 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Adversarial Style Transfer for Robust Policy Optimization in Deep Reinforcement Learning
Aug 29, 2023This paper proposes an algorithm that aims to improve generalization for reinforcement learning agents by removing overfitting to confounding features. Our approach consists of a max-min game theoretic objective. A generator transfers the style of observation during reinforcement learning. An additional goal of the generator is to perturb the observation, which maximizes the agent's probability of taking a different action. In contrast, a policy network updates its parameters to minimize the effect of such perturbations, thus staying robust while maximizing the expected future reward. Based on this setup, we propose a practical deep reinforcement learning algorithm, Adversarial Robust Policy Optimization (ARPO), to find a robust policy that generalizes to unseen environments. We evaluate our approach on Procgen and Distracting Control Suite for generalization and sample efficiency. Empirically, ARPO shows improved performance compared to a few baseline algorithms, including data augmentation.
Adversarial Policy Optimization in Deep Reinforcement Learning
Apr 27, 2023The policy represented by the deep neural network can overfit the spurious features in observations, which hamper a reinforcement learning agent from learning effective policy. This issue becomes severe in high-dimensional state, where the agent struggles to learn a useful policy. Data augmentation can provide a performance boost to RL agents by mitigating the effect of overfitting. However, such data augmentation is a form of prior knowledge, and naively applying them in environments might worsen an agent's performance. In this paper, we propose a novel RL algorithm to mitigate the above issue and improve the efficiency of the learned policy. Our approach consists of a max-min game theoretic objective where a perturber network modifies the state to maximize the agent's probability of taking a different action while minimizing the distortion in the state. In contrast, the policy network updates its parameters to minimize the effect of perturbation while maximizing the expected future reward. Based on this objective, we propose a practical deep reinforcement learning algorithm, Adversarial Policy Optimization (APO). Our method is agnostic to the type of policy optimization, and thus data augmentation can be incorporated to harness the benefit. We evaluated our approaches on several DeepMind Control robotic environments with high-dimensional and noisy state settings. Empirical results demonstrate that our method APO consistently outperforms the state-of-the-art on-policy PPO agent. We further compare our method with state-of-the-art data augmentation, RAD, and regularization-based approach DRAC. Our agent APO shows better performance compared to these baselines.
Accelerating Policy Gradient by Estimating Value Function from Prior Computation in Deep Reinforcement Learning
Feb 02, 2023This paper investigates the use of prior computation to estimate the value function to improve sample efficiency in on-policy policy gradient methods in reinforcement learning. Our approach is to estimate the value function from prior computations, such as from the Q-network learned in DQN or the value function trained for different but related environments. In particular, we learn a new value function for the target task while combining it with a value estimate from the prior computation. Finally, the resulting value function is used as a baseline in the policy gradient method. This use of a baseline has the theoretical property of reducing variance in gradient computation and thus improving sample efficiency. The experiments show the successful use of prior value estimates in various settings and improved sample efficiency in several tasks.
Robust Policy Optimization in Deep Reinforcement Learning
Dec 14, 2022The policy gradient method enjoys the simplicity of the objective where the agent optimizes the cumulative reward directly. Moreover, in the continuous action domain, parameterized distribution of action distribution allows easy control of exploration, resulting from the variance of the representing distribution. Entropy can play an essential role in policy optimization by selecting the stochastic policy, which eventually helps better explore the environment in reinforcement learning (RL). However, the stochasticity often reduces as the training progresses; thus, the policy becomes less exploratory. Additionally, certain parametric distributions might only work for some environments and require extensive hyperparameter tuning. This paper aims to mitigate these issues. In particular, we propose an algorithm called Robust Policy Optimization (RPO), which leverages a perturbed distribution. We hypothesize that our method encourages high-entropy actions and provides a way to represent the action space better. We further provide empirical evidence to verify our hypothesis. We evaluated our methods on various continuous control tasks from DeepMind Control, OpenAI Gym, Pybullet, and IsaacGym. We observed that in many settings, RPO increases the policy entropy early in training and then maintains a certain level of entropy throughout the training period. Eventually, our agent RPO shows consistently improved performance compared to PPO and other techniques: entropy regularization, different distributions, and data augmentation. Furthermore, in several settings, our method stays robust in performance, while other baseline mechanisms fail to improve and even worsen the performance.
Bootstrap Advantage Estimation for Policy Optimization in Reinforcement Learning
Oct 13, 2022
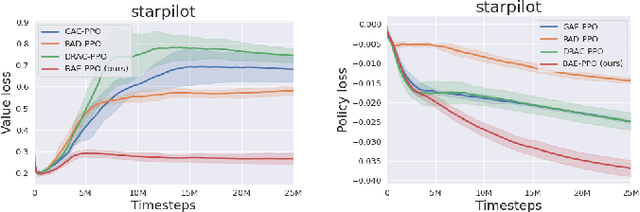
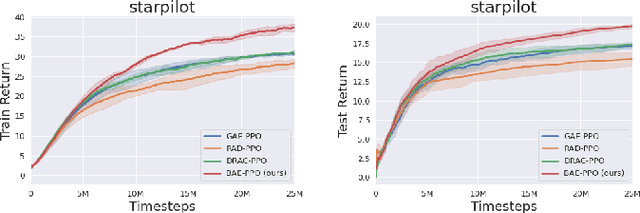
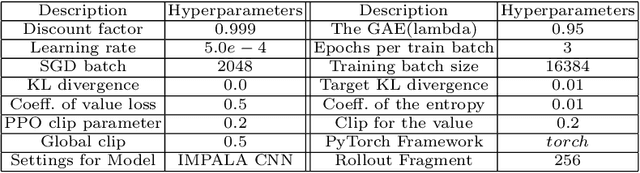
This paper proposes an advantage estimation approach based on data augmentation for policy optimization. Unlike using data augmentation on the input to learn value and policy function as existing methods use, our method uses data augmentation to compute a bootstrap advantage estimation. This Bootstrap Advantage Estimation (BAE) is then used for learning and updating the gradient of policy and value function. To demonstrate the effectiveness of our approach, we conducted experiments on several environments. These environments are from three benchmarks: Procgen, Deepmind Control, and Pybullet, which include both image and vector-based observations; discrete and continuous action spaces. We observe that our method reduces the policy and the value loss better than the Generalized advantage estimation (GAE) method and eventually improves cumulative return. Furthermore, our method performs better than two recently proposed data augmentation techniques (RAD and DRAC). Overall, our method performs better empirically than baselines in sample efficiency and generalization, where the agent is tested in unseen environments.
Bootstrap State Representation using Style Transfer for Better Generalization in Deep Reinforcement Learning
Jul 15, 2022


Deep Reinforcement Learning (RL) agents often overfit the training environment, leading to poor generalization performance. In this paper, we propose Thinker, a bootstrapping method to remove adversarial effects of confounding features from the observation in an unsupervised way, and thus, it improves RL agents' generalization. Thinker first clusters experience trajectories into several clusters. These trajectories are then bootstrapped by applying a style transfer generator, which translates the trajectories from one cluster's style to another while maintaining the content of the observations. The bootstrapped trajectories are then used for policy learning. Thinker has wide applicability among many RL settings. Experimental results reveal that Thinker leads to better generalization capability in the Procgen benchmark environments compared to base algorithms and several data augmentation techniques.
DESK: A Robotic Activity Dataset for Dexterous Surgical Skills Transfer to Medical Robots
Mar 03, 2019

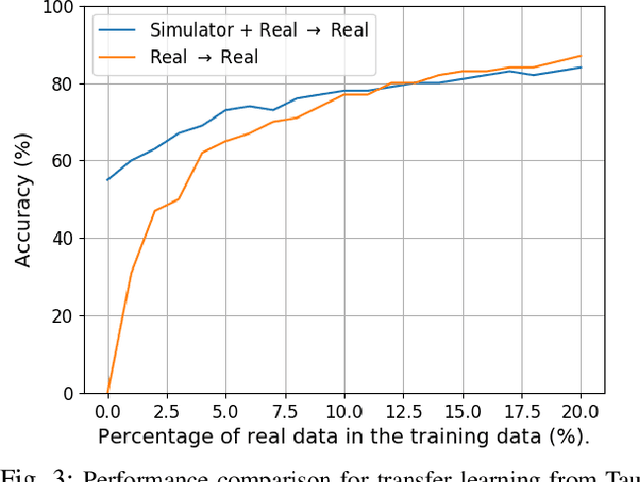
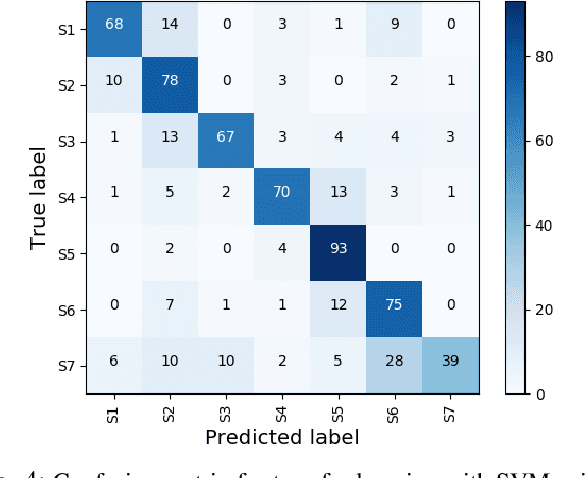
Datasets are an essential component for training effective machine learning models. In particular, surgical robotic datasets have been key to many advances in semi-autonomous surgeries, skill assessment, and training. Simulated surgical environments can enhance the data collection process by making it faster, simpler and cheaper than real systems. In addition, combining data from multiple robotic domains can provide rich and diverse training data for transfer learning algorithms. In this paper, we present the DESK (Dexterous Surgical Skill) dataset. It comprises a set of surgical robotic skills collected during a surgical training task using three robotic platforms: the Taurus II robot, Taurus II simulated robot, and the YuMi robot. This dataset was used to test the idea of transferring knowledge across different domains (e.g. from Taurus to YuMi robot) for a surgical gesture classification task with seven gestures. We explored three different scenarios: 1) No transfer, 2) Transfer from simulated Taurus to real Taurus and 3) Transfer from Simulated Taurus to the YuMi robot. We conducted extensive experiments with three supervised learning models and provided baselines in each of these scenarios. Results show that using simulation data during training enhances the performance on the real robot where limited real data is available. In particular, we obtained an accuracy of 55% on the real Taurus data using a model that is trained only on the simulator data. Furthermore, we achieved an accuracy improvement of 34% when 3% of the real data is added into the training process.