 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evaluation in One-Shot Learning from Demonstration of Contact-Intensive Tasks
Paper and Code
Apr 03, 2019
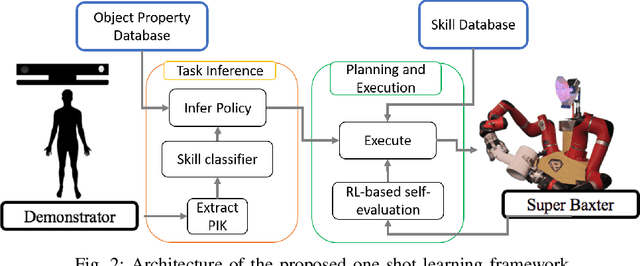
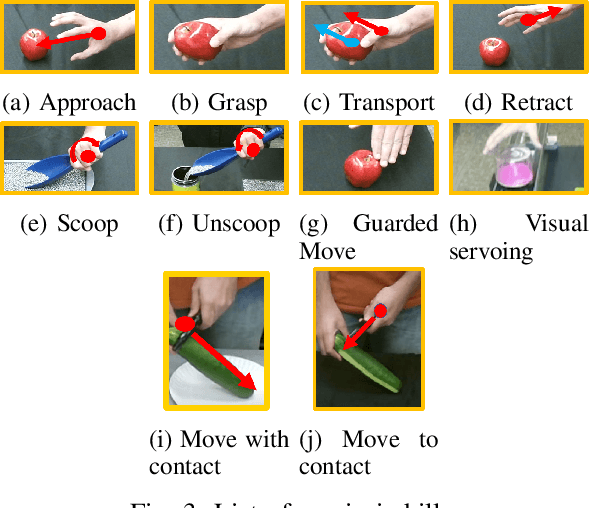
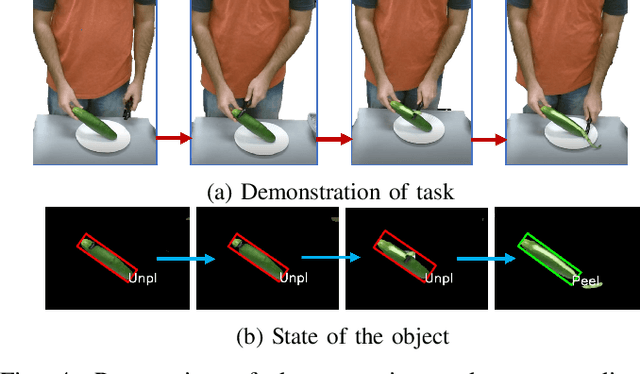
Humans naturally "program" a fellow collaborator to perform a task by demonstrating the task few times. It is intuitive, therefore, for a human to program a collaborative robot by demonstration and many paradigms use a single demonstration of the task. This is a form of one-shot learning in which a single training example, plus some context of the task, is used to infer a model of the task for subsequent execution and later refinement. This paper presents a one-shot learning from demonstration framework to learn contact-intensive tasks using only visual perception of the demonstrated task. The robot learns a policy for performing the tasks in terms of a priori skills and further uses self-evaluation based on visual and tactile perception of the skill performance to learn the force correspondences for the skills. The self-evaluation is performed based on goal states detected in the demonstration with the help of task context and the skill parameters are tuned using reinforcement learning. This approach enables the robot to learn force correspondences which cannot be inferred from a visual demonstration of the task. The effectiveness of this approach is evaluated using a vegetable peeling task.