 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootstrap Advantage Estimation for Policy Optimization in Reinforcement Learning
Paper and Code

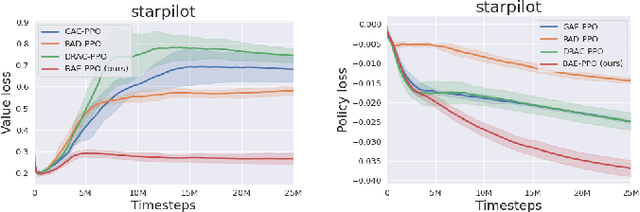
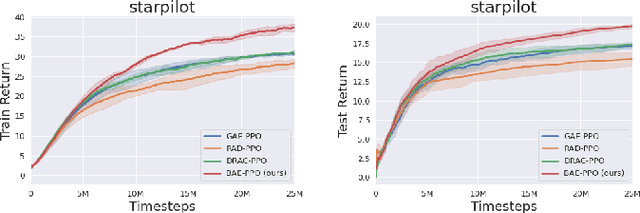
This paper proposes an advantage estimation approach based on data augmentation for policy optimization. Unlike using data augmentation on the input to learn value and policy function as existing methods use, our method uses data augmentation to compute a bootstrap advantage estimation. This Bootstrap Advantage Estimation (BAE) is then used for learning and updating the gradient of policy and value function. To demonstrate the effectiveness of our approach, we conducted experiments on several environments. These environments are from three benchmarks: Procgen, Deepmind Control, and Pybullet, which include both image and vector-based observations; discrete and continuous action spaces. We observe that our method reduces the policy and the value loss better than the Generalized advantage estimation (GAE) method and eventually improves cumulative return. Furthermore, our method performs better than two recently proposed data augmentation techniques (RAD and DRAC). Overall, our method performs better empirically than baselines in sample efficiency and generalization, where the agent is tested in unseen environments.