 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoaching a Robotic Sonographer: Learning Robotic Ultrasound with Sparse Expert's Feedback
Sep 03, 2024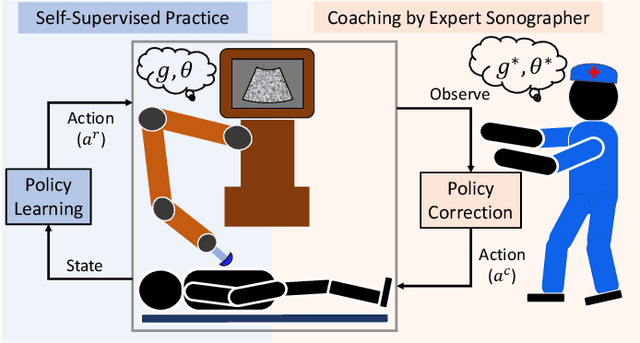
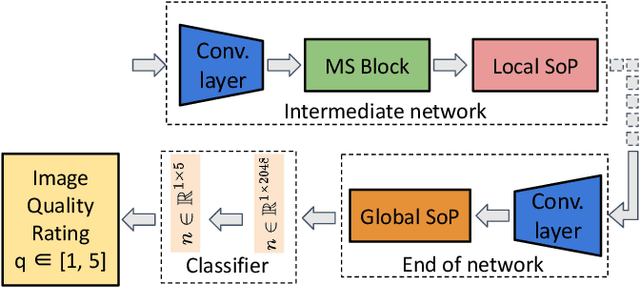
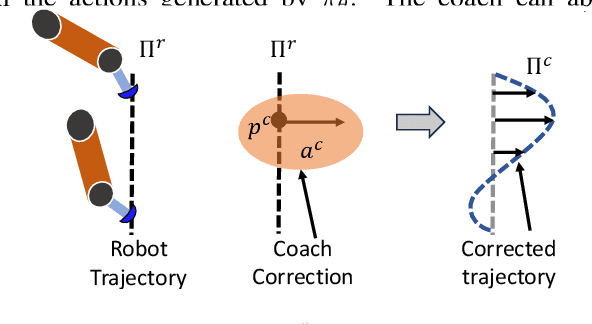
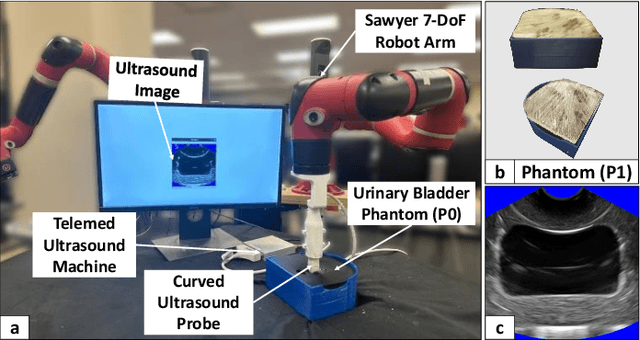
Ultrasound is widely employed for clinical intervention and diagnosis, due to its advantages of offering non-invasive, radiation-free, and real-time imaging. However, the accessibility of this dexterous procedure is limited due to the substantial training and expertise required of operators. The robotic ultrasound (RUS) offers a viable solution to address this limitation; nonetheless, achieving human-level proficiency remains challenging. Learning from demonstrations (LfD) methods have been explored in RUS, which learns the policy prior from a dataset of offline demonstrations to encode the mental model of the expert sonographer. However, active engagement of experts, i.e. Coaching, during the training of RUS has not been explored thus far. Coaching is known for enhancing efficiency and performance in human training. This paper proposes a coaching framework for RUS to amplify its performance. The framework combines DRL (self-supervised practice) with sparse expert's feedback through coaching. The DRL employs an off-policy Soft Actor-Critic (SAC) network, with a reward based on image quality rating. The coaching by experts is modeled as a Partially Observable Markov Decision Process (POMDP), which updates the policy parameters based on the correction by the expert. The validation study on phantoms showed that coaching increases the learning rate by $25\%$ and the number of high-quality image acquisition by $74.5\%$.
Enhancing Safety of Students with Mobile Air Filtration during School Reopening from COVID-19
Apr 29, 2021



The paper discusses how robots enable occupant-safe continuous protection for students when schools reopen. Conventionally, fixed air filters are not used as a key pandemic prevention method for public indoor spaces because they are unable to trap the airborne pathogens in time in the entire room. However, by combining the mobility of a robot with air filtration, the efficacy of cleaning up the air around multiple people is largely increased. A disinfection co-robot prototype is thus developed to provide continuous and occupant-friendly protection to people gathering indoors, specifically for students in a classroom scenario. In a static classroom with students sitting in a grid pattern, the mobile robot is able to serve up to 14 students per cycle while reducing the worst-case pathogen dosage by 20%, and with higher robustness compared to a static filter. The extent of robot protection is optimized by tuning the passing distance and speed, such that a robot is able to serve more people given a threshold of worst-case dosage a person can receive.
Learning Multimodal Contact-Rich Skills from Demonstrations Without Reward Engineering
Mar 01, 2021
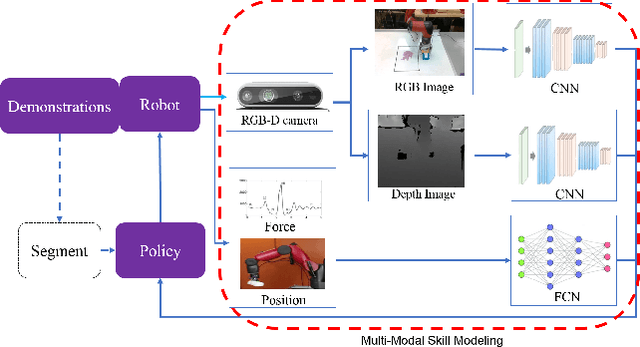
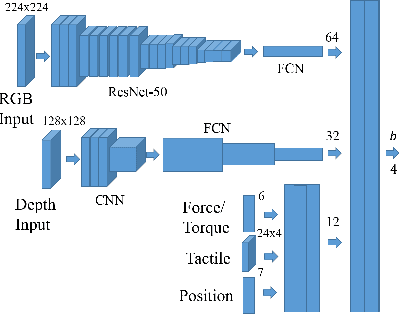
Everyday contact-rich tasks, such as peeling, cleaning, and writing, demand multimodal perception for effective and precise task execution. However, these present a novel challenge to robots as they lack the ability to combine these multimodal stimuli for performing contact-rich tasks. Learning-based methods have attempted to model multi-modal contact-rich tasks, but they often require extensive training examples and task-specific reward functions which limits their practicality and scope. Hence, we propose a generalizable model-free learning-from-demonstration framework for robots to learn contact-rich skills without explicit reward engineering. We present a novel multi-modal sensor data representation which improves the learning performance for contact-rich skills. We performed training and experiments using the real-life Sawyer robot for three everyday contact-rich skills -- cleaning, writing, and peeling. Notably, the framework achieves a success rate of 100% for the peeling and writing skill, and 80% for the cleaning skill. Hence, this skill learning framework can be extended for learning other physical manipulation skills.
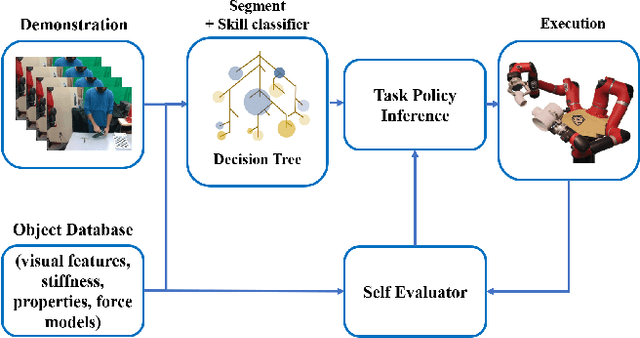
Extending Policy from One-Shot Learning through Coaching
May 13, 2019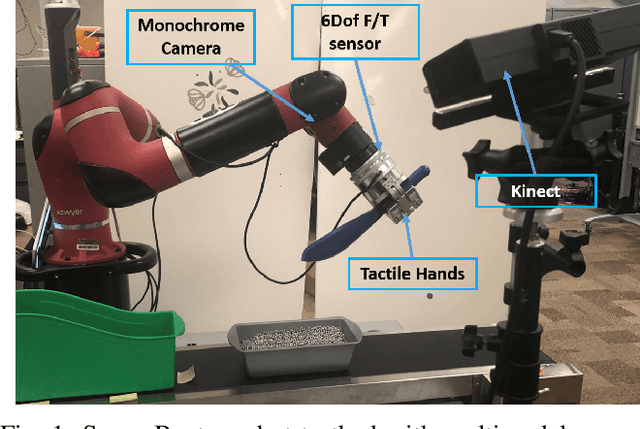
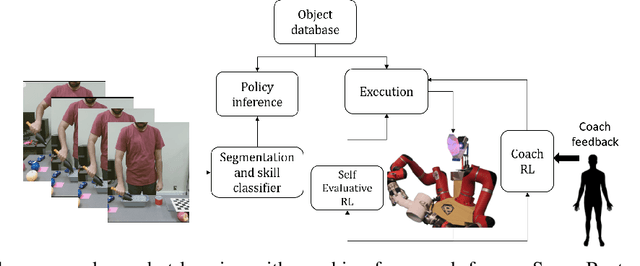
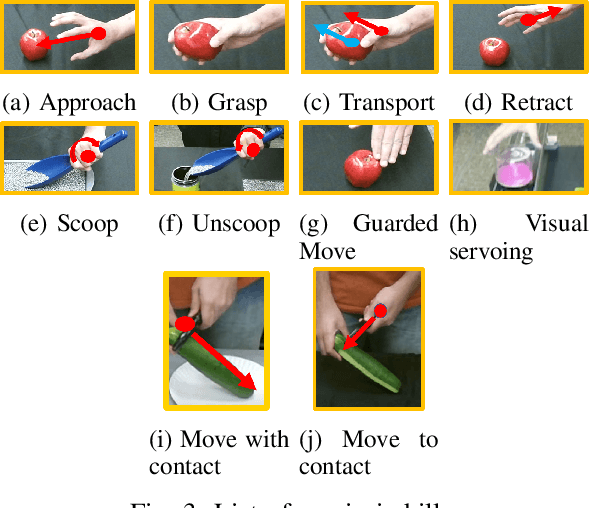
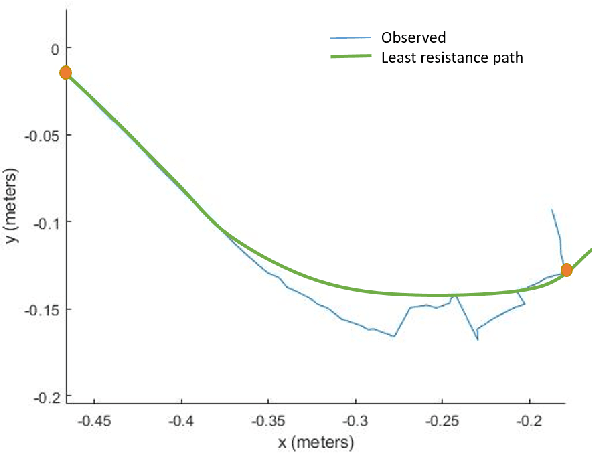
Humans generally teach their fellow collaborators to perform tasks through a small number of demonstrations. The learnt task is corrected or extended to meet specific task goals by means of coaching. Adopting a similar framework for teaching robots through demonstrations and coaching makes teaching tasks highly intuitive. Unlike traditional Learning from Demonstration (LfD) approaches which require multiple demonstrations, we present a one-shot learning from demonstration approach to learn tasks. The learnt task is corrected and generalized using two layers of evaluation/modification. First, the robot self-evaluates its performance and corrects the performance to be closer to the demonstrated task. Then, coaching is used as a means to extend the policy learnt to be adaptable to varying task goals. Both the self-evaluation and coaching are implemented using reinforcement learning (RL) methods. Coaching is achieved through human feedback on desired goal and action modification to generalize to specified task goals. The proposed approach is evaluated with a scooping task, by presenting a single demonstration. The self-evaluation framework aims to reduce the resistance to scooping in the media. To reduce the search space for RL, we bootstrap the search using least resistance path obtained using resistive force theory. Coaching is used to generalize the learnt task policy to transfer the desired quantity of material. Thus, the proposed method provides a framework for learning tasks from one demonstration and generalizing it using human feedback through coaching.
Self-Evaluation in One-Shot Learning from Demonstration of Contact-Intensive Tasks
Apr 03, 2019
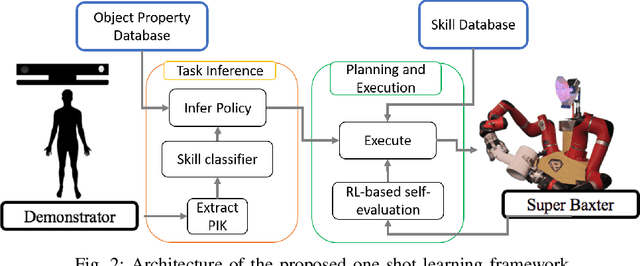
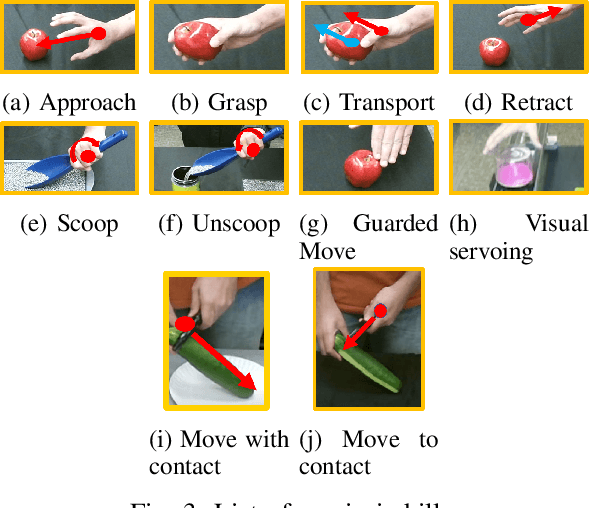
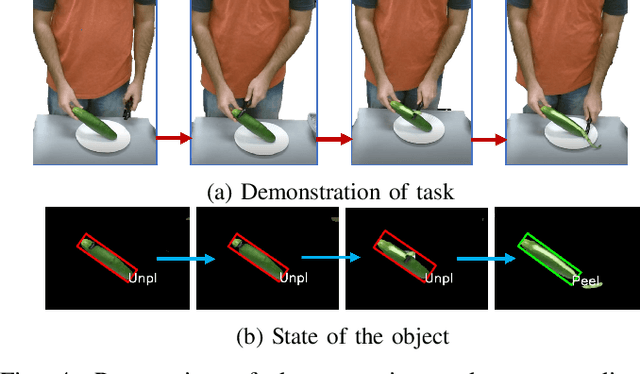
Humans naturally "program" a fellow collaborator to perform a task by demonstrating the task few times. It is intuitive, therefore, for a human to program a collaborative robot by demonstration and many paradigms use a single demonstration of the task. This is a form of one-shot learning in which a single training example, plus some context of the task, is used to infer a model of the task for subsequent execution and later refinement. This paper presents a one-shot learning from demonstration framework to learn contact-intensive tasks using only visual perception of the demonstrated task. The robot learns a policy for performing the tasks in terms of a priori skills and further uses self-evaluation based on visual and tactile perception of the skill performance to learn the force correspondences for the skills. The self-evaluation is performed based on goal states detected in the demonstration with the help of task context and the skill parameters are tuned using reinforcement learning. This approach enables the robot to learn force correspondences which cannot be inferred from a visual demonstration of the task. The effectiveness of this approach is evaluated using a vegetable peeling task.
DESK: A Robotic Activity Dataset for Dexterous Surgical Skills Transfer to Medical Robots
Mar 03, 2019

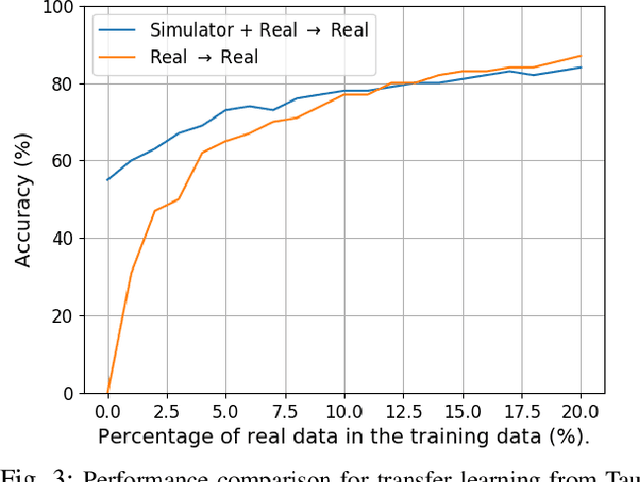
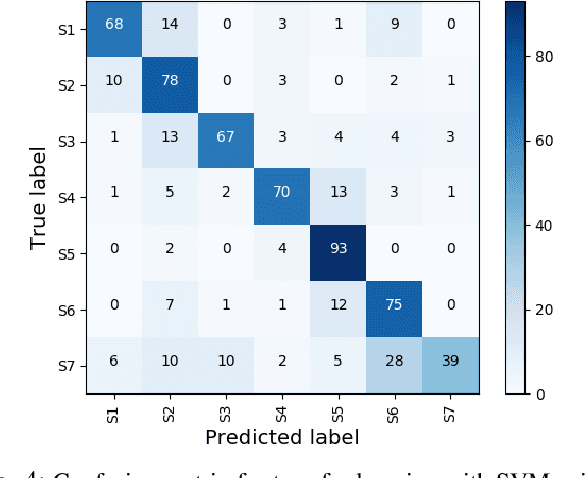
Datasets are an essential component for training effective machine learning models. In particular, surgical robotic datasets have been key to many advances in semi-autonomous surgeries, skill assessment, and training. Simulated surgical environments can enhance the data collection process by making it faster, simpler and cheaper than real systems. In addition, combining data from multiple robotic domains can provide rich and diverse training data for transfer learning algorithms. In this paper, we present the DESK (Dexterous Surgical Skill) dataset. It comprises a set of surgical robotic skills collected during a surgical training task using three robotic platforms: the Taurus II robot, Taurus II simulated robot, and the YuMi robot. This dataset was used to test the idea of transferring knowledge across different domains (e.g. from Taurus to YuMi robot) for a surgical gesture classification task with seven gestures. We explored three different scenarios: 1) No transfer, 2) Transfer from simulated Taurus to real Taurus and 3) Transfer from Simulated Taurus to the YuMi robot. We conducted extensive experiments with three supervised learning models and provided baselines in each of these scenarios. Results show that using simulation data during training enhances the performance on the real robot where limited real data is available. In particular, we obtained an accuracy of 55% on the real Taurus data using a model that is trained only on the simulator data. Furthermore, we achieved an accuracy improvement of 34% when 3% of the real data is added into the training process.