 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefMMT: Modeling Human Preferences in Preference-based Reinforcement Learning with Multimodal Transformers
Paper and Code
Sep 20, 2024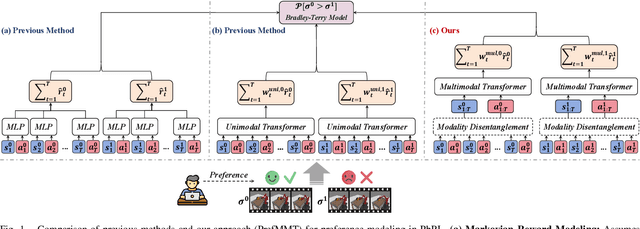
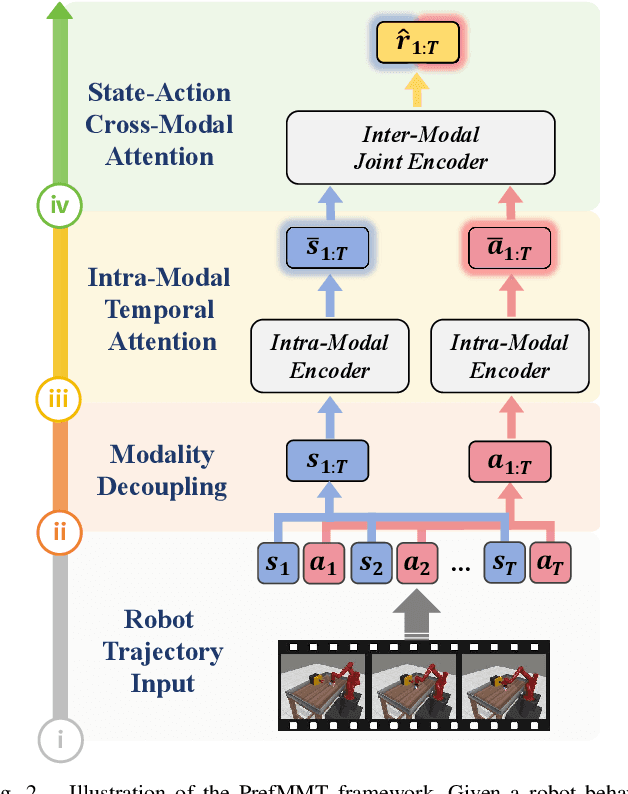
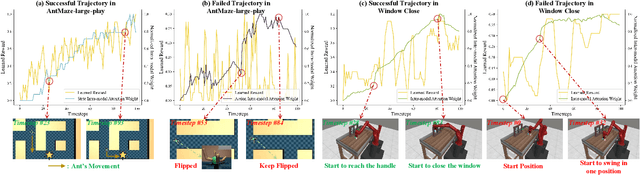
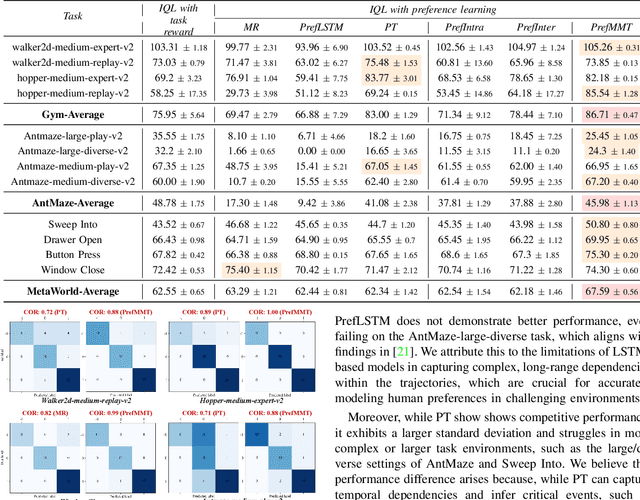
Preference-based reinforcement learning (PbRL) shows promise in aligning robot behaviors with human preferences, but its success depends heavily on the accurate modeling of human preferences through reward models. Most methods adopt Markovian assumptions for preference modeling (PM), which overlook the temporal dependencies within robot behavior trajectories that impact human evaluations. While recent works have utilized sequence modeling to mitigate this by learning sequential non-Markovian rewards, they ignore the multimodal nature of robot trajectories, which consist of elements from two distinctive modalities: state and action. As a result, they often struggle to capture the complex interplay between these modalities that significantly shapes human preferences. In this paper, we propose a multimodal sequence modeling approach for PM by disentangling state and action modalities. We introduce a multimodal transformer network, named PrefMMT, which hierarchically leverages intra-modal temporal dependencies and inter-modal state-action interactions to capture complex preference patterns. We demonstrate that PrefMMT consistently outperforms state-of-the-art PM baselines on locomotion tasks from the D4RL benchmark and manipulation tasks from the Meta-World benchmark.