 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREBEL: Rule-based and Experience-enhanced Learning with LLMs for Initial Task Allocation in Multi-Human Multi-Robot Teams
Paper and Code
Sep 24, 2024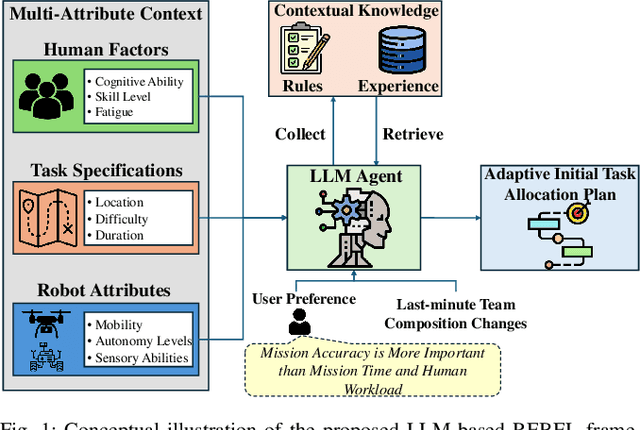
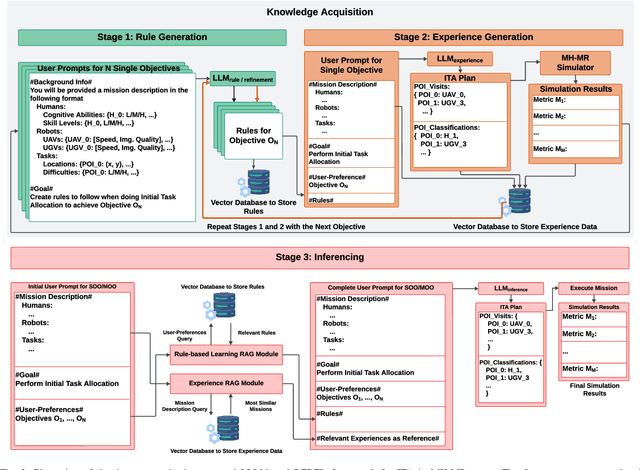
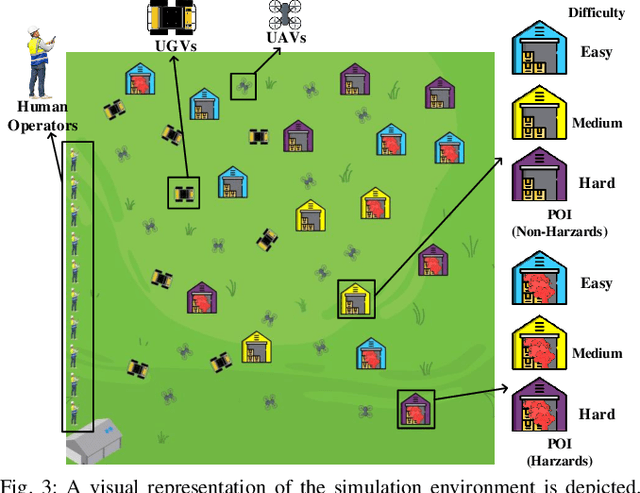
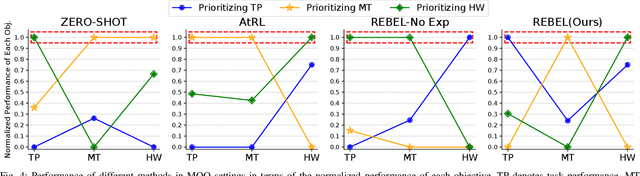
Multi-human multi-robot teams combine the complementary strengths of humans and robots to tackle complex tasks across diverse applications. However, the inherent heterogeneity of these teams presents significant challenges in initial task allocation (ITA), which involves assigning the most suitable tasks to each team member based on their individual capabilities before task execution. While current learning-based methods have shown promising results, they are often computationally expensive to train, and lack the flexibility to incorporate user preferences in multi-objective optimization and adapt to last-minute changes in real-world dynamic environments. To address these issues, we propose REBEL, an LLM-based ITA framework that integrates rule-based and experience-enhanced learning. By leveraging Retrieval-Augmented Generation, REBEL dynamically retrieves relevant rules and past experiences, enhancing reasoning efficiency. Additionally, REBEL can complement pre-trained RL-based ITA policies, improving situational awareness and overall team performance. Extensive experiments validate the effectiveness of our approach across various settings. More details are available at https://sites.google.com/view/ita-rebel .