 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaceFormer: Transformer-based Visual Place Recognition using Multi-Scale Patch Selection and Fusion
Jan 23, 2024Visual place recognition is a challenging task in the field of computer vision, and autonomous robotics and vehicles, which aims to identify a location or a place from visual inputs. Contemporary methods in visual place recognition employ convolutional neural networks and utilize every region within the image for the place recognition task. However, the presence of dynamic and distracting elements in the image may impact the effectiveness of the place recognition process. Therefore, it is meaningful to focus on task-relevant regions of the image for improved recognition. In this paper, we present PlaceFormer, a novel transformer-based approach for visual place recognition. PlaceFormer employs patch tokens from the transformer to create global image descriptors, which are then used for image retrieval. To re-rank the retrieved images, PlaceFormer merges the patch tokens from the transformer to form multi-scale patches. Utilizing the transformer's self-attention mechanism, it selects patches that correspond to task-relevant areas in an image. These selected patches undergo geometric verification, generating similarity scores across different patch sizes. Subsequently, spatial scores from each patch size are fused to produce a final similarity score. This score is then used to re-rank the images initially retrieved using global image descriptors. Extensive experiments on benchmark datasets demonstrate that PlaceFormer outperforms several state-of-the-art methods in terms of accuracy and computational efficiency, requiring less time and memory.
DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs
Sep 27, 2023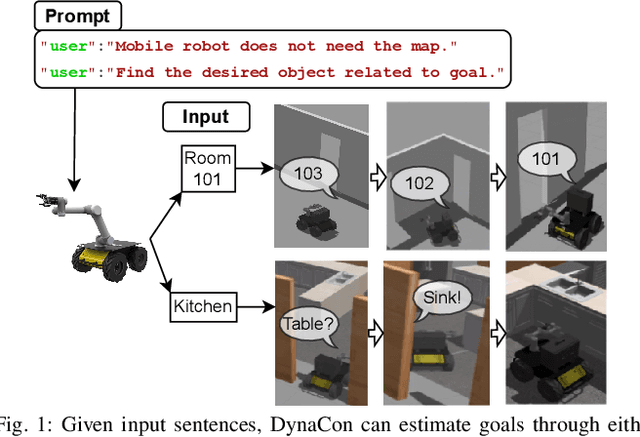
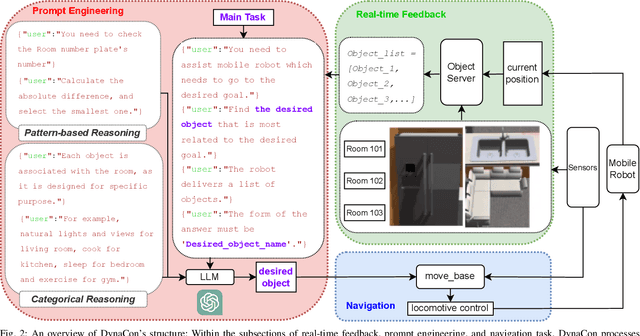
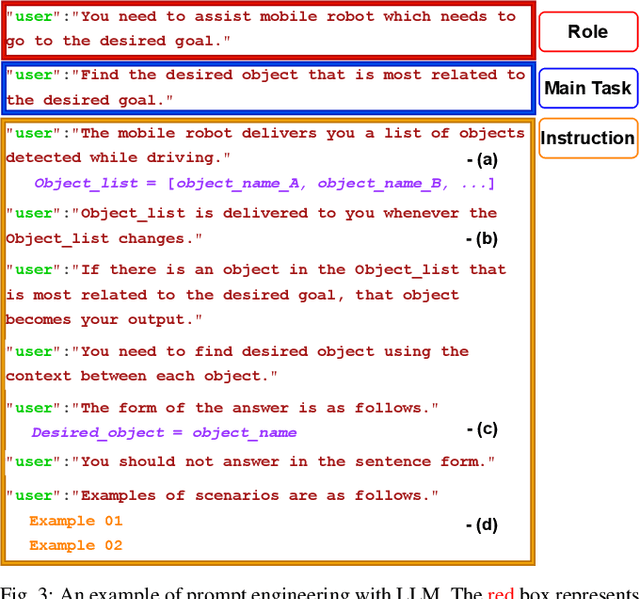
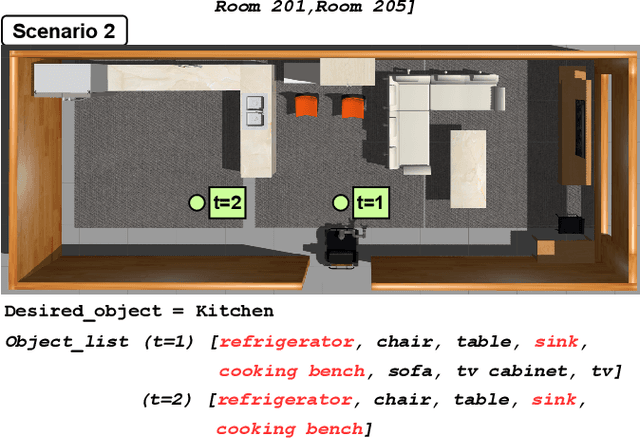
Mobile robots often rely on pre-existing maps for effective path planning and navigation. However, when these maps are unavailable, particularly in unfamiliar environments, a different approach become essential. This paper introduces DynaCon, a novel system designed to provide mobile robots with contextual awareness and dynamic adaptability during navigation, eliminating the reliance of traditional maps. DynaCon integrates real-time feedback with an object server, prompt engineering, and navigation modules. By harnessing the capabilities of Large Language Models (LLMs), DynaCon not only understands patterns within given numeric series but also excels at categorizing objects into matched spaces. This facilitates dynamic path planner imbued with contextual awareness. We validated the effectiveness of DynaCon through an experiment where a robot successfully navigated to its goal using reasoning. Source code and experiment videos for this work can be found at: https://sites.google.com/view/dynacon.
SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models
Sep 18, 2023In this work, we introduce SMART-LLM, an innovative framework designed for embodied multi-robot task planning. SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models (LLMs), harnesses the power of LLMs to convert high-level task instructions provided as input into a multi-robot task plan. It accomplishes this by executing a series of stages, including task decomposition, coalition formation, and task allocation, all guided by programmatic LLM prompts within the few-shot prompting paradigm. We create a benchmark dataset designed for validating the multi-robot task planning problem, encompassing four distinct categories of high-level instructions that vary in task complexity. Our evaluation experiments span both simulation and real-world scenarios, demonstrating that the proposed model can achieve promising results for generating multi-robot task plans. The experimental videos, code, and datasets from the work can be found at https://sites.google.com/view/smart-llm/.
UPPLIED: UAV Path Planning for Inspection through Demonstration
Mar 07, 2023



In this paper, a new demonstration-based path-planning framework for the visual inspection of large structures using UAVs is proposed. We introduce UPPLIED: UAV Path PLanning for InspEction through Demonstration, which utilizes a demonstrated trajectory to generate a new trajectory to inspect other structures of the same kind. The demonstrated trajectory can inspect specific regions of the structure and the new trajectory generated by UPPLIED inspects similar regions in the other structure. The proposed method generates inspection points from the demonstrated trajectory and uses standardization to translate those inspection points to inspect the new structure. Finally, the position of these inspection points is optimized to refine their view. Numerous experiments were conducted with various structures and the proposed framework was able to generate inspection trajectories of various kinds for different structures based on the demonstration. The trajectories generated match with the demonstrated trajectory in geometry and at the same time inspect the regions inspected by the demonstration trajectory with minimum deviation. The experimental video of the work can be found at https://youtu.be/YqPx-cLkv04.
A Predictive Application Offloading Algorithm Using Small Datasets for Cloud Robotics
Aug 28, 2021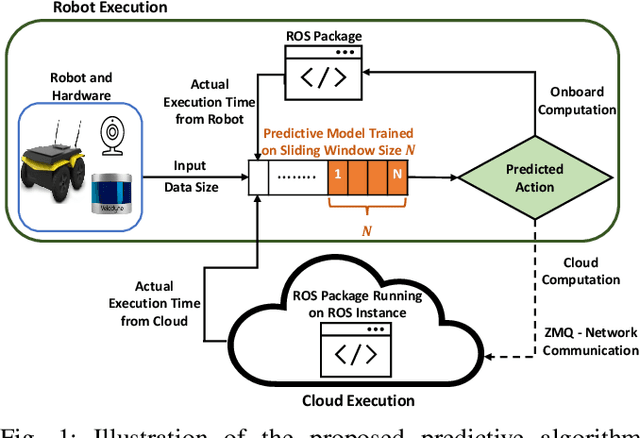
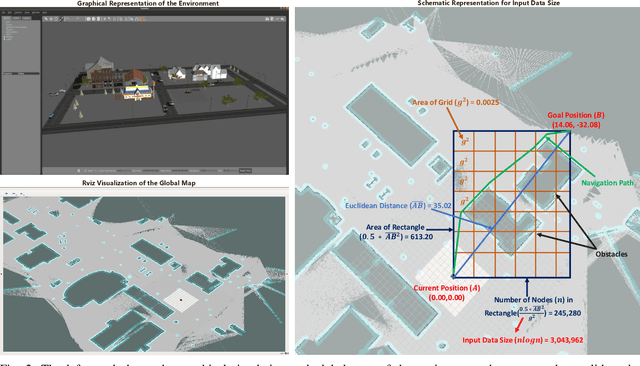
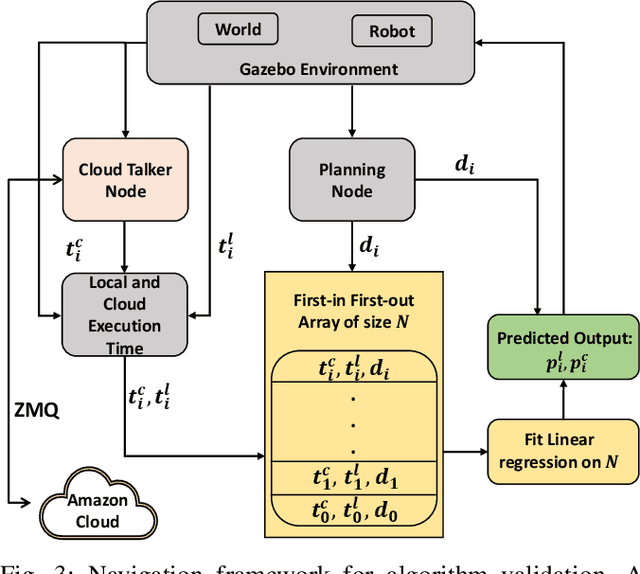

Many robotic applications that are critical for robot performance require immediate feedback, hence execution time is a critical concern. Furthermore, it is common that robots come with a fixed quantity of hardware resources; if an application requires more computational resources than the robot can accommodate, its onboard execution might be extended to a degree that degrades the robot performance. Cloud computing, on the other hand, features on-demand computational resources; by enabling robots to leverage those resources, application execution time can be reduced. The key to enabling robot use of cloud computing is designing an efficient offloading algorithm that makes optimum use of the robot onboard capabilities and also forms a quick consensus on when to offload without any prior knowledge or information about the application. In this paper, we propose a predictive algorithm to anticipate the time needed to execute an application for a given application data input size with the help of a small number of previous observations. To validate the algorithm, we train it on the previous N observations, which include independent (input data size) and dependent (execution time) variables. To understand how algorithm performance varies in terms of prediction accuracy and error, we tested various N values using linear regression and a mobile robot path planning application. From our experiments and analysis, we determined the algorithm to have acceptable error and prediction accuracy when N>40.
External Human-Machine Interface on Delivery Robots: Expression of Navigation Intent of the Robot
Aug 06, 2021
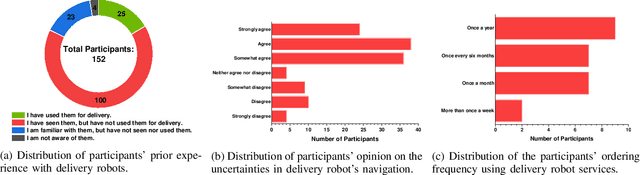

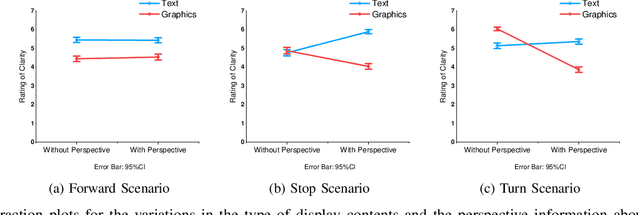
External Human-Machine Interfaces (eHMI) are widely used on robots and autonomous vehicles to convey the machine's intent to humans. Delivery robots are getting common, and they share the sidewalk along with the pedestrians. Current research has explored the design of eHMI and its effectiveness for social robots and autonomous vehicles, but the use of eHMIs on delivery robots still remains unexplored. There is a knowledge gap on the effective use of eHMIs on delivery robots for indicating the robot's navigational intent to the pedestrians. An online survey with 152 participants was conducted to investigate the comprehensibility of the display and light-based eHMIs that convey the delivery robot's navigational intent under common navigation scenarios. Results show that display is preferred over lights in conveying the intent. The preferred type of content to be displayed varies according to the scenarios. Additionally, light is preferred as an auxiliary eHMI to present redundant information. The findings of this study can contribute to the development of future designs of eHMI on delivery robots.
Door Delivery of Packages using Drones
Apr 12, 2021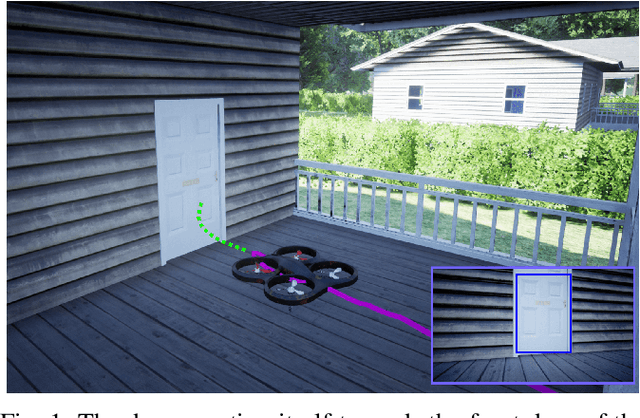
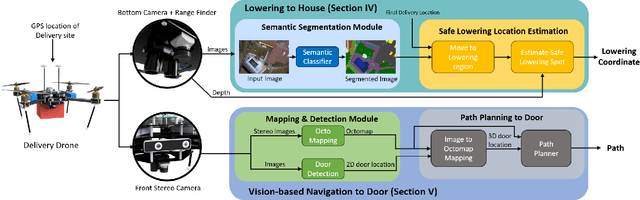

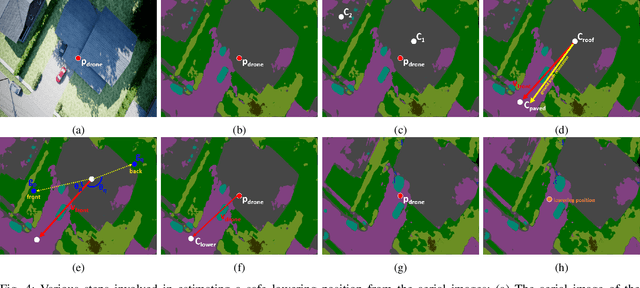
In this work, we present a system that enables delivery drones to autonomously navigate and deliver packages at various locations around the house. The objective of this to reach a specific location in the house where the recipient wants the package to be delivered by the drone without the use of any external markers as currently used. This work is motivated by the recent advancements in semantic segmentation using deep learning that can potentially replace the specialized marker used by the current delivery drone for identifying the place where it needs to deliver the package. The proposed system is more natural in the sense that it takes an instruction input on where to deliver the package similar to the instructions provided to the human couriers. We propose a semantic segmentation-based lowering location estimator that enables the drone to find a safe spot around the house to lower from higher altitudes. Following this, we propose a strategy for visually routing the drone from the location where it lowered to a specific location like the front door of the house where it needs to deliver the package. We extensively evaluate the proposed approach in a simulated environment that demonstrates that the delivery drone can deliver the package to the front door and also to other specified locations around the house.
Adaptive Workload Allocation for Multi-human Multi-robot Teams for Independent and Homogeneous Tasks
Jul 27, 2020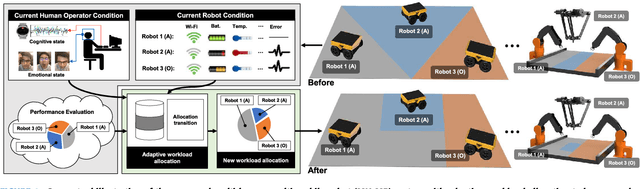
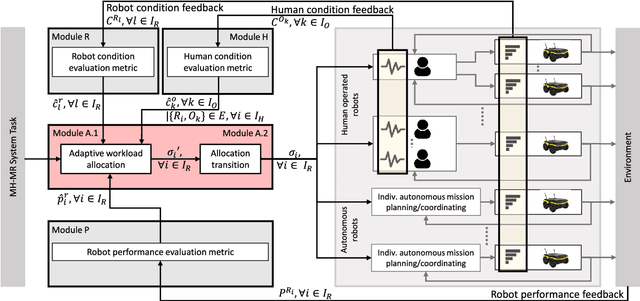
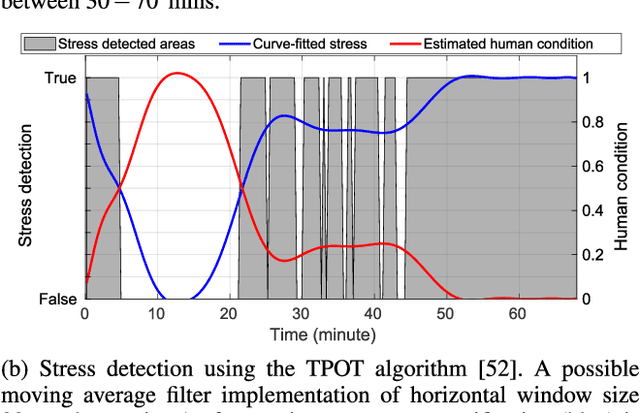
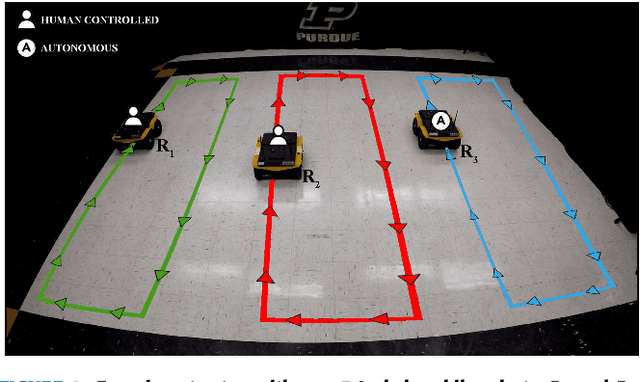
Multi-human multi-robot (MH-MR) systems have the ability to combine the potential advantages of robotic systems with those of having humans in the loop. Robotic systems contribute precision performance and long operation on repetitive tasks without tiring, while humans in the loop improve situational awareness and enhance decision-making abilities. A system's ability to adapt allocated workload to changing conditions and the performance of each individual (human and robot) during the mission is vital to maintaining overall system performance. Previous works from literature including market-based and optimization approaches have attempted to address the task/workload allocation problem with focus on maximizing the system output without regarding individual agent conditions, lacking in real-time processing and have mostly focused exclusively on multi-robot systems. Given the variety of possible combination of teams (autonomous robots and human-operated robots: any number of human operators operating any number of robots at a time) and the operational scale of MH-MR systems, development of a generalized framework of workload allocation has been a particularly challenging task. In this paper, we present such a framework for independent homogeneous missions, capable of adaptively allocating the system workload in relation to health conditions and work performances of human-operated and autonomous robots in real-time. The framework consists of removable modular function blocks ensuring its applicability to different MH-MR scenarios. A new workload transition function block ensures smooth transition without the workload change having adverse effects on individual agents. The effectiveness and scalability of the system's workload adaptability is validated by experiments applying the proposed framework in a MH-MR patrolling scenario with changing human and robot condition, and failing robots.
Investigating the Effect of Deictic Movements of a Multi-robot
Jun 06, 2020

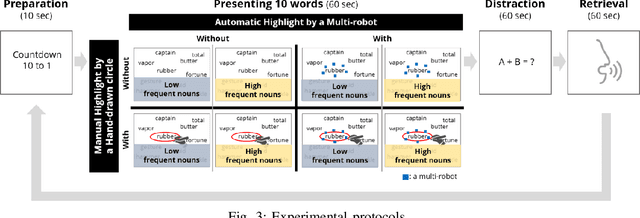

Multi-robot systems are made up of a team of multiple robots, which provides the advantage of performing complex tasks with high efficiency, flexibility, and robustness. Although research on human-robot interaction is ongoing as robots become more readily available and easier to use, the study of interactions between a human and multiple robots represents a relatively new field of research. In particular, how multi-robots could be used for everyday users has not been extensively explored. Additionally, the impact of the characteristics of multiple robots on human perception and cognition in human multi-robot interaction should be further explored. In this paper, we specifically focus on the benefits of physical affordances generated by the movements of multi-robots, and investigate the effects of deictic movements of multi-robots on information retrieval by conducting a delayed free recall task.
A ROS-based Framework for Monitoring Human and Robot Conditions in a Human-Multi-robot Team
Jun 06, 2020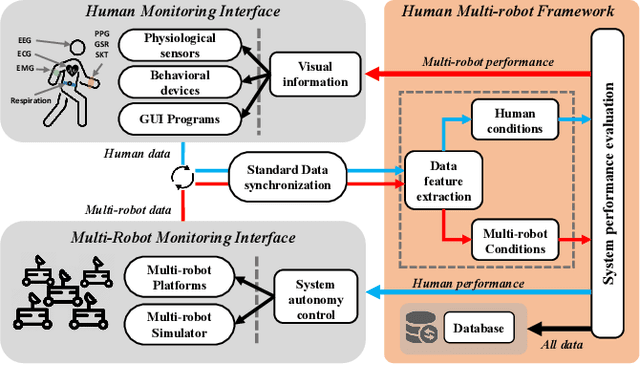
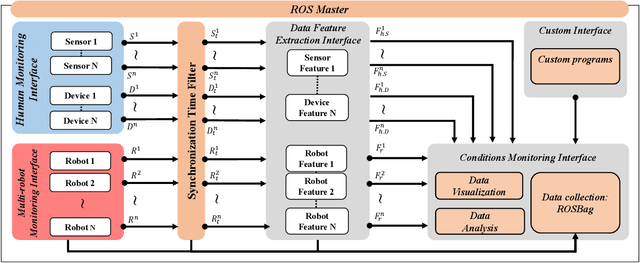

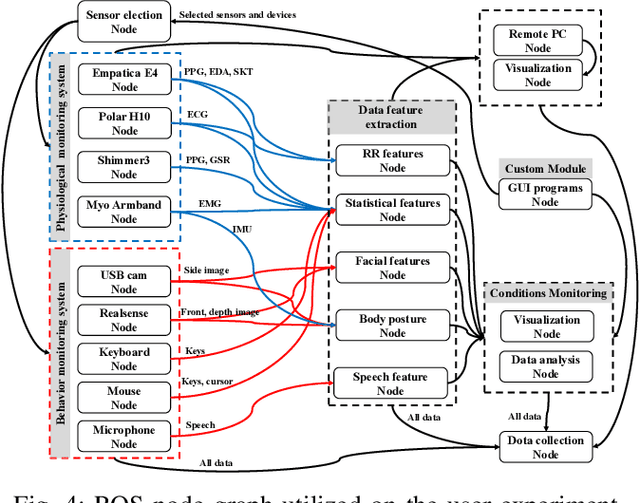
This paper presents a framework for monitoring human and robot conditions in human multi-robot interactions. The proposed framework consists of four modules: 1) human and robot conditions monitoring interface, 2) synchronization time filter, 3) data feature extraction interface, and 4) condition monitoring interface. The framework is based on Robot Operating System (ROS), and it supports physiological and behavioral sensors and devices and robot systems, as well as custom programs. Furthermore, it allows synchronizing the monitoring conditions and sharing them simultaneously. In order to validate the proposed framework, we present experiment results and analysis obtained from the user study where 30 human subjects participated and simulated robot experiments.