 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafePlan: Leveraging Formal Logic and Chain-of-Thought Reasoning for Enhanced Safety in LLM-based Robotic Task Planning
Mar 10, 2025



Robotics researchers increasingly leverage large language models (LLM) in robotics systems, using them as interfaces to receive task commands, generate task plans, form team coalitions, and allocate tasks among multi-robot and human agents. However, despite their benefits, the growing adoption of LLM in robotics has raised several safety concerns, particularly regarding executing malicious or unsafe natural language prompts. In addition, ensuring that task plans, team formation, and task allocation outputs from LLMs are adequately examined, refined, or rejected is crucial for maintaining system integrity. In this paper, we introduce SafePlan, a multi-component framework that combines formal logic and chain-of-thought reasoners for enhancing the safety of LLM-based robotics systems. Using the components of SafePlan, including Prompt Sanity COT Reasoner and Invariant, Precondition, and Postcondition COT reasoners, we examined the safety of natural language task prompts, task plans, and task allocation outputs generated by LLM-based robotic systems as means of investigating and enhancing system safety profile. Our results show that SafePlan outperforms baseline models by leading to 90.5% reduction in harmful task prompt acceptance while still maintaining reasonable acceptance of safe tasks.
Question-Aware Gaussian Experts for Audio-Visual Question Answering
Mar 07, 2025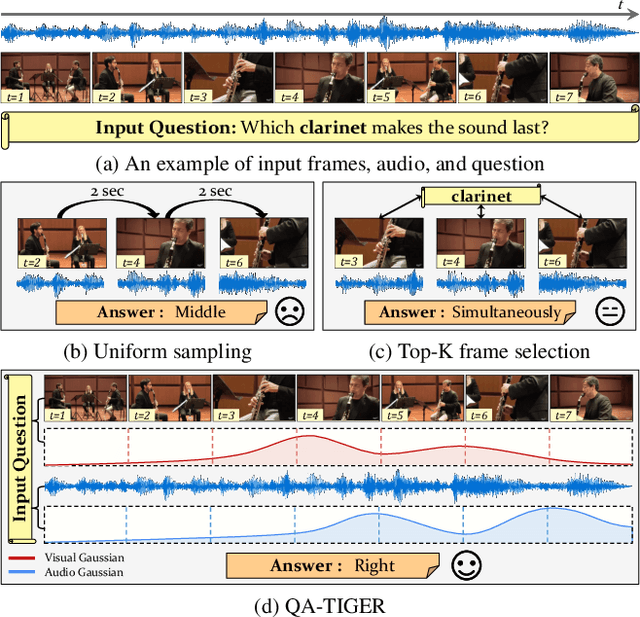

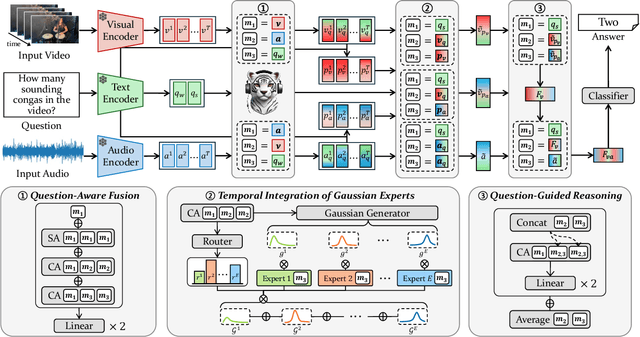
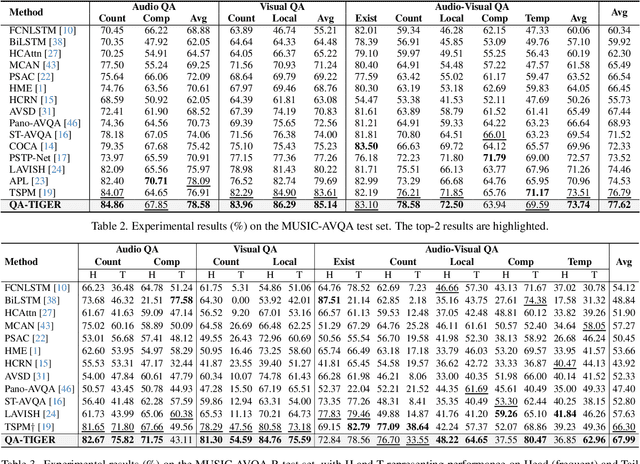
Audio-Visual Question Answering (AVQA) requires not only question-based multimodal reasoning but also precise temporal grounding to capture subtle dynamics for accurate prediction. However, existing methods mainly use question information implicitly, limiting focus on question-specific details. Furthermore, most studies rely on uniform frame sampling, which can miss key question-relevant frames. Although recent Top-K frame selection methods aim to address this, their discrete nature still overlooks fine-grained temporal details. This paper proposes QA-TIGER, a novel framework that explicitly incorporates question information and models continuous temporal dynamics. Our key idea is to use Gaussian-based modeling to adaptively focus on both consecutive and non-consecutive frames based on the question, while explicitly injecting question information and applying progressive refinement. We leverage a Mixture of Experts (MoE) to flexibly implement multiple Gaussian models, activating temporal experts specifically tailored to the question. Extensive experiments on multiple AVQA benchmarks show that QA-TIGER consistently achieves state-of-the-art performance. Code is available at https://aim-skku.github.io/QA-TIGER/
Personalization in Human-Robot Interaction through Preference-based Action Representation Learning
Sep 20, 2024



Preference-based reinforcement learning (PbRL) has shown significant promise for personalization in human-robot interaction (HRI) by explicitly integrating human preferences into the robot learning process. However, existing practices often require training a personalized robot policy from scratch, resulting in inefficient use of human feedback. In this paper, we propose preference-based action representation learning (PbARL), an efficient fine-tuning method that decouples common task structure from preference by leveraging pre-trained robot policies. Instead of directly fine-tuning the pre-trained policy with human preference, PbARL uses it as a reference for an action representation learning task that maximizes the mutual information between the pre-trained source domain and the target user preference-aligned domain. This approach allows the robot to personalize its behaviors while preserving original task performance and eliminates the need for extensive prior information from the source domain, thereby enhancing efficiency and practicality in real-world HRI scenarios. Empirical results on the Assistive Gym benchmark and a real-world user study (N=8) demonstrate the benefits of our method compared to state-of-the-art approaches.
PrefMMT: Modeling Human Preferences in Preference-based Reinforcement Learning with Multimodal Transformers
Sep 20, 2024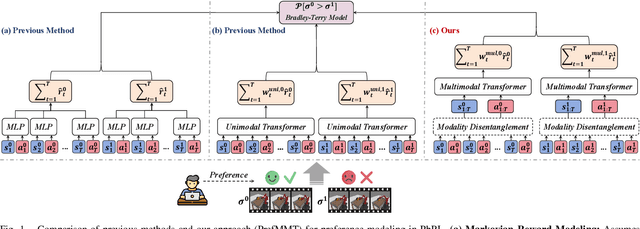
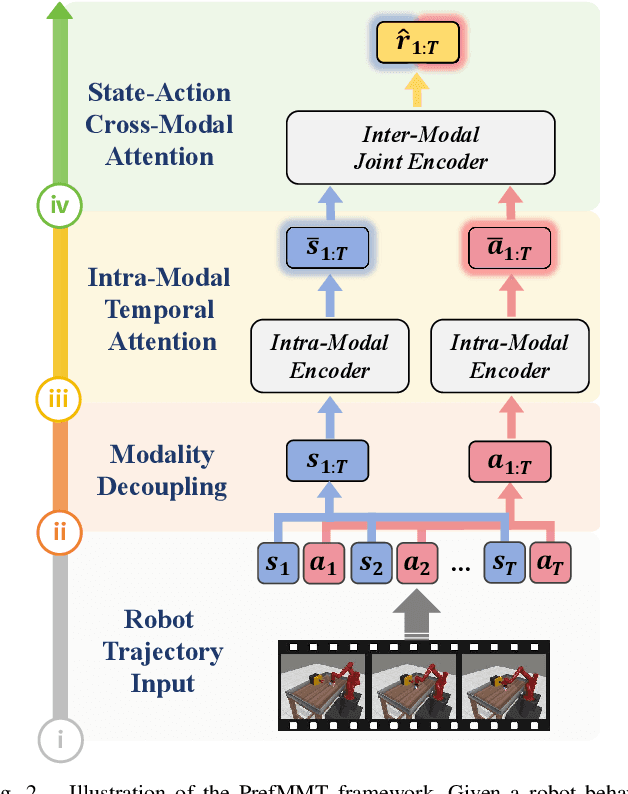
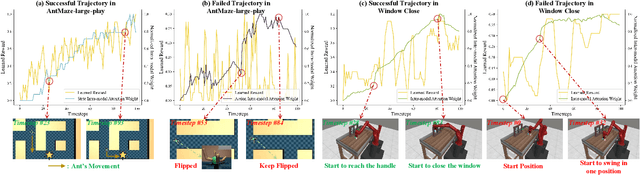
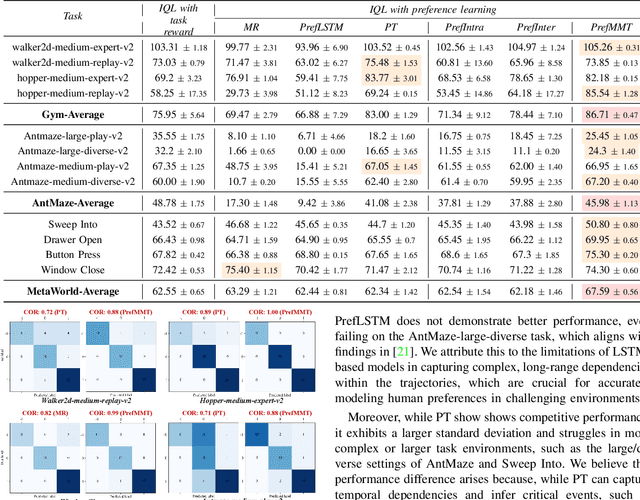
Preference-based reinforcement learning (PbRL) shows promise in aligning robot behaviors with human preferences, but its success depends heavily on the accurate modeling of human preferences through reward models. Most methods adopt Markovian assumptions for preference modeling (PM), which overlook the temporal dependencies within robot behavior trajectories that impact human evaluations. While recent works have utilized sequence modeling to mitigate this by learning sequential non-Markovian rewards, they ignore the multimodal nature of robot trajectories, which consist of elements from two distinctive modalities: state and action. As a result, they often struggle to capture the complex interplay between these modalities that significantly shapes human preferences. In this paper, we propose a multimodal sequence modeling approach for PM by disentangling state and action modalities. We introduce a multimodal transformer network, named PrefMMT, which hierarchically leverages intra-modal temporal dependencies and inter-modal state-action interactions to capture complex preference patterns. We demonstrate that PrefMMT consistently outperforms state-of-the-art PM baselines on locomotion tasks from the D4RL benchmark and manipulation tasks from the Meta-World benchmark.