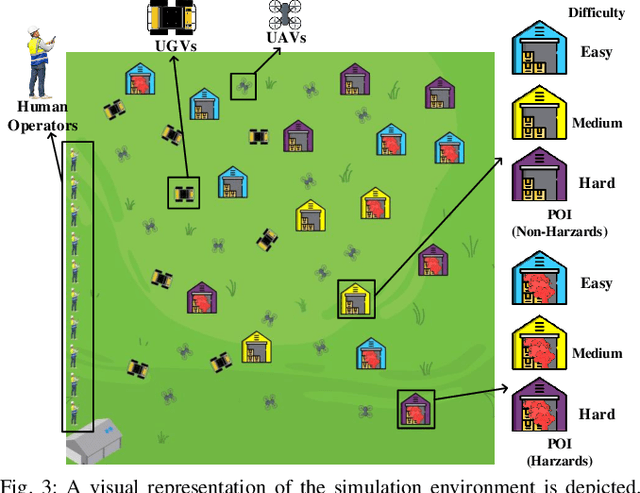
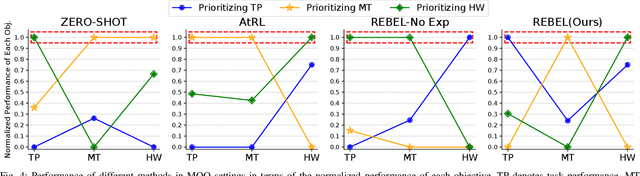
Multi-human multi-robot teams combine the complementary strengths of humans and robots to tackle complex tasks across diverse applications. However, the inherent heterogeneity of these teams presents significant challenges in initial task allocation (ITA), which involves assigning the most suitable tasks to each team member based on their individual capabilities before task execution. While current learning-based methods have shown promising results, they are often computationally expensive to train, and lack the flexibility to incorporate user preferences in multi-objective optimization and adapt to last-minute changes in real-world dynamic environments. To address these issues, we propose REBEL, an LLM-based ITA framework that integrates rule-based and experience-enhanced learning. By leveraging Retrieval-Augmented Generation, REBEL dynamically retrieves relevant rules and past experiences, enhancing reasoning efficiency. Additionally, REBEL can complement pre-trained RL-based ITA policies, improving situational awareness and overall team performance. Extensive experiments validate the effectiveness of our approach across various settings. More details are available at https://sites.google.com/view/ita-rebel .
ZeroCAP: Zero-Shot Multi-Robot Context Aware Pattern Formation via Large Language Models
Apr 02, 2024



Incorporating language comprehension into robotic operations unlocks significant advancements in robotics, but also presents distinct challenges, particularly in executing spatially oriented tasks like pattern formation. This paper introduces ZeroCAP, a novel system that integrates large language models with multi-robot systems for zero-shot context aware pattern formation. Grounded in the principles of language-conditioned robotics, ZeroCAP leverages the interpretative power of language models to translate natural language instructions into actionable robotic configurations. This approach combines the synergy of vision-language models, cutting-edge segmentation techniques and shape descriptors, enabling the realization of complex, context-driven pattern formations in the realm of multi robot coordination. Through extensive experiments, we demonstrate the systems proficiency in executing complex context aware pattern formations across a spectrum of tasks, from surrounding and caging objects to infilling regions. This not only validates the system's capability to interpret and implement intricate context-driven tasks but also underscores its adaptability and effectiveness across varied environments and scenarios. More details about this work are available at: https://sites.google.com/view/zerocap/home
Learning from Demonstration Framework for Multi-Robot Systems Using Interaction Keypoints and Soft Actor-Critic Methods
Apr 02, 2024



Learning from Demonstration (LfD) is a promising approach to enable Multi-Robot Systems (MRS) to acquire complex skills and behaviors. However, the intricate interactions and coordination challenges in MRS pose significant hurdles for effective LfD. In this paper, we present a novel LfD framework specifically designed for MRS, which leverages visual demonstrations to capture and learn from robot-robot and robot-object interactions. Our framework introduces the concept of Interaction Keypoints (IKs) to transform the visual demonstrations into a representation that facilitates the inference of various skills necessary for the task. The robots then execute the task using sensorimotor actions and reinforcement learning (RL) policies when required. A key feature of our approach is the ability to handle unseen contact-based skills that emerge during the demonstration. In such cases, RL is employed to learn the skill using a classifier-based reward function, eliminating the need for manual reward engineering and ensuring adaptability to environmental changes. We evaluate our framework across a range of mobile robot tasks, covering both behavior-based and contact-based domains. The results demonstrate the effectiveness of our approach in enabling robots to learn complex multi-robot tasks and behaviors from visual demonstrations.
DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs
Sep 27, 2023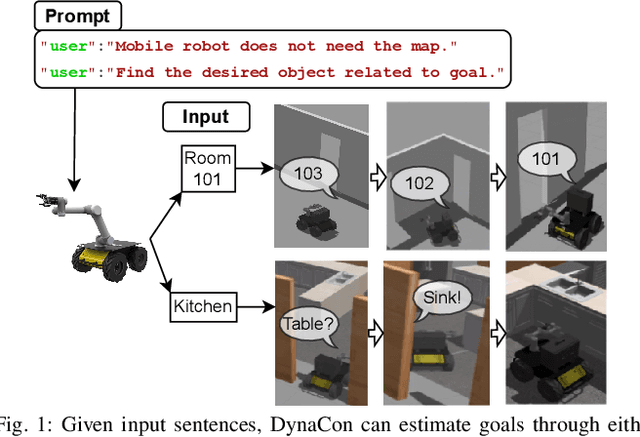
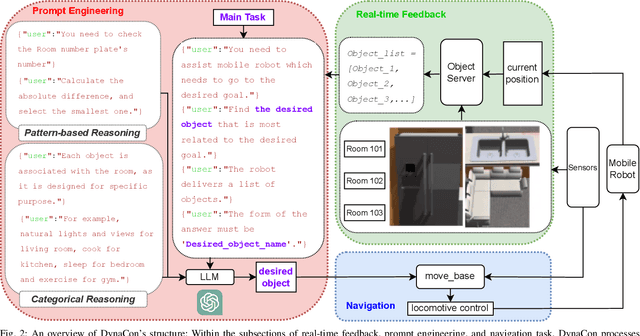
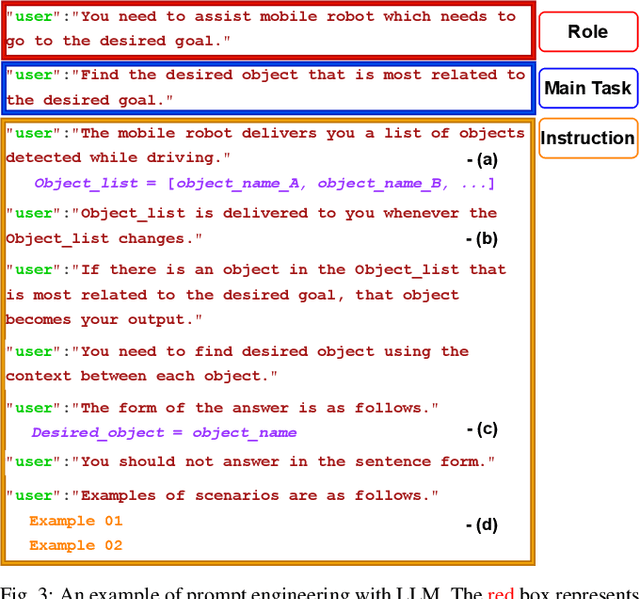
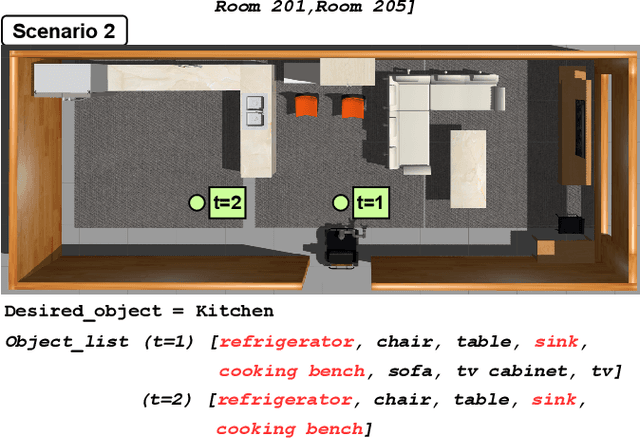
Mobile robots often rely on pre-existing maps for effective path planning and navigation. However, when these maps are unavailable, particularly in unfamiliar environments, a different approach become essential. This paper introduces DynaCon, a novel system designed to provide mobile robots with contextual awareness and dynamic adaptability during navigation, eliminating the reliance of traditional maps. DynaCon integrates real-time feedback with an object server, prompt engineering, and navigation modules. By harnessing the capabilities of Large Language Models (LLMs), DynaCon not only understands patterns within given numeric series but also excels at categorizing objects into matched spaces. This facilitates dynamic path planner imbued with contextual awareness. We validated the effectiveness of DynaCon through an experiment where a robot successfully navigated to its goal using reasoning. Source code and experiment videos for this work can be found at: https://sites.google.com/view/dynacon.
SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models
Sep 18, 2023In this work, we introduce SMART-LLM, an innovative framework designed for embodied multi-robot task planning. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models (LLMs), harnesses the power of LLMs to convert high-level task instructions provided as input into a multi-robot task plan. It accomplishes this by executing a series of stages, including task decomposition, coalition formation, and task allocation, all guided by programmatic LLM prompts within the few-shot prompting paradigm. We create a benchmark dataset designed for validating the multi-robot task planning problem, encompassing four distinct categories of high-level instructions that vary in task complexity. Our evaluation experiments span both simulation and real-world scenarios, demonstrating that the proposed model can achieve promising results for generating multi-robot task plans. The experimental videos, code, and datasets from the work can be found at https://sites.google.com/view/smart-llm/.
UPPLIED: UAV Path Planning for Inspection through Demonstration
Mar 07, 2023



In this paper, a new demonstration-based path-planning framework for the visual inspection of large structures using UAVs is proposed. We introduce UPPLIED: UAV Path PLanning for InspEction through Demonstration, which utilizes a demonstrated trajectory to generate a new trajectory to inspect other structures of the same kind. The demonstrated trajectory can inspect specific regions of the structure and the new trajectory generated by UPPLIED inspects similar regions in the other structure. The proposed method generates inspection points from the demonstrated trajectory and uses standardization to translate those inspection points to inspect the new structure. Finally, the position of these inspection points is optimized to refine their view. Numerous experiments were conducted with various structures and the proposed framework was able to generate inspection trajectories of various kinds for different structures based on the demonstration. The trajectories generated match with the demonstrated trajectory in geometry and at the same time inspect the regions inspected by the demonstration trajectory with minimum deviation. The experimental video of the work can be found at https://youtu.be/YqPx-cLkv04.
Extending Policy from One-Shot Learning through Coaching
May 13, 2019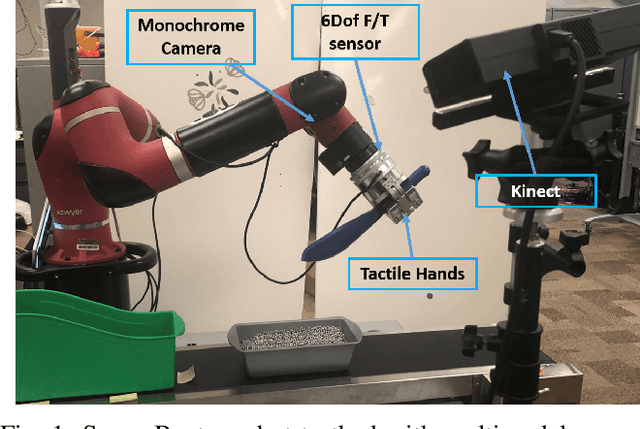
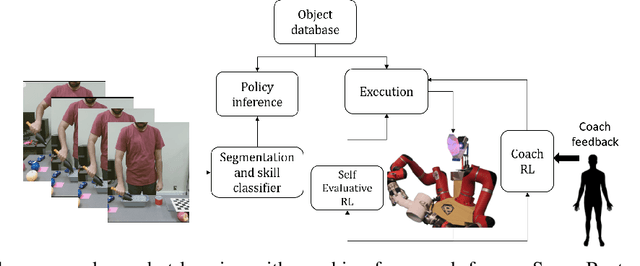
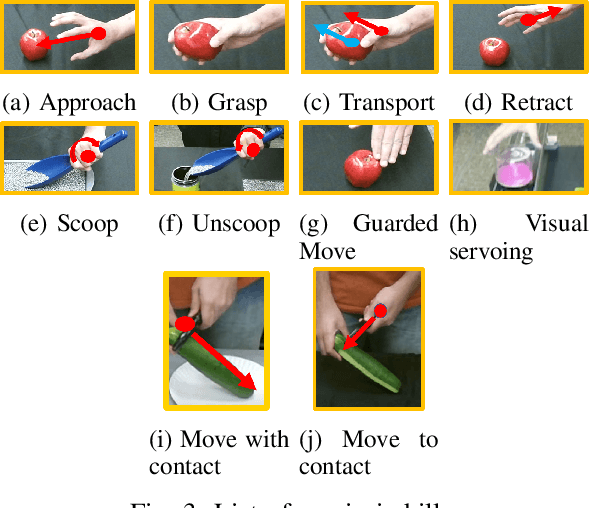
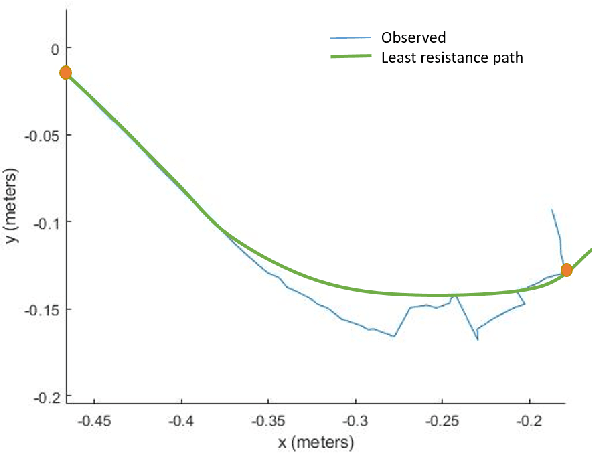
Humans generally teach their fellow collaborators to perform tasks through a small number of demonstrations. The learnt task is corrected or extended to meet specific task goals by means of coaching. Adopting a similar framework for teaching robots through demonstrations and coaching makes teaching tasks highly intuitive. Unlike traditional Learning from Demonstration (LfD) approaches which require multiple demonstrations, we present a one-shot learning from demonstration approach to learn tasks. The learnt task is corrected and generalized using two layers of evaluation/modification. First, the robot self-evaluates its performance and corrects the performance to be closer to the demonstrated task. Then, coaching is used as a means to extend the policy learnt to be adaptable to varying task goals. Both the self-evaluation and coaching are implemented using reinforcement learning (RL) methods. Coaching is achieved through human feedback on desired goal and action modification to generalize to specified task goals. The proposed approach is evaluated with a scooping task, by presenting a single demonstration. The self-evaluation framework aims to reduce the resistance to scooping in the media. To reduce the search space for RL, we bootstrap the search using least resistance path obtained using resistive force theory. Coaching is used to generalize the learnt task policy to transfer the desired quantity of material. Thus, the proposed method provides a framework for learning tasks from one demonstration and generalizing it using human feedback through coaching.