 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: An in-vivo Methane Sensing System for Real-time Monitoring of Enteric Emissions in Cattle with ex-vivo Validation
Aug 06, 2025Accurate measurement of enteric methane emissions remains a critical bottleneck for advancing livestock sustainability through genetic selection and precision management. Existing ambient sampling approaches suffer from low data retention rates, environmental interference, and limited temporal resolution. We developed SCOUT (Smart Cannula-mounted Optical Unit for Trace-methane), the first robust in-vivo sensing system enabling continuous, high-resolution monitoring of ruminal methane concentrations through an innovative closed-loop gas recirculation design. We conducted comprehensive validation with two cannulated Simmental heifers under contrasting dietary treatments, with cross-platform comparison against established ambient sniffer systems. SCOUT achieved exceptional performance with 82% data retention compared to 17% for conventional sniffer systems, while capturing methane concentrations 100-1000x higher than ambient approaches. Cross-platform validation demonstrated strong scale-dependent correlations, with optimal correlation strength (r = -0.564 $\pm$ 0.007) at biologically relevant 40-minute windows and 100% statistical significance. High-frequency monitoring revealed novel behavior-emission coupling, including rapid concentration changes (14.5 $\pm$ 11.3k ppm) triggered by postural transitions within 15 minutes, insights previously inaccessible through existing technologies. The SCOUT system represents a transformative advancement, enabling accurate, continuous emission phenotyping essential for genomic selection programs and sustainable precision livestock management. This validation framework establishes new benchmarks for agricultural sensor performance while generating unprecedented biological insights into ruminal methane dynamics, contributing essential tools for sustainable livestock production in climate-conscious agricultural systems.
A Predefined-Time Convergent and Noise-Tolerant Zeroing Neural Network Model for Time Variant Quadratic Programming With Application to Robot Motion Planning
Dec 29, 2024This paper develops a predefined-time convergent and noise-tolerant fractional-order zeroing neural network (PTC-NT-FOZNN) model, innovatively engineered to tackle time-variant quadratic programming (TVQP) challenges. The PTC-NT-FOZNN, stemming from a novel iteration within the variable-gain ZNN spectrum, known as FOZNNs, features diminishing gains over time and marries noise resistance with predefined-time convergence, making it ideal for energy-efficient robotic motion planning tasks. The PTC-NT-FOZNN enhances traditional ZNN models by incorporating a newly developed activation function that promotes optimal convergence irrespective of the model's order. When evaluated against six established ZNNs, the PTC-NT-FOZNN, with parameters $0 < \alpha \leq 1$, demonstrates enhanced positional precision and resilience to additive noises, making it exceptionally suitable for TVQP tasks. Thorough practical assessments, including simulations and experiments using a Flexiv Rizon robotic arm, confirm the PTC-NT-FOZNN's capabilities in achieving precise tracking and high computational efficiency, thereby proving its effectiveness for robust kinematic control applications.
Fractional-order spike-timing-dependent gradient descent for multi-layer spiking neural networks
Oct 20, 2024



Accumulated detailed knowledge about the neuronal activities in human brains has brought more attention to bio-inspired spiking neural networks (SNNs). In contrast to non-spiking deep neural networks (DNNs), SNNs can encode and transmit spatiotemporal information more efficiently by exploiting biologically realistic and low-power event-driven neuromorphic architectures. However, the supervised learning of SNNs still remains a challenge because the spike-timing-dependent plasticity (STDP) of connected spiking neurons is difficult to implement and interpret in existing backpropagation learning schemes. This paper proposes a fractional-order spike-timing-dependent gradient descent (FO-STDGD) learning model by considering a derived nonlinear activation function that describes the relationship between the quasi-instantaneous firing rate and the temporal membrane potentials of nonleaky integrate-and-fire neurons. The training strategy can be generalized to any fractional orders between 0 and 2 since the FO-STDGD incorporates the fractional gradient descent method into the calculation of spike-timing-dependent loss gradients. The proposed FO-STDGD model is tested on the MNIST and DVS128 Gesture datasets and its accuracy under different network structure and fractional orders is analyzed. It can be found that the classification accuracy increases as the fractional order increases, and specifically, the case of fractional order 1.9 improves by 155% relative to the case of fractional order 1 (traditional gradient descent). In addition, our scheme demonstrates the state-of-the-art computational efficacy for the same SNN structure and training epochs.
* 15 pages, 12 figures
RUSOpt: Robotic UltraSound Probe Normalization with Bayesian Optimization for In-plane and Out-plane Scanning
Oct 05, 2023The one of the significant challenges faced by autonomous robotic ultrasound systems is acquiring high-quality images across different patients. The proper orientation of the robotized probe plays a crucial role in governing the quality of ultrasound images. To address this challenge, we propose a sample-efficient method to automatically adjust the orientation of the ultrasound probe normal to the point of contact on the scanning surface, thereby improving the acoustic coupling of the probe and resulting image quality. Our method utilizes Bayesian Optimization (BO) based search on the scanning surface to efficiently search for the normalized probe orientation. We formulate a novel objective function for BO that leverages the contact force measurements and underlying mechanics to identify the normal. We further incorporate a regularization scheme in BO to handle the noisy objective function. The performance of the proposed strategy has been assessed through experiments on urinary bladder phantoms. These phantoms included planar, tilted, and rough surfaces, and were examined using both linear and convex probes with varying search space limits. Further, simulation-based studies have been carried out using 3D human mesh models. The results demonstrate that the mean ($\pm$SD) absolute angular error averaged over all phantoms and 3D models is $\boldsymbol{2.4\pm0.7^\circ}$ and $\boldsymbol{2.1\pm1.3^\circ}$, respectively.
RoboMal: Malware Detection for Robot Network Systems
Jan 20, 2022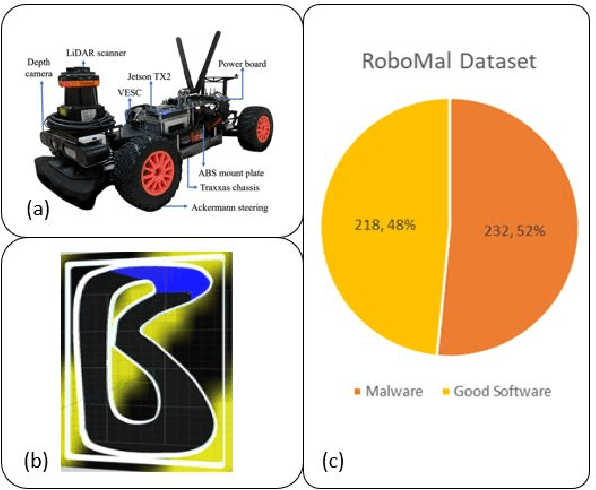
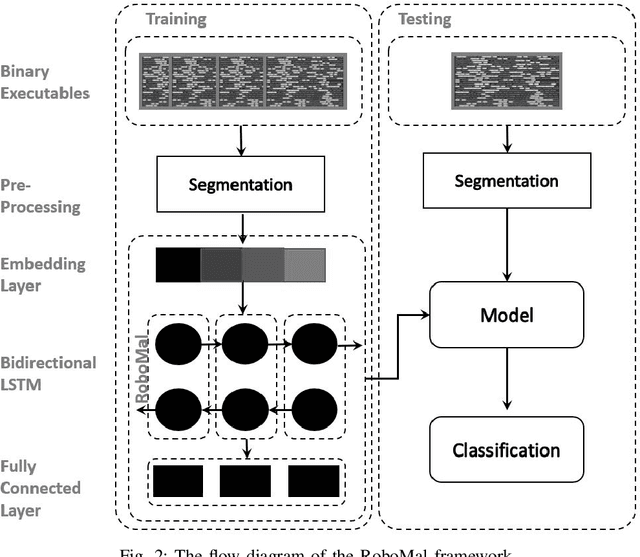
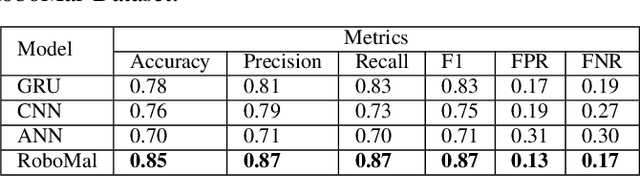
Robot systems are increasingly integrating into numerous avenues of modern life. From cleaning houses to providing guidance and emotional support, robots now work directly with humans. Due to their far-reaching applications and progressively complex architecture, they are being targeted by adversarial attacks such as sensor-actuator attacks, data spoofing, malware, and network intrusion. Therefore, security for robotic systems has become crucial. In this paper, we address the underserved area of malware detection in robotic software. Since robots work in close proximity to humans, often with direct interactions, malware could have life-threatening impacts. Hence, we propose the RoboMal framework of static malware detection on binary executables to detect malware before it gets a chance to execute. Additionally, we address the great paucity of data in this space by providing the RoboMal dataset comprising controller executables of a small-scale autonomous car. The performance of the framework is compared against widely used supervised learning models: GRU, CNN, and ANN. Notably, the LSTM-based RoboMal model outperforms the other models with an accuracy of 85% and precision of 87% in 10-fold cross-validation, hence proving the effectiveness of the proposed framework.
Enhancing Safety of Students with Mobile Air Filtration during School Reopening from COVID-19
Apr 29, 2021



The paper discusses how robots enable occupant-safe continuous protection for students when schools reopen. Conventionally, fixed air filters are not used as a key pandemic prevention method for public indoor spaces because they are unable to trap the airborne pathogens in time in the entire room. However, by combining the mobility of a robot with air filtration, the efficacy of cleaning up the air around multiple people is largely increased. A disinfection co-robot prototype is thus developed to provide continuous and occupant-friendly protection to people gathering indoors, specifically for students in a classroom scenario. In a static classroom with students sitting in a grid pattern, the mobile robot is able to serve up to 14 students per cycle while reducing the worst-case pathogen dosage by 20%, and with higher robustness compared to a static filter. The extent of robot protection is optimized by tuning the passing distance and speed, such that a robot is able to serve more people given a threshold of worst-case dosage a person can receive.
Learning Multimodal Contact-Rich Skills from Demonstrations Without Reward Engineering
Mar 01, 2021
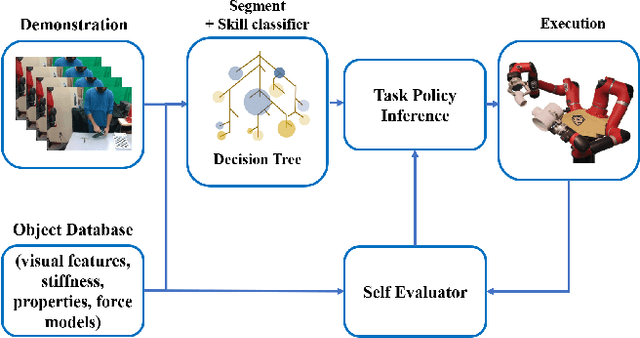
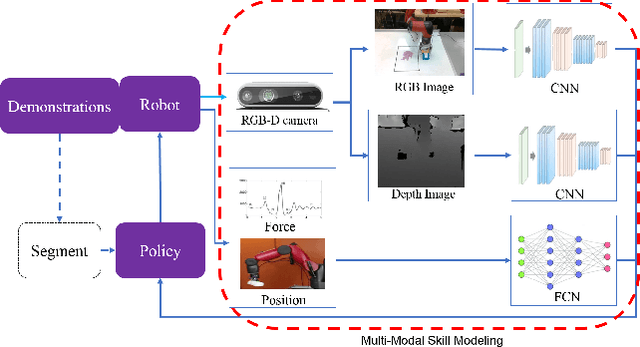
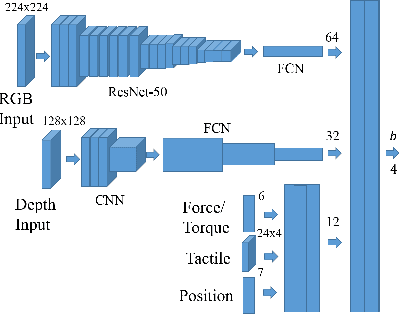
Everyday contact-rich tasks, such as peeling, cleaning, and writing, demand multimodal perception for effective and precise task execution. However, these present a novel challenge to robots as they lack the ability to combine these multimodal stimuli for performing contact-rich tasks. Learning-based methods have attempted to model multi-modal contact-rich tasks, but they often require extensive training examples and task-specific reward functions which limits their practicality and scope. Hence, we propose a generalizable model-free learning-from-demonstration framework for robots to learn contact-rich skills without explicit reward engineering. We present a novel multi-modal sensor data representation which improves the learning performance for contact-rich skills. We performed training and experiments using the real-life Sawyer robot for three everyday contact-rich skills -- cleaning, writing, and peeling. Notably, the framework achieves a success rate of 100% for the peeling and writing skill, and 80% for the cleaning skill. Hence, this skill learning framework can be extended for learning other physical manipulation skills.
Clutter Slices Approach for Identification-on-the-fly of Indoor Spaces
Jan 12, 2021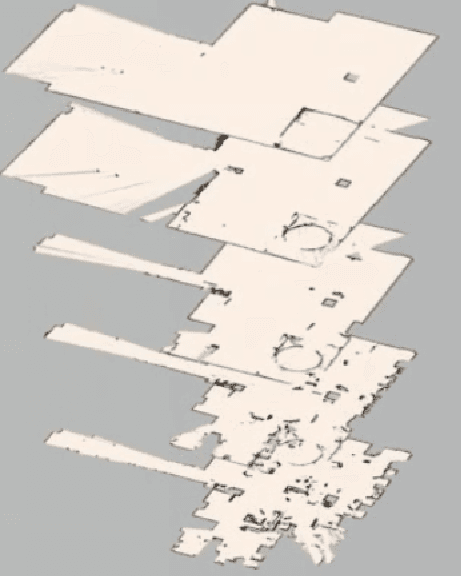
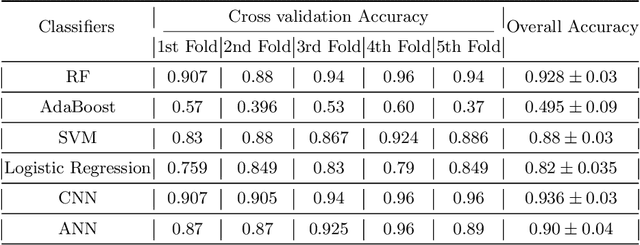
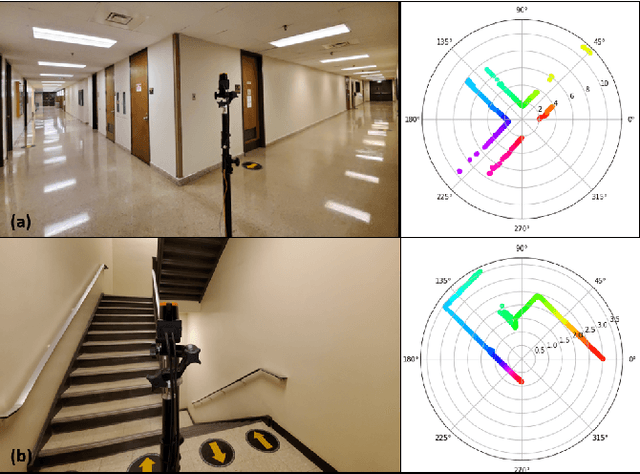
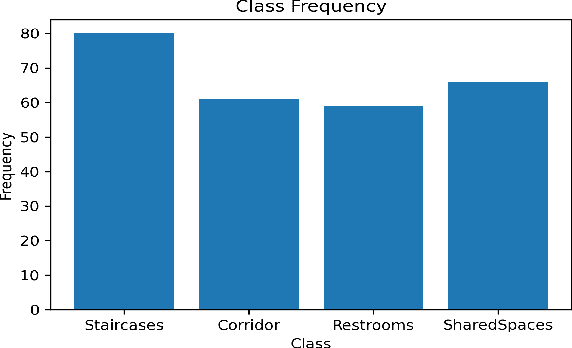
Construction spaces are constantly evolving, dynamic environments in need of continuous surveying, inspection, and assessment. Traditional manual inspection of such spaces proves to be an arduous and time-consuming activity. Automation using robotic agents can be an effective solution. Robots, with perception capabilities can autonomously classify and survey indoor construction spaces. In this paper, we present a novel identification-on-the-fly approach for coarse classification of indoor spaces using the unique signature of clutter. Using the context granted by clutter, we recognize common indoor spaces such as corridors, staircases, shared spaces, and restrooms. The proposed clutter slices pipeline achieves a maximum accuracy of 93.6% on the presented clutter slices dataset. This sensor independent approach can be generalized to various domains to equip intelligent autonomous agents in better perceiving their environment.
* First two authors share equal contribution. Presented at ICPR2020 The 25th International Conference on Pattern Recognition, PRAConBE Workshop
Inspection-on-the-fly using Hybrid Physical Interaction Control for Aerial Manipulators
Oct 19, 2020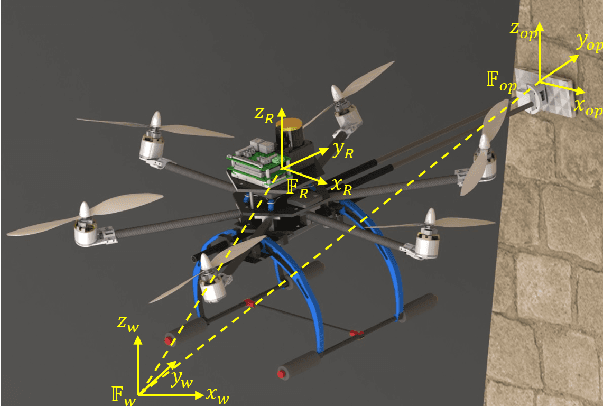
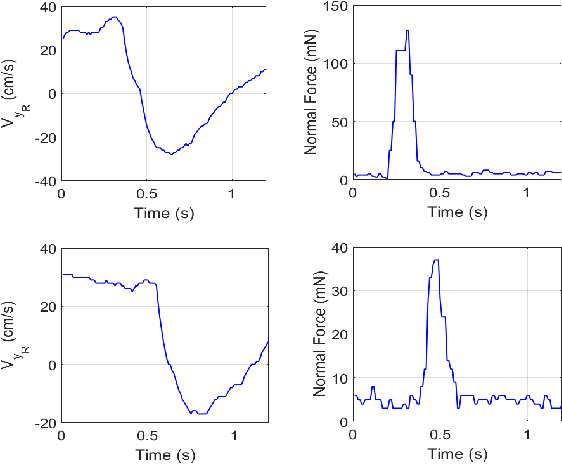
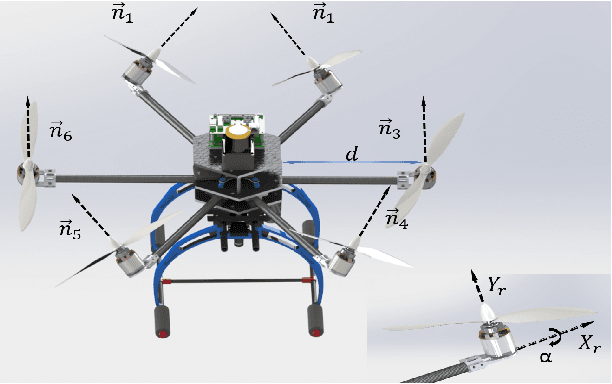
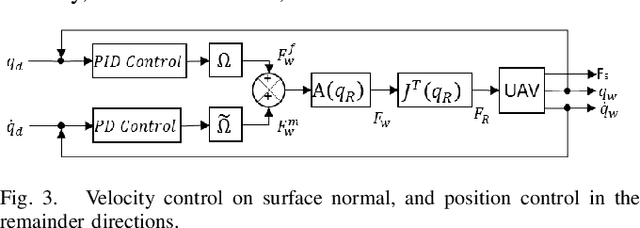
Inspection for structural properties (surface stiffness and coefficient of restitution) is crucial for understanding and performing aerial manipulations in unknown environments, with little to no prior knowledge on their state. Inspection-on-the-fly is the uncanny ability of humans to infer states during manipulation, reducing the necessity to perform inspection and manipulation separately. This paper presents an infrastructure for inspection-on-the-fly method for aerial manipulators using hybrid physical interaction control. With the proposed method, structural properties (surface stiffness and coefficient of restitution) can be estimated during physical interactions. A three-stage hybrid physical interaction control paradigm is presented to robustly approach, acquire and impart a desired force signature onto a surface. This is achieved by combining a hybrid force/motion controller with a model-based feed-forward impact control as intermediate phase. The proposed controller ensures a steady transition from unconstrained motion control to constrained force control, while reducing the lag associated with the force control phase. And an underlying Operational Space dynamic configuration manager permits complex, redundant vehicle/arm combinations. Experiments were carried out in a mock-up of a Dept. of Energy exhaust shaft, to show the effectiveness of the inspection-on-the-fly method to determine the structural properties of the target surface and the performance of the hybrid physical interaction controller in reducing the lag associated with force control phase.
* This paper has been accept for IROS 2020 publication
Evaluation of Sampling Methods for Robotic Sediment Sampling Systems
Jun 23, 2020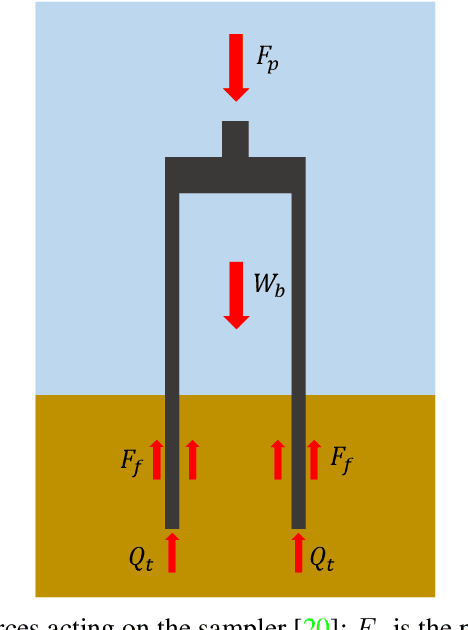
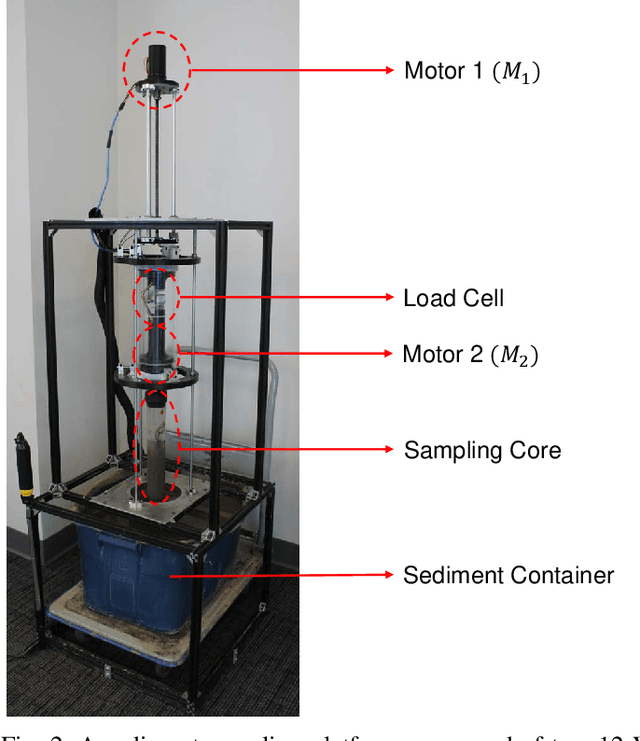
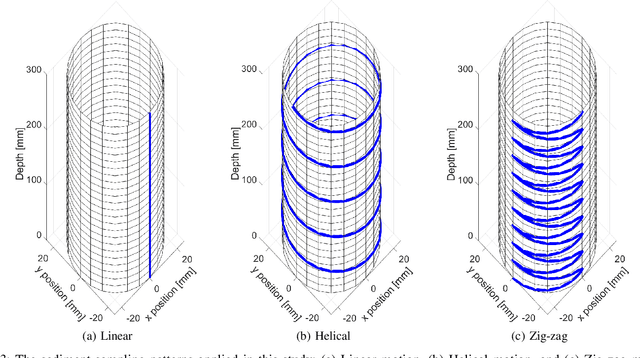
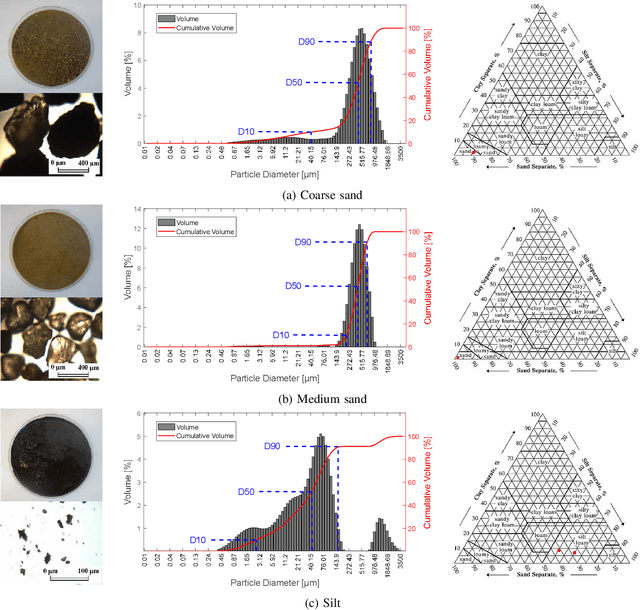
Analysis of sediments from rivers, lakes, reservoirs, wetlands and other constructed surface water impoundments is an important tool to characterize the function and health of these systems, but is generally carried out manually. This is costly and can be hazardous and difficult for humans due to inaccessibility, contamination, or availability of required equipment. Robotic sampling systems can ease these burdens, but little work has examined the efficiency of such sampling means and no prior work has investigated the quality of the resulting samples. This paper presents an experimental study that evaluates and optimizes sediment sampling patterns applied to a robot sediment sampling system that allows collection of minimally-disturbed sediment cores from natural and man-made water bodies for various sediment types. To meet this need, we developed and tested a robotic sampling platform in the laboratory to test functionality under a range of sediment types and operating conditions. Specifically, we focused on three patterns by which a cylindrical coring device was driven into the sediment (linear, helical, and zig-zag) for three sediment types (coarse sand, medium sand, and silt). The results show that the optimal sampling pattern varies depending on the type of sediment and can be optimized based on the sampling objective. We examined two sampling objectives: maximizing the mass of minimally disturbed sediment and minimizing the power per mass of sample. This study provides valuable data to aid in the selection of optimal sediment coring methods for various applications and builds a solid foundation for future field testing under a range of environmental conditions.